 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering and Ranking: Diversity-preserved Instruction Selection through Expert-aligned Quality Estimation
Paper and Code
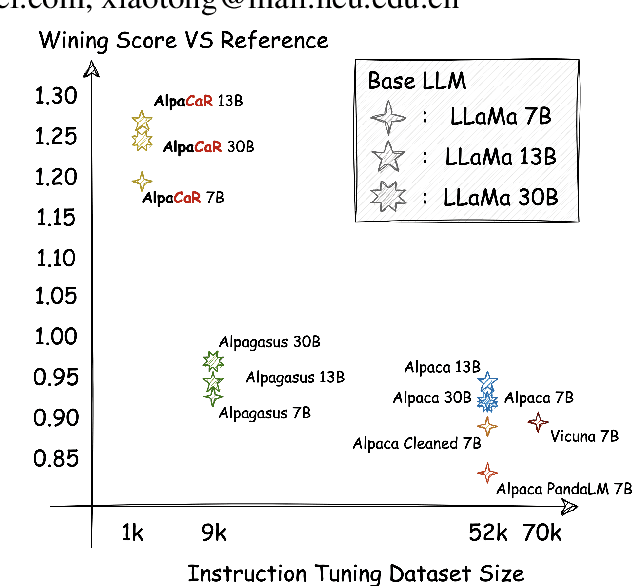

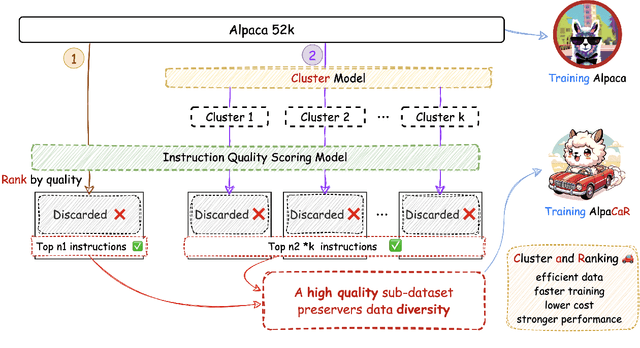
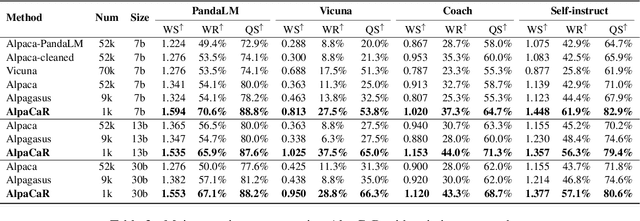
With contributions from the open-source community, a vast amount of instruction tuning (IT) data has emerged. Given the significant resource allocation required by training and evaluating models, it is advantageous to have an efficient method for selecting high-quality IT data. However, existing methods for instruction data selection have limitations such as relying on fragile external APIs, being affected by biases in GPT models, or reducing the diversity of the selected instruction dataset. In this paper, we propose an industrial-friendly, expert-aligned and diversity-preserved instruction data selection method: Clustering and Ranking (CaR). CaR consists of two steps. The first step involves ranking instruction pairs using a scoring model that is well aligned with expert preferences (achieving an accuracy of 84.25%). The second step involves preserving dataset diversity through a clustering process.In our experiment, CaR selected a subset containing only 1.96% of Alpaca's IT data, yet the underlying AlpaCaR model trained on this subset outperforms Alpaca by an average of 32.1% in GPT-4 evaluations. Furthermore, our method utilizes small models (355M parameters) and requires only 11.2% of the monetary cost compared to existing methods, making it easily deployable in industrial scenarios.