 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualActBench: Can VLMs See and Act like a Human?
Dec 10, 2025Vision-Language Models (VLMs) have achieved impressive progress in perceiving and describing visual environments. However, their ability to proactively reason and act based solely on visual inputs, without explicit textual prompts, remains underexplored. We introduce a new task, Visual Action Reasoning, and propose VisualActBench, a large-scale benchmark comprising 1,074 videos and 3,733 human-annotated actions across four real-world scenarios. Each action is labeled with an Action Prioritization Level (APL) and a proactive-reactive type to assess models' human-aligned reasoning and value sensitivity. We evaluate 29 VLMs on VisualActBench and find that while frontier models like GPT4o demonstrate relatively strong performance, a significant gap remains compared to human-level reasoning, particularly in generating proactive, high-priority actions. Our results highlight limitations in current VLMs' ability to interpret complex context, anticipate outcomes, and align with human decision-making frameworks. VisualActBench establishes a comprehensive foundation for assessing and improving the real-world readiness of proactive, vision-centric AI agents.
SUBQRAG: sub-question driven dynamic graph rag
Oct 09, 2025Graph Retrieval-Augmented Generation (Graph RAG) effectively builds a knowledge graph (KG) to connect disparate facts across a large document corpus. However, this broad-view approach often lacks the deep structured reasoning needed for complex multi-hop question answering (QA), leading to incomplete evidence and error accumulation. To address these limitations, we propose SubQRAG, a sub-question-driven framework that enhances reasoning depth. SubQRAG decomposes a complex question into an ordered chain of verifiable sub-questions. For each sub-question, it retrieves relevant triples from the graph. When the existing graph is insufficient, the system dynamically expands it by extracting new triples from source documents in real time. All triples used in the reasoning process are aggregated into a "graph memory," forming a structured and traceable evidence path for final answer generation. Experiments on three multi-hop QA benchmarks demonstrate that SubQRAG achieves consistent and significant improvements, especially in Exact Match scores.
FLEXI: Benchmarking Full-duplex Human-LLM Speech Interaction
Sep 26, 2025Full-Duplex Speech-to-Speech Large Language Models (LLMs) are foundational to natural human-computer interaction, enabling real-time spoken dialogue systems. However, benchmarking and modeling these models remains a fundamental challenge. We introduce FLEXI, the first benchmark for full-duplex LLM-human spoken interaction that explicitly incorporates model interruption in emergency scenarios. FLEXI systematically evaluates the latency, quality, and conversational effectiveness of real-time dialogue through six diverse human-LLM interaction scenarios, revealing significant gaps between open source and commercial models in emergency awareness, turn terminating, and interaction latency. Finally, we suggest that next token-pair prediction offers a promising path toward achieving truly seamless and human-like full-duplex interaction.
SageLM: A Multi-aspect and Explainable Large Language Model for Speech Judgement
Aug 28, 2025Speech-to-Speech (S2S) Large Language Models (LLMs) are foundational to natural human-computer interaction, enabling end-to-end spoken dialogue systems. However, evaluating these models remains a fundamental challenge. We propose \texttt{SageLM}, an end-to-end, multi-aspect, and explainable speech LLM for comprehensive S2S LLMs evaluation. First, unlike cascaded approaches that disregard acoustic features, SageLM jointly assesses both semantic and acoustic dimensions. Second, it leverages rationale-based supervision to enhance explainability and guide model learning, achieving superior alignment with evaluation outcomes compared to rule-based reinforcement learning methods. Third, we introduce \textit{SpeechFeedback}, a synthetic preference dataset, and employ a two-stage training paradigm to mitigate the scarcity of speech preference data. Trained on both semantic and acoustic dimensions, SageLM achieves an 82.79\% agreement rate with human evaluators, outperforming cascaded and SLM-based baselines by at least 7.42\% and 26.20\%, respectively.
Attention2Probability: Attention-Driven Terminology Probability Estimation for Robust Speech-to-Text System
Aug 26, 2025Recent advances in speech large language models (SLMs) have improved speech recognition and translation in general domains, but accurately generating domain-specific terms or neologisms remains challenging. To address this, we propose Attention2Probability: attention-driven terminology probability estimation for robust speech-to-text system, which is lightweight, flexible, and accurate. Attention2Probability converts cross-attention weights between speech and terminology into presence probabilities, and it further employs curriculum learning to enhance retrieval accuracy. Furthermore, to tackle the lack of data for speech-to-text tasks with terminology intervention, we create and release a new speech dataset with terminology to support future research in this area. Experimental results show that Attention2Probability significantly outperforms the VectorDB method on our test set. Specifically, its maximum recall rates reach 92.57% for Chinese and 86.83% for English. This high recall is achieved with a latency of only 8.71ms per query. Intervening in SLMs' recognition and translation tasks using Attention2Probability-retrieved terms improves terminology accuracy by 6-17%, while revealing that the current utilization of terminology by SLMs has limitations.
A Modular-based Strategy for Mitigating Gradient Conflicts in Simultaneous Speech Translation
Sep 24, 2024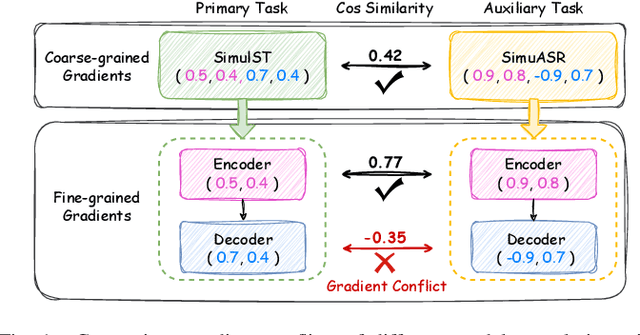
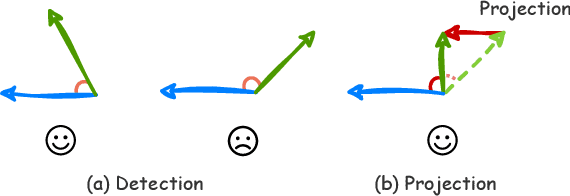
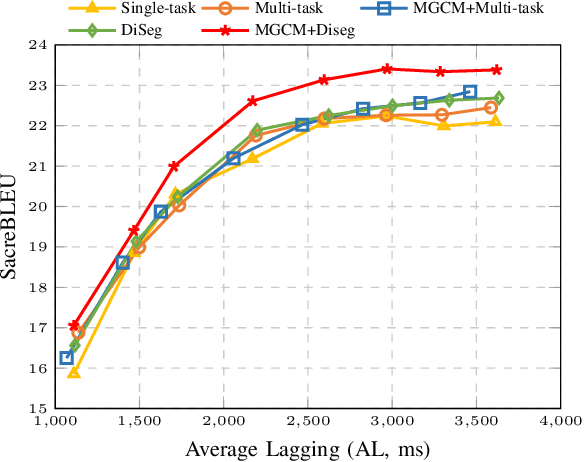
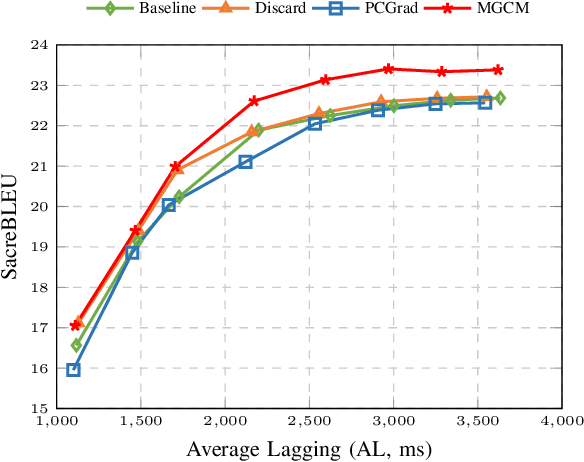
Simultaneous Speech Translation (SimulST) involves generating target language text while continuously processing streaming speech input, presenting significant real-time challenges. Multi-task learning is often employed to enhance SimulST performance but introduces optimization conflicts between primary and auxiliary tasks, potentially compromising overall efficiency. The existing model-level conflict resolution methods are not well-suited for this task which exacerbates inefficiencies and leads to high GPU memory consumption. To address these challenges, we propose a Modular Gradient Conflict Mitigation (MGCM) strategy that detects conflicts at a finer-grained modular level and resolves them utilizing gradient projection. Experimental results demonstrate that MGCM significantly improves SimulST performance, particularly under medium and high latency conditions, achieving a 0.68 BLEU score gain in offline tasks. Additionally, MGCM reduces GPU memory consumption by over 95\% compared to other conflict mitigation methods, establishing it as a robust solution for SimulST tasks.
NDP: Next Distribution Prediction as a More Broad Target
Aug 30, 2024


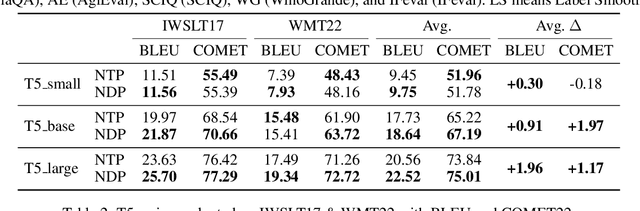
Large language models (LLMs) trained on next-token prediction (NTP) paradigm have demonstrated powerful capabilities. However, the existing NTP paradigm contains several limitations, particularly related to planned task complications and error propagation during inference. In our work, we extend the critique of NTP, highlighting its limitation also due to training with a narrow objective: the prediction of a sub-optimal one-hot distribution. To support this critique, we conducted a pre-experiment treating the output distribution from powerful LLMs as efficient world data compression. By evaluating the similarity between the $n$-gram distribution and the one-hot distribution with LLMs, we observed that the $n$-gram distributions align more closely with the output distribution of LLMs. Based on this insight, we introduce Next Distribution Prediction (NDP), which uses $n$-gram distributions to replace the one-hot targets, enhancing learning without extra online training time. We conducted experiments across translation, general task, language transfer, and medical domain adaptation. Compared to NTP, NDP can achieve up to +2.97 COMET improvement in translation tasks, +0.61 average improvement in general tasks, and incredible +10.75 average improvement in the medical domain. This demonstrates the concrete benefits of addressing the target narrowing problem, pointing to a new direction for future work on improving NTP.
RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners
Mar 22, 2024



Large Language Models (LLMs) have achieved impressive performance across various reasoning tasks. However, even state-of-the-art LLMs such as ChatGPT are prone to logical errors during their reasoning processes. Existing solutions, such as deploying task-specific verifiers or voting over multiple reasoning paths, either require extensive human annotations or fail in scenarios with inconsistent responses. To address these challenges, we introduce RankPrompt, a new prompting method that enables LLMs to self-rank their responses without additional resources. RankPrompt breaks down the ranking problem into a series of comparisons among diverse responses, leveraging the inherent capabilities of LLMs to generate chains of comparison as contextual exemplars. Our experiments across 11 arithmetic and commonsense reasoning tasks show that RankPrompt significantly enhances the reasoning performance of ChatGPT and GPT-4, with improvements of up to 13%. Moreover, RankPrompt excels in LLM-based automatic evaluations for open-ended tasks, aligning with human judgments 74% of the time in the AlpacaEval dataset. It also exhibits robustness to variations in response order and consistency. Collectively, our results validate RankPrompt as an effective method for eliciting high-quality feedback from language models.
Clustering and Ranking: Diversity-preserved Instruction Selection through Expert-aligned Quality Estimation
Feb 28, 2024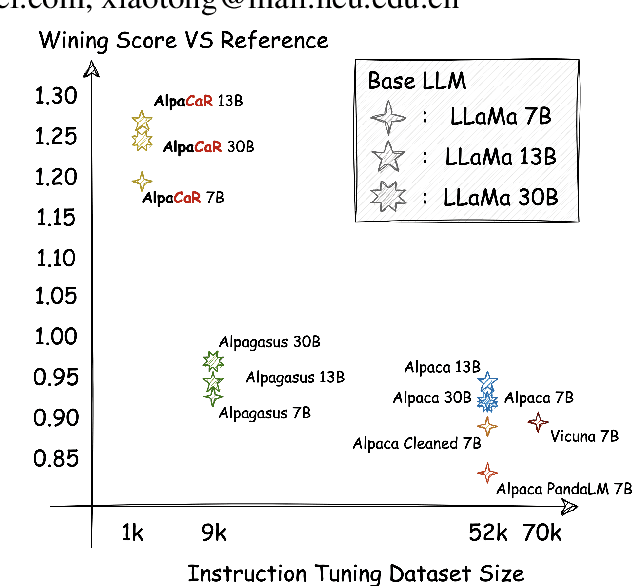

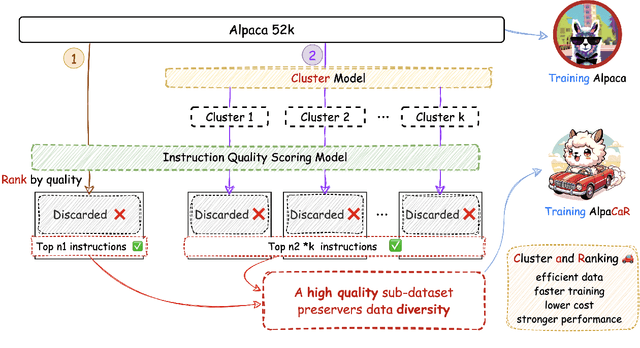
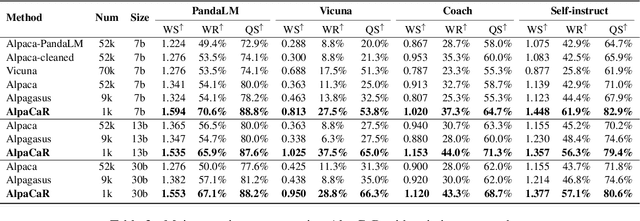
With contributions from the open-source community, a vast amount of instruction tuning (IT) data has emerged. Given the significant resource allocation required by training and evaluating models, it is advantageous to have an efficient method for selecting high-quality IT data. However, existing methods for instruction data selection have limitations such as relying on fragile external APIs, being affected by biases in GPT models, or reducing the diversity of the selected instruction dataset. In this paper, we propose an industrial-friendly, expert-aligned and diversity-preserved instruction data selection method: Clustering and Ranking (CaR). CaR consists of two steps. The first step involves ranking instruction pairs using a scoring model that is well aligned with expert preferences (achieving an accuracy of 84.25%). The second step involves preserving dataset diversity through a clustering process.In our experiment, CaR selected a subset containing only 1.96% of Alpaca's IT data, yet the underlying AlpaCaR model trained on this subset outperforms Alpaca by an average of 32.1% in GPT-4 evaluations. Furthermore, our method utilizes small models (355M parameters) and requires only 11.2% of the monetary cost compared to existing methods, making it easily deployable in industrial scenarios.