 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierSearch: A Hierarchical Enterprise Deep Search Framework Integrating Local and Web Searches
Aug 11, 2025Recently, large reasoning models have demonstrated strong mathematical and coding abilities, and deep search leverages their reasoning capabilities in challenging information retrieval tasks. Existing deep search works are generally limited to a single knowledge source, either local or the Web. However, enterprises often require private deep search systems that can leverage search tools over both local and the Web corpus. Simply training an agent equipped with multiple search tools using flat reinforcement learning (RL) is a straightforward idea, but it has problems such as low training data efficiency and poor mastery of complex tools. To address the above issue, we propose a hierarchical agentic deep search framework, HierSearch, trained with hierarchical RL. At the low level, a local deep search agent and a Web deep search agent are trained to retrieve evidence from their corresponding domains. At the high level, a planner agent coordinates low-level agents and provides the final answer. Moreover, to prevent direct answer copying and error propagation, we design a knowledge refiner that filters out hallucinations and irrelevant evidence returned by low-level agents. Experiments show that HierSearch achieves better performance compared to flat RL, and outperforms various deep search and multi-source retrieval-augmented generation baselines in six benchmarks across general, finance, and medical domains.
ELSPR: Evaluator LLM Training Data Self-Purification on Non-Transitive Preferences via Tournament Graph Reconstruction
May 23, 2025Large language models (LLMs) are widely used as evaluators for open-ended tasks, while previous research has emphasized biases in LLM evaluations, the issue of non-transitivity in pairwise comparisons remains unresolved: non-transitive preferences for pairwise comparisons, where evaluators prefer A over B, B over C, but C over A. Our results suggest that low-quality training data may reduce the transitivity of preferences generated by the Evaluator LLM. To address this, We propose a graph-theoretic framework to analyze and mitigate this problem by modeling pairwise preferences as tournament graphs. We quantify non-transitivity and introduce directed graph structural entropy to measure the overall clarity of preferences. Our analysis reveals significant non-transitivity in advanced Evaluator LLMs (with Qwen2.5-Max exhibiting 67.96%), as well as high entropy values (0.8095 for Qwen2.5-Max), reflecting low overall clarity of preferences. To address this issue, we designed a filtering strategy, ELSPR, to eliminate preference data that induces non-transitivity, retaining only consistent and transitive preference data for model fine-tuning. Experiments demonstrate that models fine-tuned with filtered data reduce non-transitivity by 13.78% (from 64.28% to 50.50%), decrease structural entropy by 0.0879 (from 0.8113 to 0.7234), and align more closely with human evaluators (human agreement rate improves by 0.6% and Spearman correlation increases by 0.01).
MIDB: Multilingual Instruction Data Booster for Enhancing Multilingual Instruction Synthesis
May 23, 2025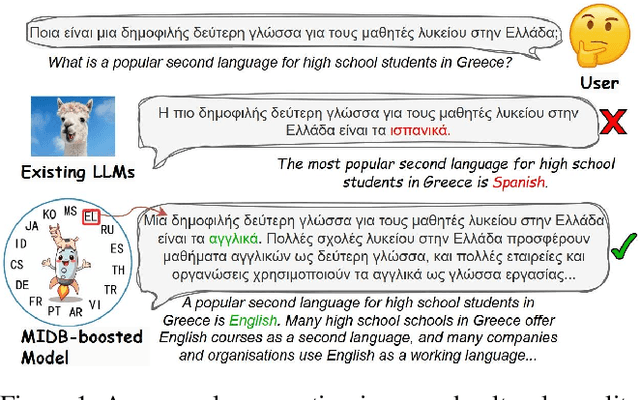
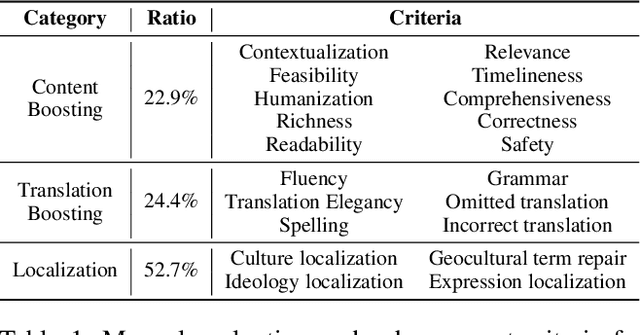
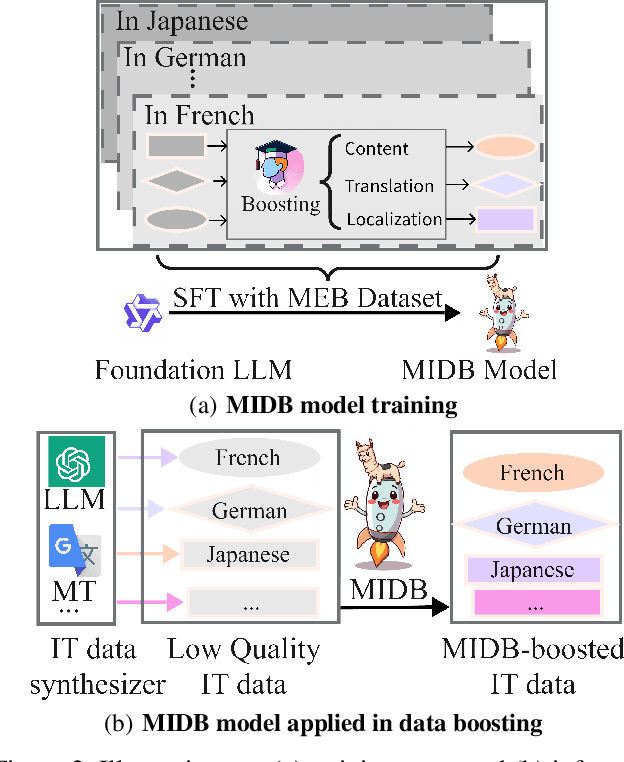
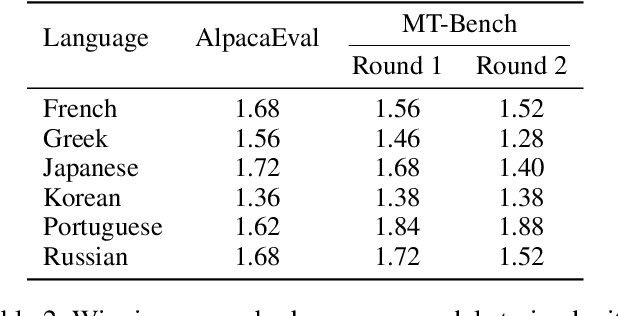
Despite doubts on data quality, instruction synthesis has been widely applied into instruction tuning (IT) of LLMs as an economic and rapid alternative. Recent endeavors focus on improving data quality for synthesized instruction pairs in English and have facilitated IT of English-centric LLMs. However, data quality issues in multilingual synthesized instruction pairs are even more severe, since the common synthesizing practice is to translate English synthesized data into other languages using machine translation (MT). Besides the known content errors in these English synthesized data, multilingual synthesized instruction data are further exposed to defects introduced by MT and face insufficient localization of the target languages. In this paper, we propose MIDB, a Multilingual Instruction Data Booster to automatically address the quality issues in multilingual synthesized data. MIDB is trained on around 36.8k revision examples across 16 languages by human linguistic experts, thereby can boost the low-quality data by addressing content errors and MT defects, and improving localization in these synthesized data. Both automatic and human evaluation indicate that not only MIDB steadily improved instruction data quality in 16 languages, but also the instruction-following and cultural-understanding abilities of multilingual LLMs fine-tuned on MIDB-boosted data were significantly enhanced.
Three-dimensional Reconstruction of the Lumbar Spine with Submillimeter Accuracy Using Biplanar X-ray Images
Mar 18, 2025
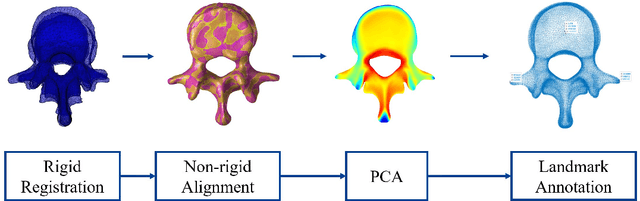
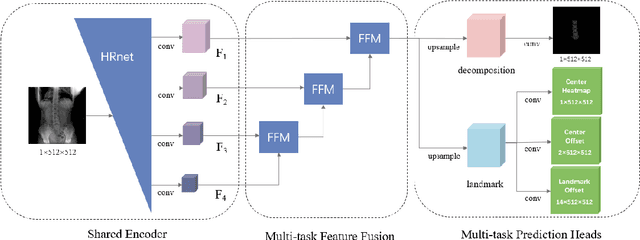
Three-dimensional reconstruction of the spine under weight-bearing conditions from biplanar X-ray images is of great importance for the clinical assessment of spinal diseases. However, the current fully automated reconstruction methods have low accuracy and fail to meet the clinical application standards. This study developed and validated a fully automated method for high-accuracy 3D reconstruction of the lumbar spine from biplanar X-ray images. The method involves lumbar decomposition and landmark detection from the raw X-ray images, followed by a deformable model and landmark-weighted 2D-3D registration approach. The reconstruction accuracy was validated by the gold standard obtained through the registration of CT-segmented vertebral models with the biplanar X-ray images. The proposed method achieved a 3D reconstruction accuracy of 0.80 mm, representing a significant improvement over the mainstream approaches. This study will contribute to the clinical diagnosis of lumbar in weight-bearing positions.
Model Evolution Framework with Genetic Algorithm for Multi-Task Reinforcement Learning
Feb 19, 2025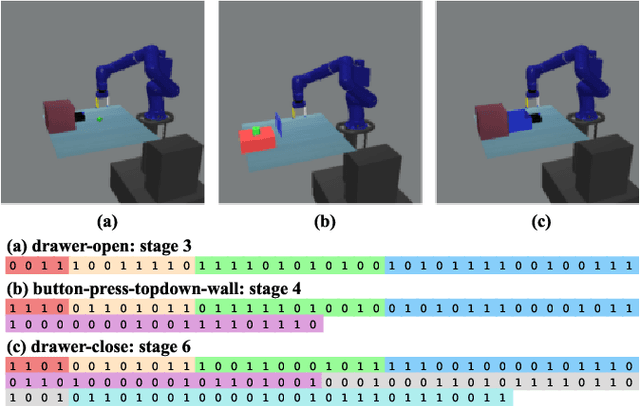



Multi-task reinforcement learning employs a single policy to complete various tasks, aiming to develop an agent with generalizability across different scenarios. Given the shared characteristics of tasks, the agent's learning efficiency can be enhanced through parameter sharing. Existing approaches typically use a routing network to generate specific routes for each task and reconstruct a set of modules into diverse models to complete multiple tasks simultaneously. However, due to the inherent difference between tasks, it is crucial to allocate resources based on task difficulty, which is constrained by the model's structure. To this end, we propose a Model Evolution framework with Genetic Algorithm (MEGA), which enables the model to evolve during training according to the difficulty of the tasks. When the current model is insufficient for certain tasks, the framework will automatically incorporate additional modules, enhancing the model's capabilities. Moreover, to adapt to our model evolution framework, we introduce a genotype module-level model, using binary sequences as genotype policies for model reconstruction, while leveraging a non-gradient genetic algorithm to optimize these genotype policies. Unlike routing networks with fixed output dimensions, our approach allows for the dynamic adjustment of the genotype policy length, enabling it to accommodate models with a varying number of modules. We conducted experiments on various robotics manipulation tasks in the Meta-World benchmark. Our state-of-the-art performance demonstrated the effectiveness of the MEGA framework. We will release our source code to the public.
SMAC-Hard: Enabling Mixed Opponent Strategy Script and Self-play on SMAC
Dec 24, 2024The availability of challenging simulation environments is pivotal for advancing the field of Multi-Agent Reinforcement Learning (MARL). In cooperative MARL settings, the StarCraft Multi-Agent Challenge (SMAC) has gained prominence as a benchmark for algorithms following centralized training with decentralized execution paradigm. However, with continual advancements in SMAC, many algorithms now exhibit near-optimal performance, complicating the evaluation of their true effectiveness. To alleviate this problem, in this work, we highlight a critical issue: the default opponent policy in these environments lacks sufficient diversity, leading MARL algorithms to overfit and exploit unintended vulnerabilities rather than learning robust strategies. To overcome these limitations, we propose SMAC-HARD, a novel benchmark designed to enhance training robustness and evaluation comprehensiveness. SMAC-HARD supports customizable opponent strategies, randomization of adversarial policies, and interfaces for MARL self-play, enabling agents to generalize to varying opponent behaviors and improve model stability. Furthermore, we introduce a black-box testing framework wherein agents are trained without exposure to the edited opponent scripts but are tested against these scripts to evaluate the policy coverage and adaptability of MARL algorithms. We conduct extensive evaluations of widely used and state-of-the-art algorithms on SMAC-HARD, revealing the substantial challenges posed by edited and mixed strategy opponents. Additionally, the black-box strategy tests illustrate the difficulty of transferring learned policies to unseen adversaries. We envision SMAC-HARD as a critical step toward benchmarking the next generation of MARL algorithms, fostering progress in self-play methods for multi-agent systems. Our code is available at https://github.com/devindeng94/smac-hard.
DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models
Oct 09, 2024


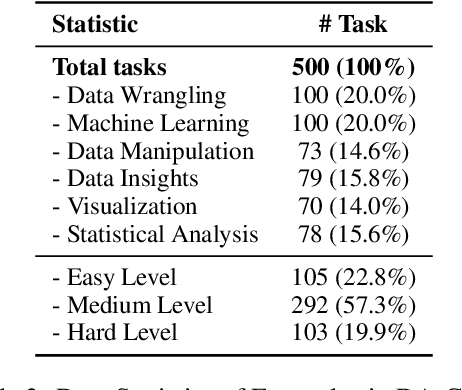
We introduce DA-Code, a code generation benchmark specifically designed to assess LLMs on agent-based data science tasks. This benchmark features three core elements: First, the tasks within DA-Code are inherently challenging, setting them apart from traditional code generation tasks and demanding advanced coding skills in grounding and planning. Second, examples in DA-Code are all based on real and diverse data, covering a wide range of complex data wrangling and analytics tasks. Third, to solve the tasks, the models must utilize complex data science programming languages, to perform intricate data processing and derive the answers. We set up the benchmark in a controllable and executable environment that aligns with real-world data analysis scenarios and is scalable. The annotators meticulously design the evaluation suite to ensure the accuracy and robustness of the evaluation. We develop the DA-Agent baseline. Experiments show that although the baseline performs better than other existing frameworks, using the current best LLMs achieves only 30.5% accuracy, leaving ample room for improvement. We release our benchmark at [https://da-code-bench.github.io](https://da-code-bench.github.io).
Skipped Feature Pyramid Network with Grid Anchor for Object Detection
Oct 22, 2023CNN-based object detection methods have achieved significant progress in recent years. The classic structures of CNNs produce pyramid-like feature maps due to the pooling or other re-scale operations. The feature maps in different levels of the feature pyramid are used to detect objects with different scales. For more accurate object detection, the highest-level feature, which has the lowest resolution and contains the strongest semantics, is up-scaled and connected with the lower-level features to enhance the semantics in the lower-level features. However, the classic mode of feature connection combines the feature of lower-level with all the features above it, which may result in semantics degradation. In this paper, we propose a skipped connection to obtain stronger semantics at each level of the feature pyramid. In our method, the lower-level feature only connects with the feature at the highest level, making it more reasonable that each level is responsible for detecting objects with fixed scales. In addition, we simplify the generation of anchor for bounding box regression, which can further improve the accuracy of object detection. The experiments on the MS COCO and Wider Face demonstrate that our method outperforms the state-of-the-art methods.
Image Compressed Sensing with Multi-scale Dilated Convolutional Neural Network
Sep 28, 2022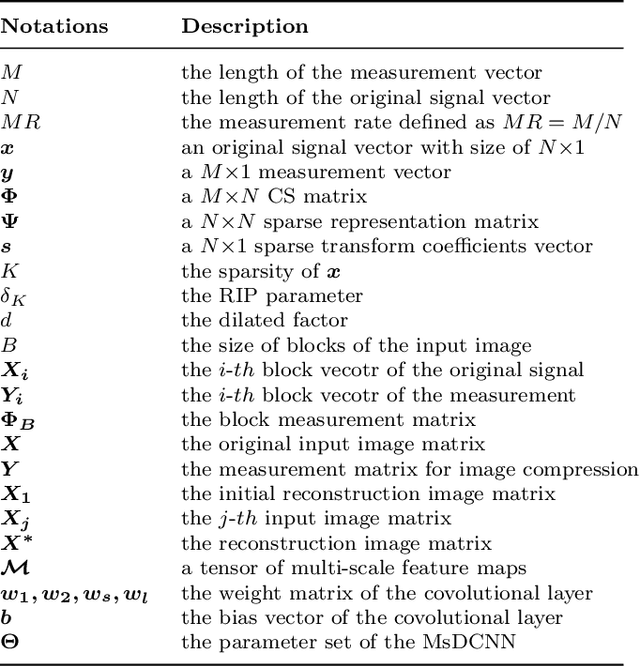
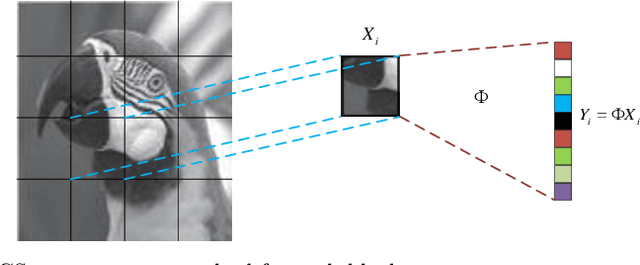
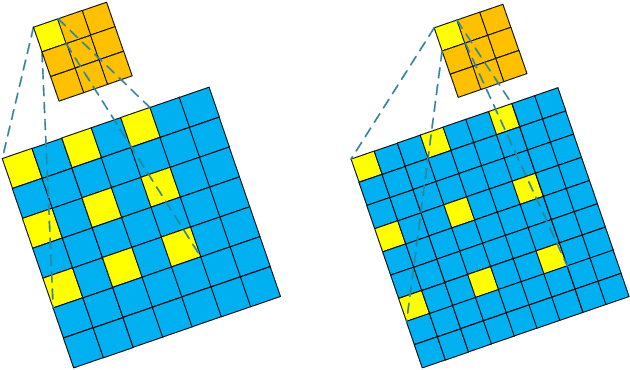
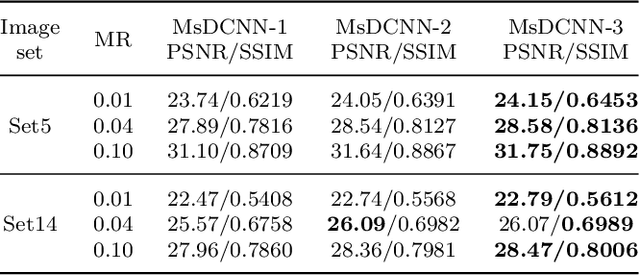
Deep Learning (DL) based Compressed Sensing (CS) has been applied for better performance of image reconstruction than traditional CS methods. However, most existing DL methods utilize the block-by-block measurement and each measurement block is restored separately, which introduces harmful blocking effects for reconstruction. Furthermore, the neuronal receptive fields of those methods are designed to be the same size in each layer, which can only collect single-scale spatial information and has a negative impact on the reconstruction process. This paper proposes a novel framework named Multi-scale Dilated Convolution Neural Network (MsDCNN) for CS measurement and reconstruction. During the measurement period, we directly obtain all measurements from a trained measurement network, which employs fully convolutional structures and is jointly trained with the reconstruction network from the input image. It needn't be cut into blocks, which effectively avoids the block effect. During the reconstruction period, we propose the Multi-scale Feature Extraction (MFE) architecture to imitate the human visual system to capture multi-scale features from the same feature map, which enhances the image feature extraction ability of the framework and improves the performance of image reconstruction. In the MFE, there are multiple parallel convolution channels to obtain multi-scale feature information. Then the multi-scale features information is fused and the original image is reconstructed with high quality. Our experimental results show that the proposed method performs favorably against the state-of-the-art methods in terms of PSNR and SSIM.
Abs-CAM: A Gradient Optimization Interpretable Approach for Explanation of Convolutional Neural Networks
Jul 08, 2022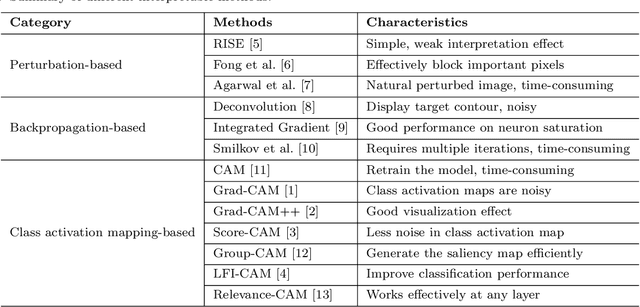
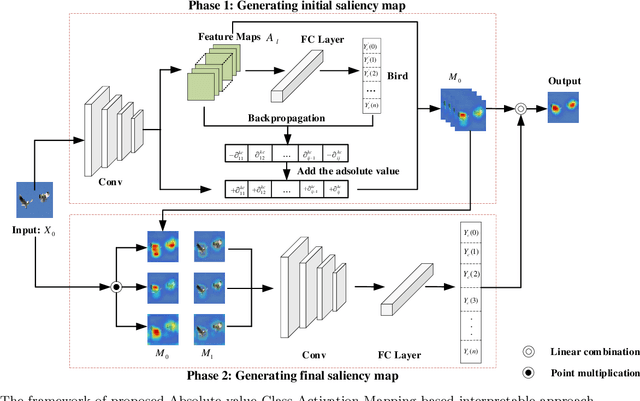

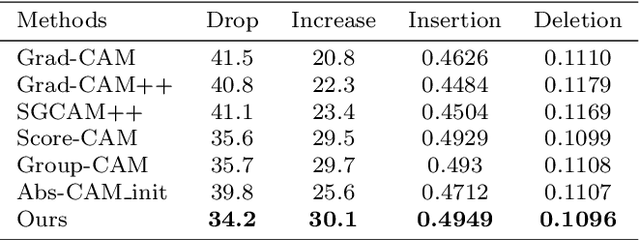
The black-box nature of Deep Neural Networks (DNNs) severely hinders its performance improvement and application in specific scenes. In recent years, class activation mapping-based method has been widely used to interpret the internal decisions of models in computer vision tasks. However, when this method uses backpropagation to obtain gradients, it will cause noise in the saliency map, and even locate features that are irrelevant to decisions. In this paper, we propose an Absolute value Class Activation Mapping-based (Abs-CAM) method, which optimizes the gradients derived from the backpropagation and turns all of them into positive gradients to enhance the visual features of output neurons' activation, and improve the localization ability of the saliency map. The framework of Abs-CAM is divided into two phases: generating initial saliency map and generating final saliency map. The first phase improves the localization ability of the saliency map by optimizing the gradient, and the second phase linearly combines the initial saliency map with the original image to enhance the semantic information of the saliency map. We conduct qualitative and quantitative evaluation of the proposed method, including Deletion, Insertion, and Pointing Game. The experimental results show that the Abs-CAM can obviously eliminate the noise in the saliency map, and can better locate the features related to decisions, and is superior to the previous methods in recognition and localization tasks.