 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Expert-Guided Hybrid Mixture-of-Experts for Medical AI: Integrating Data-Driven Learning with Clinical Priors
Jan 25, 2026Mixture-of-Experts (MoE) models increase representational capacity with modest computational cost, but their effectiveness in specialized domains such as medicine is limited by small datasets. In contrast, clinical practice offers rich expert knowledge, such as physician gaze patterns and diagnostic heuristics, that models cannot reliably learn from limited data. Combining data-driven experts, which capture novel patterns, with domain-expert-guided experts, which encode accumulated clinical insights, provides complementary strengths for robust and clinically meaningful learning. To this end, we propose Domain-Knowledge-Guided Hybrid MoE (DKGH-MoE), a plug-and-play and interpretable module that unifies data-driven learning with domain expertise. DKGH-MoE integrates a data-driven MoE to extract novel features from raw imaging data, and a domain-expert-guided MoE incorporates clinical priors, specifically clinician eye-gaze cues, to emphasize regions of high diagnostic relevance. By integrating domain expert insights with data-driven features, DKGH-MoE improves both performance and interpretability.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
Distributed satellite information networks: Architecture, enabling technologies, and trends
Dec 17, 2024



Driven by the vision of ubiquitous connectivity and wireless intelligence, the evolution of ultra-dense constellation-based satellite-integrated Internet is underway, now taking preliminary shape. Nevertheless, the entrenched institutional silos and limited, nonrenewable heterogeneous network resources leave current satellite systems struggling to accommodate the escalating demands of next-generation intelligent applications. In this context, the distributed satellite information networks (DSIN), exemplified by the cohesive clustered satellites system, have emerged as an innovative architecture, bridging information gaps across diverse satellite systems, such as communication, navigation, and remote sensing, and establishing a unified, open information network paradigm to support resilient space information services. This survey first provides a profound discussion about innovative network architectures of DSIN, encompassing distributed regenerative satellite network architecture, distributed satellite computing network architecture, and reconfigurable satellite formation flying, to enable flexible and scalable communication, computing and control. The DSIN faces challenges from network heterogeneity, unpredictable channel dynamics, sparse resources, and decentralized collaboration frameworks. To address these issues, a series of enabling technologies is identified, including channel modeling and estimation, cloud-native distributed MIMO cooperation, grant-free massive access, network routing, and the proper combination of all these diversity techniques. Furthermore, to heighten the overall resource efficiency, the cross-layer optimization techniques are further developed to meet upper-layer deterministic, adaptive and secure information services requirements. In addition, emerging research directions and new opportunities are highlighted on the way to achieving the DSIN vision.
Frequency Diverse Array-enabled RIS-aided Integrated Sensing and Communication
Oct 01, 2024



Integrated sensing and communication (ISAC) has been envisioned as a prospective technology to enable ubiquitous sensing and communications in next-generation wireless networks. In contrast to existing works on reconfigurable intelligent surface (RIS) aided ISAC systems using conventional phased arrays (PAs), this paper investigates a frequency diverse array (FDA)-enabled RIS-aided ISAC system, where the FDA aims to provide a distance-angle-dependent beampattern to effectively suppress the clutter, and RIS is employed to establish high-quality links between the BS and users/target. We aim to maximize sum rate by jointly optimizing the BS transmit beamforming vectors, the covariance matrix of the dedicated radar signal, the RIS phase shift matrix, the FDA frequency offsets and the radar receive equalizer, while guaranteeing the required signal-to-clutter-plus-noise ratio (SCNR) of the radar echo signal. To tackle this challenging problem, we first theoretically prove that the dedicated radar signal is unnecessary for enhancing target sensing performance, based on which the original problem is much simplified. Then, we turn our attention to the single-user single-target (SUST) scenario to demonstrate that the FDA-RIS-aided ISAC system always achieves a higher SCNR than its PA-RIS-aided counterpart. Moreover, it is revealed that the SCNR increment exhibits linear growth with the BS transmit power and the number of BS receive antennas. In order to effectively solve this simplified problem, we leverage the fractional programming (FP) theory and subsequently develop an efficient alternating optimization (AO) algorithm based on symmetric alternating direction method of multipliers (SADMM) and successive convex approximation (SCA) techniques. Numerical results demonstrate the superior performance of our proposed algorithm in terms of sum rate and radar SCNR.
Near-Field Positioning and Attitude Sensing Based on Electromagnetic Propagation Modeling
Oct 26, 2023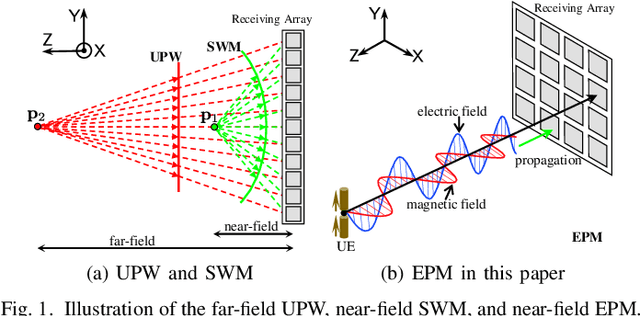
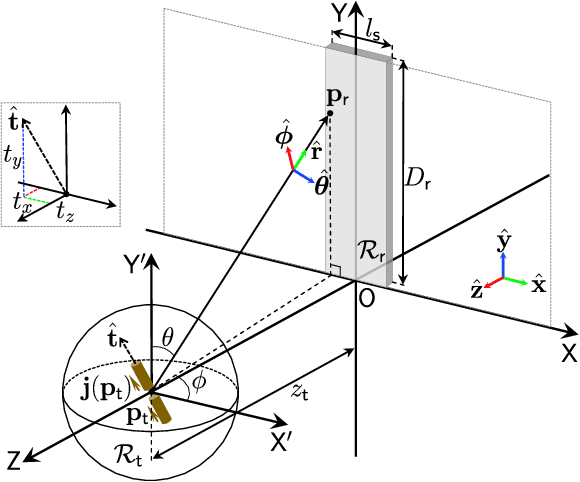
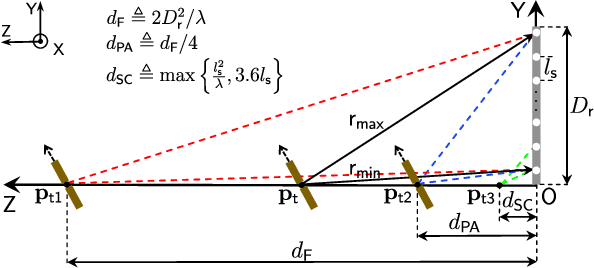
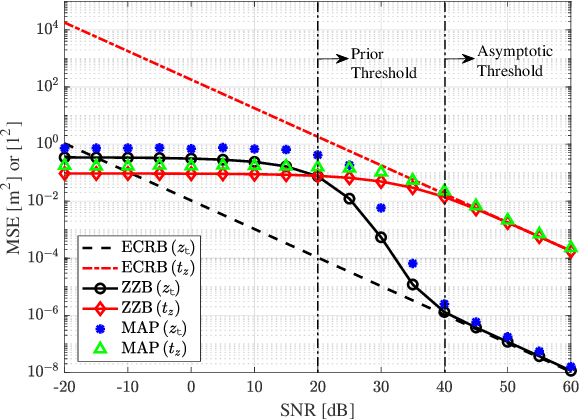
Positioning and sensing over wireless networks are imperative for many emerging applications. However, traditional wireless channel models cannot be used for sensing the attitude of the user equipment (UE), since they over-simplify the UE as a point target. In this paper, a comprehensive electromagnetic propagation modeling (EPM) based on electromagnetic theory is developed to precisely model the near-field channel. For the noise-free case, the EPM model establishes the non-linear functional dependence of observed signals on both the position and attitude of the UE. To address the difficulty in the non-linear coupling, we first propose to divide the distance domain into three regions, separated by the defined Phase ambiguity distance and Spacing constraint distance. Then, for each region, we obtain the closed-form solutions for joint position and attitude estimation with low complexity. Next, to investigate the impact of random noise on the joint estimation performance, the Ziv-Zakai bound (ZZB) is derived to yield useful insights. The expected Cram\'er-Rao bound (ECRB) is further provided to obtain the simplified closed-form expressions for the performance lower bounds. Our numerical results demonstrate that the derived ZZB can provide accurate predictions of the performance of estimators in all signal-to-noise ratio (SNR) regimes. More importantly, we achieve the millimeter-level accuracy in position estimation and attain the 0.1-level accuracy in attitude estimation.
Dual-Functional MIMO Beamforming Optimization for RIS-Aided Integrated Sensing and Communication
Jul 17, 2023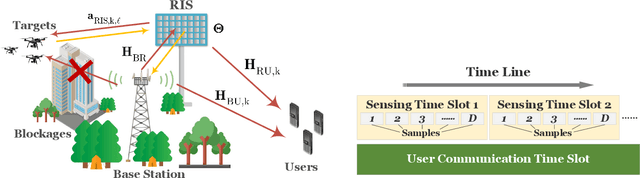
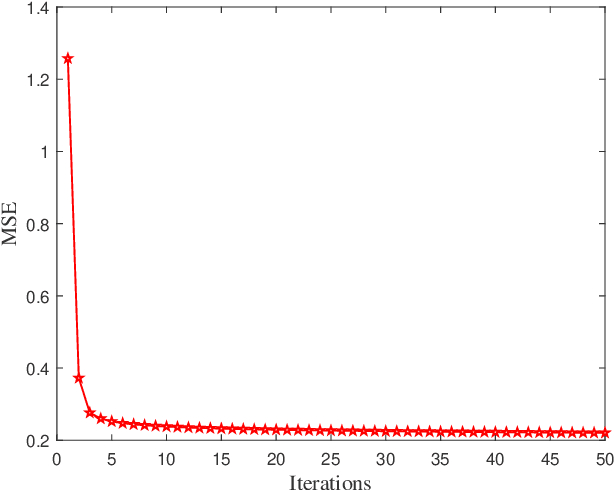
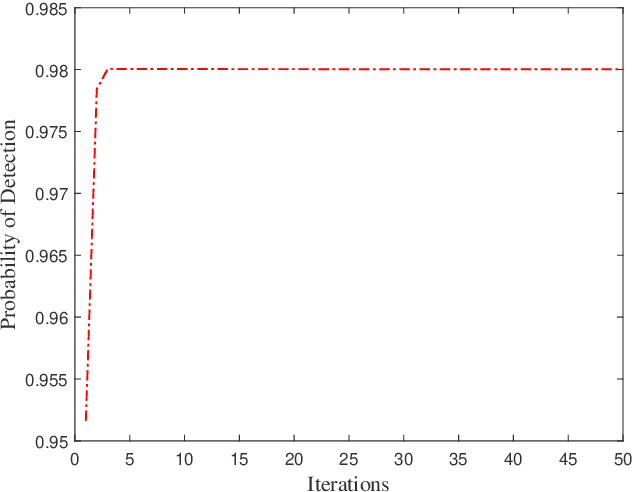
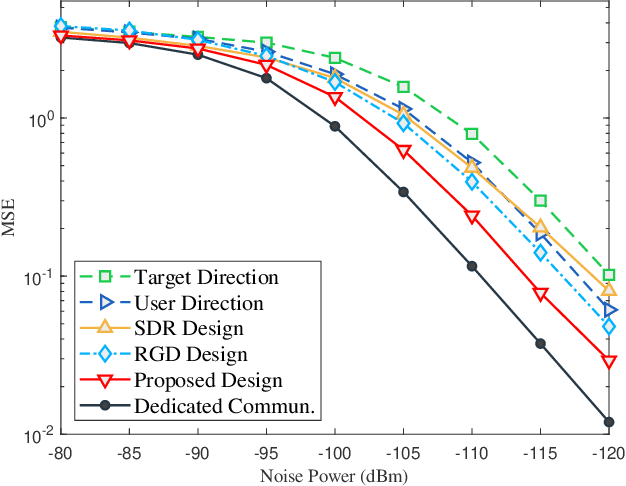
Aiming at providing wireless communication systems with environment-perceptive capacity, emerging integrated sensing and communication (ISAC) technologies face multiple difficulties, especially in balancing the performance trade-off between the communication and radar functions. In this paper, we introduce a reconfigurable intelligent surface (RIS) to assist both data transmission and target detection in a dual-functional ISAC system. To formulate a general optimization framework, diverse communication performance metrics have been taken into account including famous capacity maximization and mean-squared error (MSE) minimization. Whereas the target detection process is modeled as a general likelihood ratio test (GLRT) due to the practical limitations, and the monotonicity of the corresponding detection probability is proved. For the single-user and single-target (SUST) scenario, the minimum transmit power of the ISAC transceiver has been revealed. By exploiting the optimal conditions of the BS design, we validate that the BS is able to realize the maximum power allocation scheme and derive the optimal BS precoder in a semi-closed form. Moreover, an alternating direction method of multipliers (ADMM) based RIS design is proposed to address the optimization of unit-modulus RIS phase shifts. For the sake of further enhancing computational efficiency, we also develop a low-complexity RIS design based on Riemannian gradient descent. Furthermore, the ISAC transceiver design for the multiple-users and multiple-targets (MUMT) scenario is also investigated, where a zero-forcing (ZF) radar receiver is adopted to cancel the interferences. Then optimal BS precoder is derived under the maximum power allocation scheme, and the RIS phase shifts can be optimized by extending the proposed ADMM-based RIS design. Numerical simulation results verify the performance of our proposed transceiver designs.
End-to-end Recording Device Identification Based on Deep Representation Learning
Dec 05, 2022



Deep learning techniques have achieved specific results in recording device source identification. The recording device source features include spatial information and certain temporal information. However, most recording device source identification methods based on deep learning only use spatial representation learning from recording device source features, which cannot make full use of recording device source information. Therefore, in this paper, to fully explore the spatial information and temporal information of recording device source, we propose a new method for recording device source identification based on the fusion of spatial feature information and temporal feature information by using an end-to-end framework. From a feature perspective, we designed two kinds of networks to extract recording device source spatial and temporal information. Afterward, we use the attention mechanism to adaptively assign the weight of spatial information and temporal information to obtain fusion features. From a model perspective, our model uses an end-to-end framework to learn the deep representation from spatial feature and temporal feature and train using deep and shallow loss to joint optimize our network. This method is compared with our previous work and baseline system. The results show that the proposed method is better than our previous work and baseline system under general conditions.
JSRNN: Joint Sampling and Reconstruction Neural Networks for High Quality Image Compressed Sensing
Nov 11, 2022Most Deep Learning (DL) based Compressed Sensing (DCS) algorithms adopt a single neural network for signal reconstruction, and fail to jointly consider the influences of the sampling operation for reconstruction. In this paper, we propose unified framework, which jointly considers the sampling and reconstruction process for image compressive sensing based on well-designed cascade neural networks. Two sub-networks, which are the sampling sub-network and the reconstruction sub-network, are included in the proposed framework. In the sampling sub-network, an adaptive full connected layer instead of the traditional random matrix is used to mimic the sampling operator. In the reconstruction sub-network, a cascade network combining stacked denoising autoencoder (SDA) and convolutional neural network (CNN) is designed to reconstruct signals. The SDA is used to solve the signal mapping problem and the signals are initially reconstructed. Furthermore, CNN is used to fully recover the structure and texture features of the image to obtain better reconstruction performance. Extensive experiments show that this framework outperforms many other state-of-the-art methods, especially at low sampling rates.
Audio Tampering Detection Based on Shallow and Deep Feature Representation Learning
Oct 19, 2022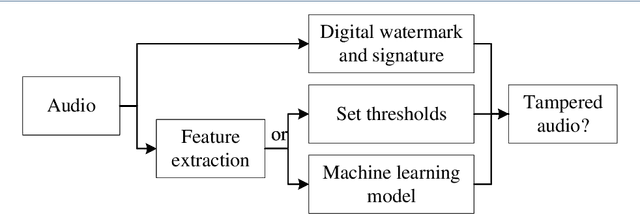

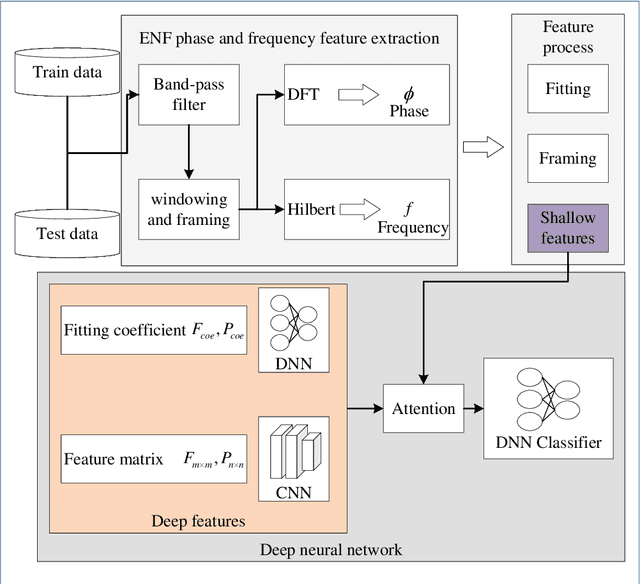

Digital audio tampering detection can be used to verify the authenticity of digital audio. However, most current methods use standard electronic network frequency (ENF) databases for visual comparison analysis of ENF continuity of digital audio or perform feature extraction for classification by machine learning methods. ENF databases are usually tricky to obtain, visual methods have weak feature representation, and machine learning methods have more information loss in features, resulting in low detection accuracy. This paper proposes a fusion method of shallow and deep features to fully use ENF information by exploiting the complementary nature of features at different levels to more accurately describe the changes in inconsistency produced by tampering operations to raw digital audio. The method achieves 97.03% accuracy on three classic databases: Carioca 1, Carioca 2, and New Spanish. In addition, we have achieved an accuracy of 88.31% on the newly constructed database GAUDI-DI. Experimental results show that the proposed method is superior to the state-of-the-art method.
Spatio-Temporal Representation Learning Enhanced Source Cell-phone Recognition from Speech Recordings
Aug 25, 2022
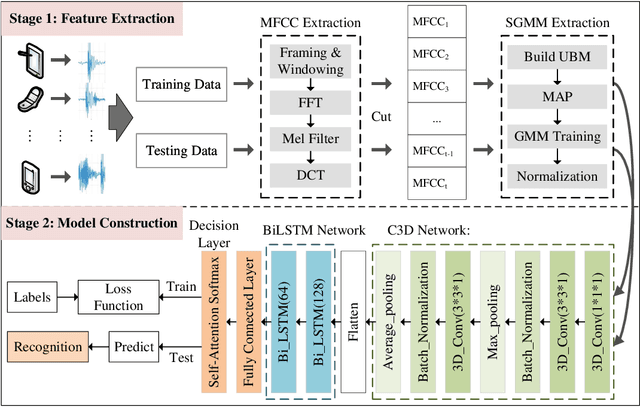
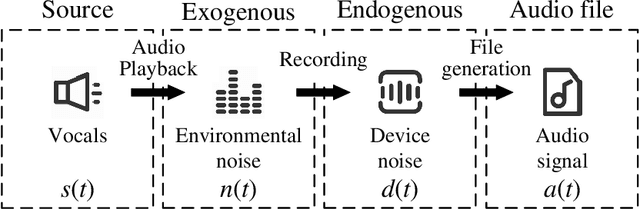

The existing source cell-phone recognition method lacks the long-term feature characterization of the source device, resulting in inaccurate representation of the source cell-phone related features which leads to insufficient recognition accuracy. In this paper, we propose a source cell-phone recognition method based on spatio-temporal representation learning, which includes two main parts: extraction of sequential Gaussian mean matrix features and construction of a recognition model based on spatio-temporal representation learning. In the feature extraction part, based on the analysis of time-series representation of recording source signals, we extract sequential Gaussian mean matrix with long-term and short-term representation ability by using the sensitivity of Gaussian mixture model to data distribution. In the model construction part, we design a structured spatio-temporal representation learning network C3D-BiLSTM to fully characterize the spatio-temporal information, combine 3D convolutional network and bidirectional long short-term memory network for short-term spectral information and long-time fluctuation information representation learning, and achieve accurate recognition of cell-phones by fusing spatio-temporal feature information of recording source signals. The method achieves an average accuracy of 99.03% for the closed-set recognition of 45 cell-phones under the CCNU\_Mobile dataset, and 98.18% in small sample size experiments, with recognition performance better than the existing state-of-the-art methods. The experimental results show that the method exhibits excellent recognition performance in multi-class cell-phones recognition.