 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Compressed Sensing with Multi-scale Dilated Convolutional Neural Network
Sep 28, 2022
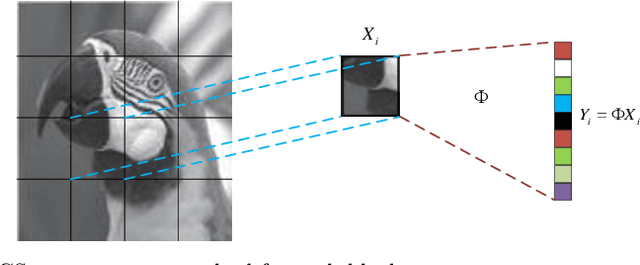
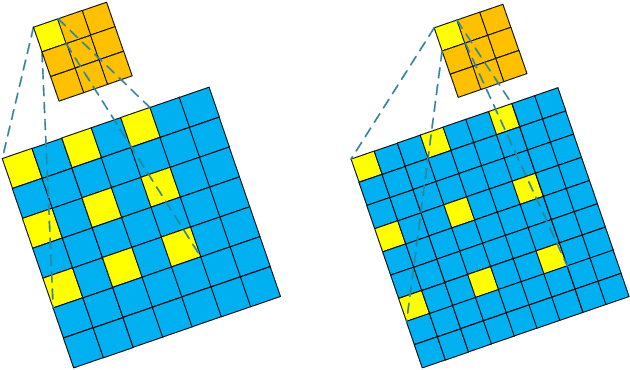
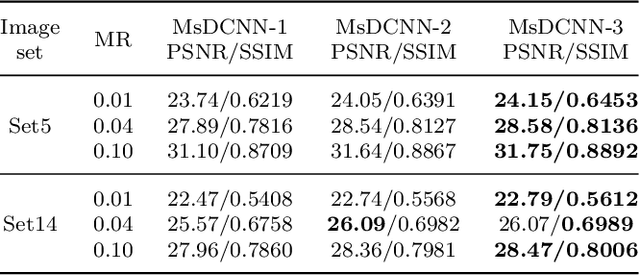
Deep Learning (DL) based Compressed Sensing (CS) has been applied for better performance of image reconstruction than traditional CS methods. However, most existing DL methods utilize the block-by-block measurement and each measurement block is restored separately, which introduces harmful blocking effects for reconstruction. Furthermore, the neuronal receptive fields of those methods are designed to be the same size in each layer, which can only collect single-scale spatial information and has a negative impact on the reconstruction process. This paper proposes a novel framework named Multi-scale Dilated Convolution Neural Network (MsDCNN) for CS measurement and reconstruction. During the measurement period, we directly obtain all measurements from a trained measurement network, which employs fully convolutional structures and is jointly trained with the reconstruction network from the input image. It needn't be cut into blocks, which effectively avoids the block effect. During the reconstruction period, we propose the Multi-scale Feature Extraction (MFE) architecture to imitate the human visual system to capture multi-scale features from the same feature map, which enhances the image feature extraction ability of the framework and improves the performance of image reconstruction. In the MFE, there are multiple parallel convolution channels to obtain multi-scale feature information. Then the multi-scale features information is fused and the original image is reconstructed with high quality. Our experimental results show that the proposed method performs favorably against the state-of-the-art methods in terms of PSNR and SSIM.
Digital Audio Tampering Detection Based on ENF Spatio-temporal Features Representation Learning
Aug 25, 2022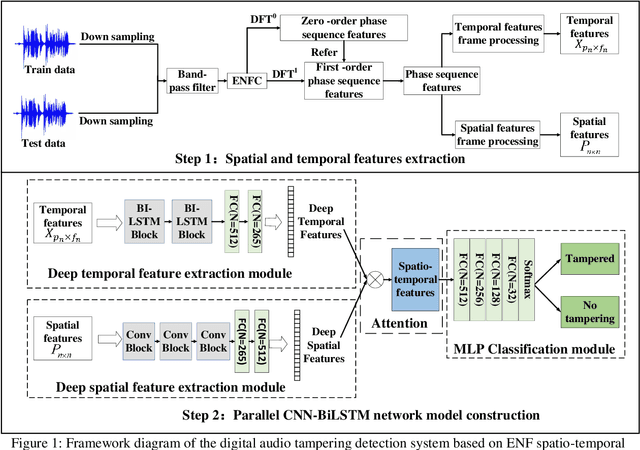
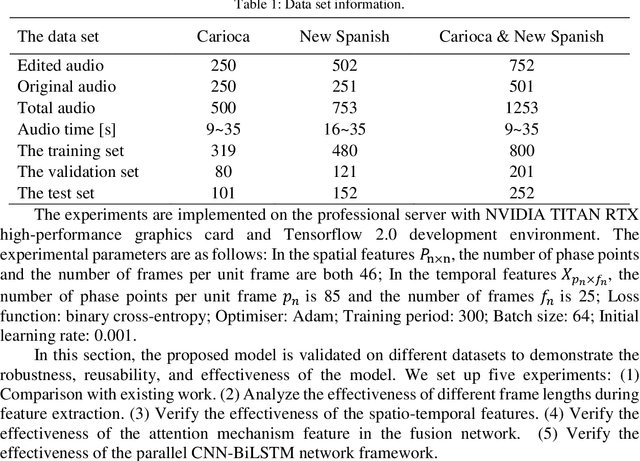
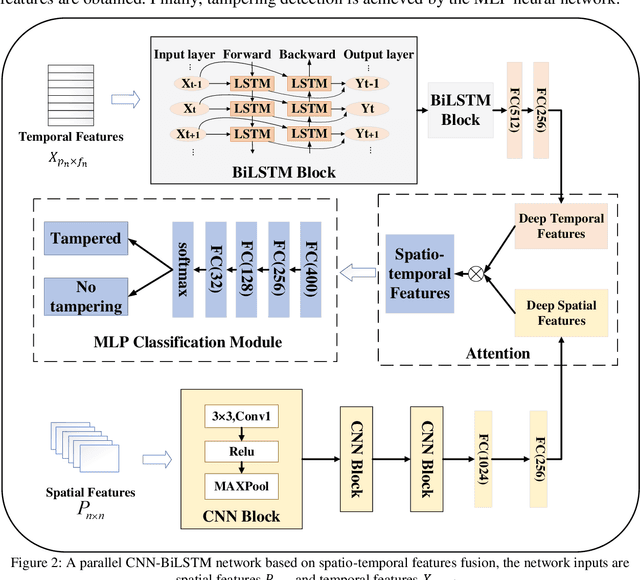
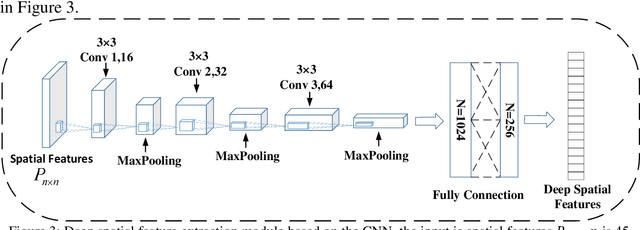
Most digital audio tampering detection methods based on electrical network frequency (ENF) only utilize the static spatial information of ENF, ignoring the variation of ENF in time series, which limit the ability of ENF feature representation and reduce the accuracy of tampering detection. This paper proposes a new method for digital audio tampering detection based on ENF spatio-temporal features representation learning. A parallel spatio-temporal network model is constructed using CNN and BiLSTM, which deeply extracts ENF spatial feature information and ENF temporal feature information to enhance the feature representation capability to improve the tampering detection accuracy. In order to extract the spatial and temporal features of the ENF, this paper firstly uses digital audio high-precision Discrete Fourier Transform analysis to extract the phase sequences of the ENF. The unequal phase series is divided into frames by adaptive frame shifting to obtain feature matrices of the same size to represent the spatial features of the ENF. At the same time, the phase sequences are divided into frames based on ENF time changes information to represent the temporal features of the ENF. Then deep spatial and temporal features are further extracted using CNN and BiLSTM respectively, and an attention mechanism is used to adaptively assign weights to the deep spatial and temporal features to obtain spatio-temporal features with stronger representation capability. Finally, the deep neural network is used to determine whether the audio has been tampered with. The experimental results show that the proposed method improves the accuracy by 2.12%-7.12% compared with state-of-the-art methods under the public database Carioca, New Spanish.
Spatio-Temporal Representation Learning Enhanced Source Cell-phone Recognition from Speech Recordings
Aug 25, 2022
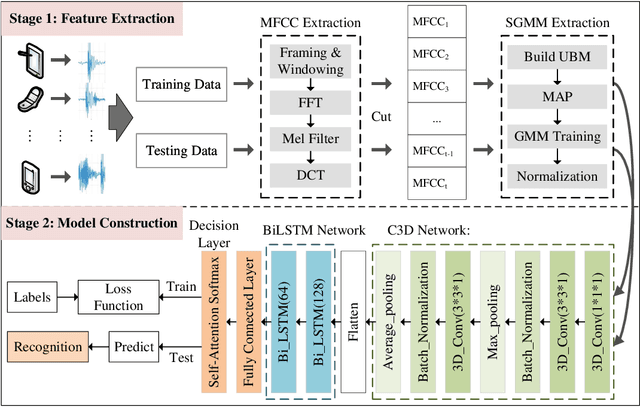

The existing source cell-phone recognition method lacks the long-term feature characterization of the source device, resulting in inaccurate representation of the source cell-phone related features which leads to insufficient recognition accuracy. In this paper, we propose a source cell-phone recognition method based on spatio-temporal representation learning, which includes two main parts: extraction of sequential Gaussian mean matrix features and construction of a recognition model based on spatio-temporal representation learning. In the feature extraction part, based on the analysis of time-series representation of recording source signals, we extract sequential Gaussian mean matrix with long-term and short-term representation ability by using the sensitivity of Gaussian mixture model to data distribution. In the model construction part, we design a structured spatio-temporal representation learning network C3D-BiLSTM to fully characterize the spatio-temporal information, combine 3D convolutional network and bidirectional long short-term memory network for short-term spectral information and long-time fluctuation information representation learning, and achieve accurate recognition of cell-phones by fusing spatio-temporal feature information of recording source signals. The method achieves an average accuracy of 99.03% for the closed-set recognition of 45 cell-phones under the CCNU\_Mobile dataset, and 98.18% in small sample size experiments, with recognition performance better than the existing state-of-the-art methods. The experimental results show that the method exhibits excellent recognition performance in multi-class cell-phones recognition.