 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA method for improving multilingual quality and diversity of instruction fine-tuning datasets
Sep 19, 2025Multilingual Instruction Fine-Tuning (IFT) is essential for enabling large language models (LLMs) to generalize effectively across diverse linguistic and cultural contexts. However, the scarcity of high-quality multilingual training data and corresponding building method remains a critical bottleneck. While data selection has shown promise in English settings, existing methods often fail to generalize across languages due to reliance on simplistic heuristics or language-specific assumptions. In this work, we introduce Multilingual Data Quality and Diversity (M-DaQ), a novel method for improving LLMs multilinguality, by selecting high-quality and semantically diverse multilingual IFT samples. We further conduct the first systematic investigation of the Superficial Alignment Hypothesis (SAH) in multilingual setting. Empirical results across 18 languages demonstrate that models fine-tuned with M-DaQ method achieve significant performance gains over vanilla baselines over 60% win rate. Human evaluations further validate these gains, highlighting the increment of cultural points in the response. We release the M-DaQ code to support future research.
CultureScope: A Dimensional Lens for Probing Cultural Understanding in LLMs
Sep 19, 2025As large language models (LLMs) are increasingly deployed in diverse cultural environments, evaluating their cultural understanding capability has become essential for ensuring trustworthy and culturally aligned applications. However, most existing benchmarks lack comprehensiveness and are challenging to scale and adapt across different cultural contexts, because their frameworks often lack guidance from well-established cultural theories and tend to rely on expert-driven manual annotations. To address these issues, we propose CultureScope, the most comprehensive evaluation framework to date for assessing cultural understanding in LLMs. Inspired by the cultural iceberg theory, we design a novel dimensional schema for cultural knowledge classification, comprising 3 layers and 140 dimensions, which guides the automated construction of culture-specific knowledge bases and corresponding evaluation datasets for any given languages and cultures. Experimental results demonstrate that our method can effectively evaluate cultural understanding. They also reveal that existing large language models lack comprehensive cultural competence, and merely incorporating multilingual data does not necessarily enhance cultural understanding. All code and data files are available at https://github.com/HoganZinger/Culture
ELSPR: Evaluator LLM Training Data Self-Purification on Non-Transitive Preferences via Tournament Graph Reconstruction
May 23, 2025Large language models (LLMs) are widely used as evaluators for open-ended tasks, while previous research has emphasized biases in LLM evaluations, the issue of non-transitivity in pairwise comparisons remains unresolved: non-transitive preferences for pairwise comparisons, where evaluators prefer A over B, B over C, but C over A. Our results suggest that low-quality training data may reduce the transitivity of preferences generated by the Evaluator LLM. To address this, We propose a graph-theoretic framework to analyze and mitigate this problem by modeling pairwise preferences as tournament graphs. We quantify non-transitivity and introduce directed graph structural entropy to measure the overall clarity of preferences. Our analysis reveals significant non-transitivity in advanced Evaluator LLMs (with Qwen2.5-Max exhibiting 67.96%), as well as high entropy values (0.8095 for Qwen2.5-Max), reflecting low overall clarity of preferences. To address this issue, we designed a filtering strategy, ELSPR, to eliminate preference data that induces non-transitivity, retaining only consistent and transitive preference data for model fine-tuning. Experiments demonstrate that models fine-tuned with filtered data reduce non-transitivity by 13.78% (from 64.28% to 50.50%), decrease structural entropy by 0.0879 (from 0.8113 to 0.7234), and align more closely with human evaluators (human agreement rate improves by 0.6% and Spearman correlation increases by 0.01).
MIDB: Multilingual Instruction Data Booster for Enhancing Multilingual Instruction Synthesis
May 23, 2025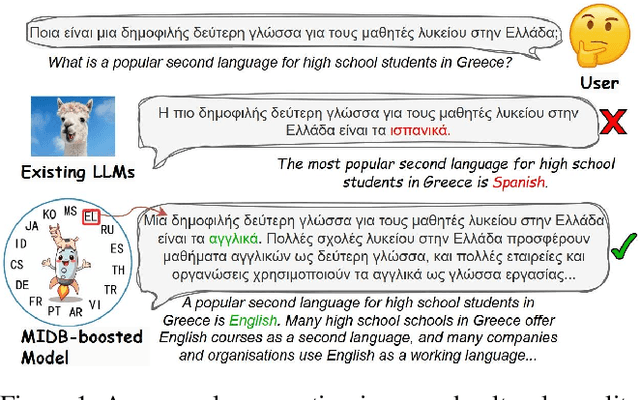
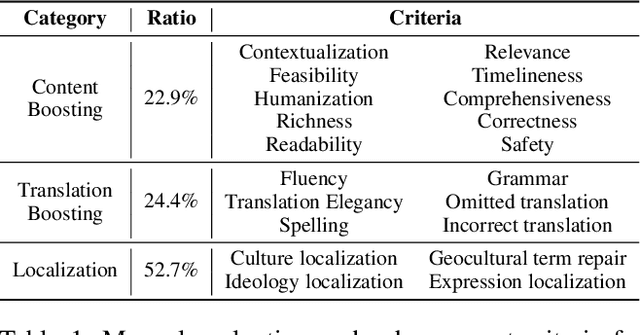
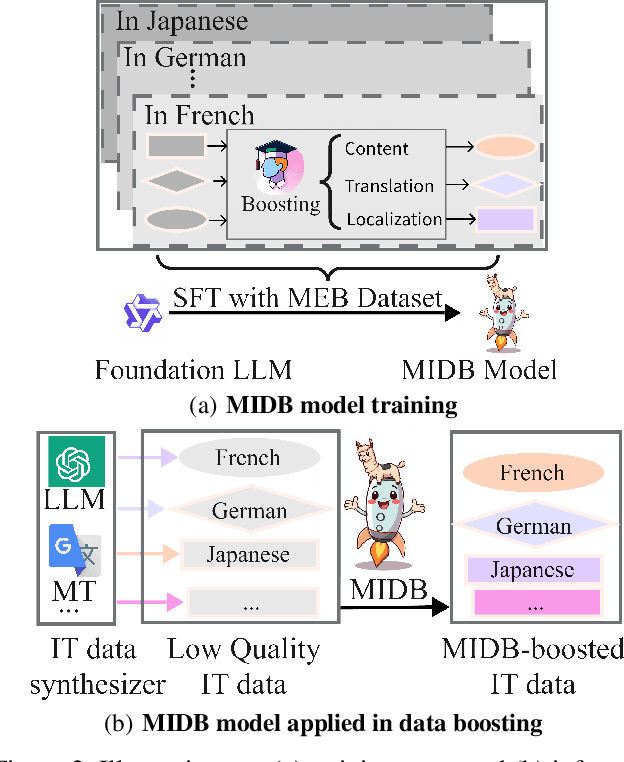
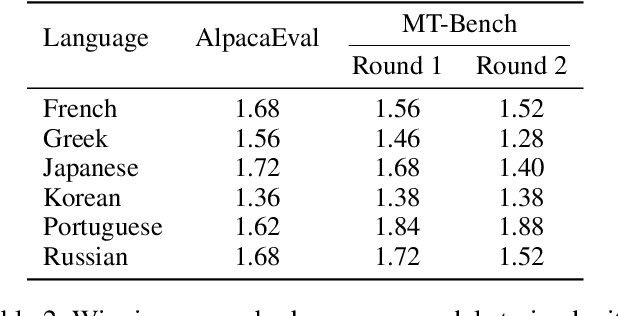
Despite doubts on data quality, instruction synthesis has been widely applied into instruction tuning (IT) of LLMs as an economic and rapid alternative. Recent endeavors focus on improving data quality for synthesized instruction pairs in English and have facilitated IT of English-centric LLMs. However, data quality issues in multilingual synthesized instruction pairs are even more severe, since the common synthesizing practice is to translate English synthesized data into other languages using machine translation (MT). Besides the known content errors in these English synthesized data, multilingual synthesized instruction data are further exposed to defects introduced by MT and face insufficient localization of the target languages. In this paper, we propose MIDB, a Multilingual Instruction Data Booster to automatically address the quality issues in multilingual synthesized data. MIDB is trained on around 36.8k revision examples across 16 languages by human linguistic experts, thereby can boost the low-quality data by addressing content errors and MT defects, and improving localization in these synthesized data. Both automatic and human evaluation indicate that not only MIDB steadily improved instruction data quality in 16 languages, but also the instruction-following and cultural-understanding abilities of multilingual LLMs fine-tuned on MIDB-boosted data were significantly enhanced.
R1-T1: Fully Incentivizing Translation Capability in LLMs via Reasoning Learning
Feb 27, 2025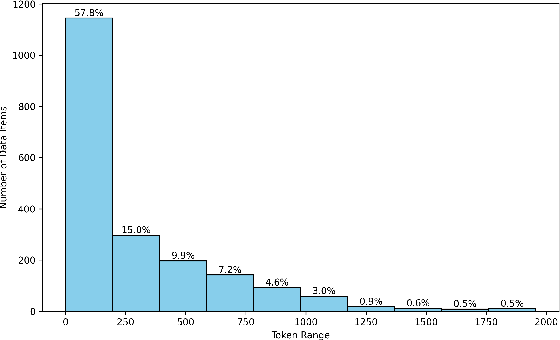

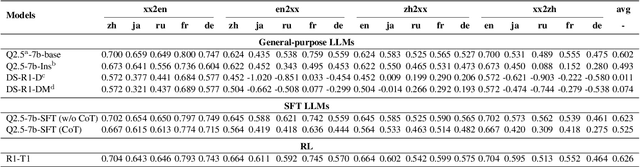
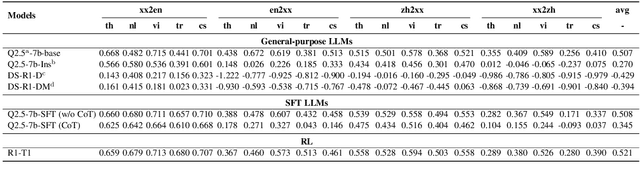
Despite recent breakthroughs in reasoning-enhanced large language models (LLMs) like DeepSeek-R1, incorporating inference-time reasoning into machine translation (MT), where human translators naturally employ structured, multi-layered reasoning chain-of-thoughts (CoTs), is yet underexplored. Existing methods either design a fixed CoT tailored for a specific MT sub-task (e.g., literature translation), or rely on synthesizing CoTs unaligned with humans and supervised fine-tuning (SFT) prone to catastrophic forgetting, limiting their adaptability to diverse translation scenarios. This paper introduces R1-Translator (R1-T1), a novel framework to achieve inference-time reasoning for general MT via reinforcement learning (RL) with human-aligned CoTs comprising six common patterns. Our approach pioneers three innovations: (1) extending reasoning-based translation beyond MT sub-tasks to six languages and diverse tasks (e.g., legal/medical domain adaptation, idiom resolution); (2) formalizing six expert-curated CoT templates that mirror hybrid human strategies like context-aware paraphrasing and back translation; and (3) enabling self-evolving CoT discovery and anti-forgetting adaptation through RL with KL-constrained rewards. Experimental results indicate a steady translation performance improvement in 21 languages and 80 translation directions on Flores-101 test set, especially on the 15 languages unseen from training, with its general multilingual abilities preserved compared with plain SFT.
Clustering and Ranking: Diversity-preserved Instruction Selection through Expert-aligned Quality Estimation
Feb 28, 2024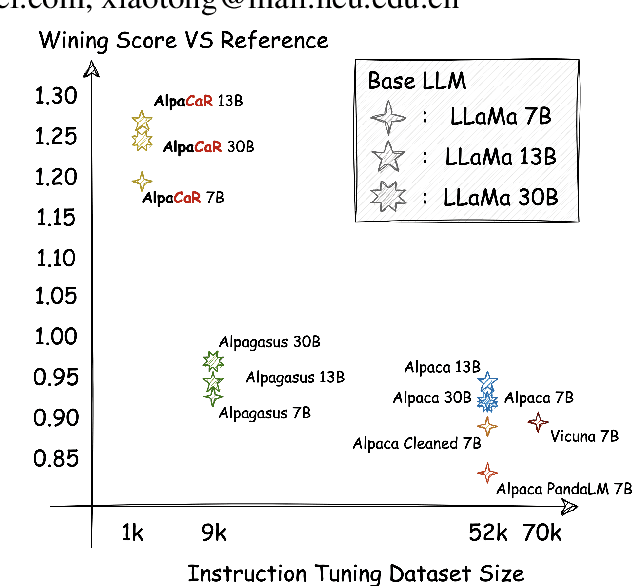

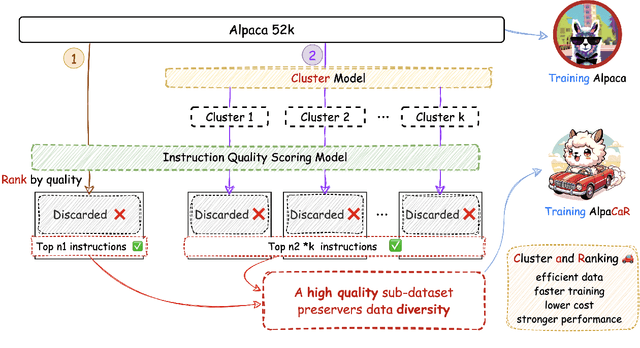
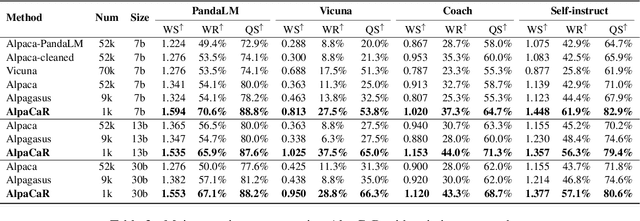
With contributions from the open-source community, a vast amount of instruction tuning (IT) data has emerged. Given the significant resource allocation required by training and evaluating models, it is advantageous to have an efficient method for selecting high-quality IT data. However, existing methods for instruction data selection have limitations such as relying on fragile external APIs, being affected by biases in GPT models, or reducing the diversity of the selected instruction dataset. In this paper, we propose an industrial-friendly, expert-aligned and diversity-preserved instruction data selection method: Clustering and Ranking (CaR). CaR consists of two steps. The first step involves ranking instruction pairs using a scoring model that is well aligned with expert preferences (achieving an accuracy of 84.25%). The second step involves preserving dataset diversity through a clustering process.In our experiment, CaR selected a subset containing only 1.96% of Alpaca's IT data, yet the underlying AlpaCaR model trained on this subset outperforms Alpaca by an average of 32.1% in GPT-4 evaluations. Furthermore, our method utilizes small models (355M parameters) and requires only 11.2% of the monetary cost compared to existing methods, making it easily deployable in industrial scenarios.
Automatic Instruction Optimization for Open-source LLM Instruction Tuning
Nov 22, 2023



Instruction tuning is crucial for enabling Language Learning Models (LLMs) in responding to human instructions. The quality of instruction pairs used for tuning greatly affects the performance of LLMs. However, the manual creation of high-quality instruction datasets is costly, leading to the adoption of automatic generation of instruction pairs by LLMs as a popular alternative in the training of open-source LLMs. To ensure the high quality of LLM-generated instruction datasets, several approaches have been proposed. Nevertheless, existing methods either compromise dataset integrity by filtering a large proportion of samples, or are unsuitable for industrial applications. In this paper, instead of discarding low-quality samples, we propose CoachLM, a novel approach to enhance the quality of instruction datasets through automatic revisions on samples in the dataset. CoachLM is trained from the samples revised by human experts and significantly increases the proportion of high-quality samples in the dataset from 17.7% to 78.9%. The effectiveness of CoachLM is further assessed on various real-world instruction test sets. The results show that CoachLM improves the instruction-following capabilities of the instruction-tuned LLM by an average of 29.9%, which even surpasses larger LLMs with nearly twice the number of parameters. Furthermore, CoachLM is successfully deployed in a data management system for LLMs at Huawei, resulting in an efficiency improvement of up to 20% in the cleaning of 40k real-world instruction pairs. We release the training data and code of CoachLM (https://github.com/lunyiliu/CoachLM).