 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Autoregressive Diffusion Language Model
Jan 29, 2026In this work, we propose Causal Autoregressive Diffusion (CARD), a novel framework that unifies the training efficiency of ARMs with the high-throughput inference of diffusion models. CARD reformulates the diffusion process within a strictly causal attention mask, enabling dense, per-token supervision in a single forward pass. To address the optimization instability of causal diffusion, we introduce a soft-tailed masking schema to preserve local context and a context-aware reweighting mechanism derived from signal-to-noise principles. This design enables dynamic parallel decoding, where the model leverages KV-caching to adaptively generate variable-length token sequences based on confidence. Empirically, CARD outperforms existing discrete diffusion baselines while reducing training latency by 3 $\times$ compared to block diffusion methods. Our results demonstrate that CARD achieves ARM-level data efficiency while unlocking the latency benefits of parallel generation, establishing a robust paradigm for next-generation efficient LLMs.
SUBQRAG: sub-question driven dynamic graph rag
Oct 09, 2025Graph Retrieval-Augmented Generation (Graph RAG) effectively builds a knowledge graph (KG) to connect disparate facts across a large document corpus. However, this broad-view approach often lacks the deep structured reasoning needed for complex multi-hop question answering (QA), leading to incomplete evidence and error accumulation. To address these limitations, we propose SubQRAG, a sub-question-driven framework that enhances reasoning depth. SubQRAG decomposes a complex question into an ordered chain of verifiable sub-questions. For each sub-question, it retrieves relevant triples from the graph. When the existing graph is insufficient, the system dynamically expands it by extracting new triples from source documents in real time. All triples used in the reasoning process are aggregated into a "graph memory," forming a structured and traceable evidence path for final answer generation. Experiments on three multi-hop QA benchmarks demonstrate that SubQRAG achieves consistent and significant improvements, especially in Exact Match scores.
IIET: Efficient Numerical Transformer via Implicit Iterative Euler Method
Sep 26, 2025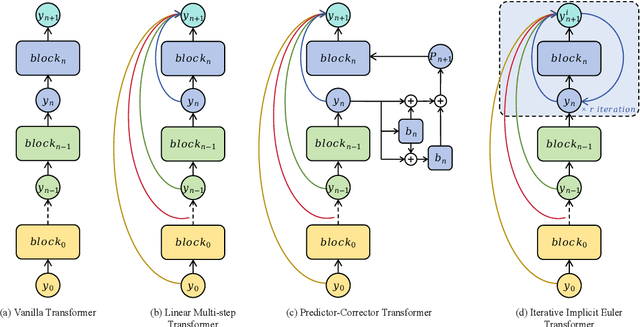
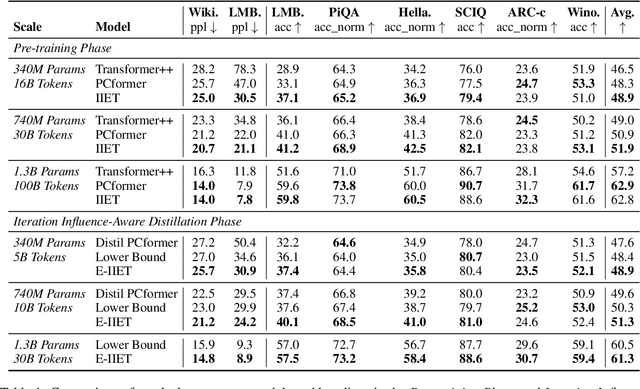
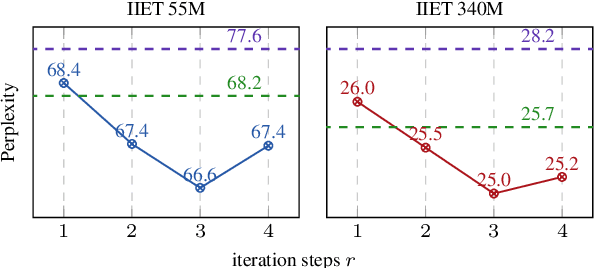

High-order numerical methods enhance Transformer performance in tasks like NLP and CV, but introduce a performance-efficiency trade-off due to increased computational overhead. Our analysis reveals that conventional efficiency techniques, such as distillation, can be detrimental to the performance of these models, exemplified by PCformer. To explore more optimizable ODE-based Transformer architectures, we propose the \textbf{I}terative \textbf{I}mplicit \textbf{E}uler \textbf{T}ransformer \textbf{(IIET)}, which simplifies high-order methods using an iterative implicit Euler approach. This simplification not only leads to superior performance but also facilitates model compression compared to PCformer. To enhance inference efficiency, we introduce \textbf{I}teration \textbf{I}nfluence-\textbf{A}ware \textbf{D}istillation \textbf{(IIAD)}. Through a flexible threshold, IIAD allows users to effectively balance the performance-efficiency trade-off. On lm-evaluation-harness, IIET boosts average accuracy by 2.65\% over vanilla Transformers and 0.8\% over PCformer. Its efficient variant, E-IIET, significantly cuts inference overhead by 55\% while retaining 99.4\% of the original task accuracy. Moreover, the most efficient IIET variant achieves an average performance gain exceeding 1.6\% over vanilla Transformer with comparable speed.
TCPO: Thought-Centric Preference Optimization for Effective Embodied Decision-making
Sep 10, 2025
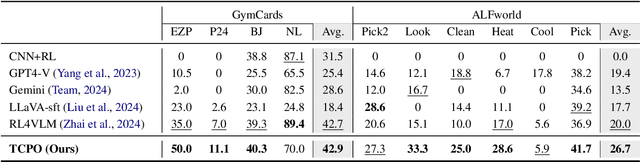
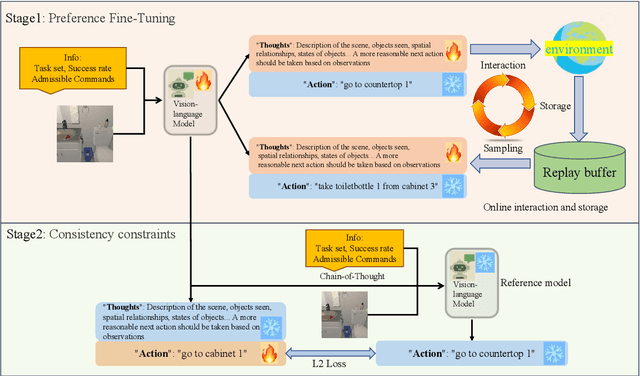

Using effective generalization capabilities of vision language models (VLMs) in context-specific dynamic tasks for embodied artificial intelligence remains a significant challenge. Although supervised fine-tuned models can better align with the real physical world, they still exhibit sluggish responses and hallucination issues in dynamically changing environments, necessitating further alignment. Existing post-SFT methods, reliant on reinforcement learning and chain-of-thought (CoT) approaches, are constrained by sparse rewards and action-only optimization, resulting in low sample efficiency, poor consistency, and model degradation. To address these issues, this paper proposes Thought-Centric Preference Optimization (TCPO) for effective embodied decision-making. Specifically, TCPO introduces a stepwise preference-based optimization approach, transforming sparse reward signals into richer step sample pairs. It emphasizes the alignment of the model's intermediate reasoning process, mitigating the problem of model degradation. Moreover, by incorporating Action Policy Consistency Constraint (APC), it further imposes consistency constraints on the model output. Experiments in the ALFWorld environment demonstrate an average success rate of 26.67%, achieving a 6% improvement over RL4VLM and validating the effectiveness of our approach in mitigating model degradation after fine-tuning. These results highlight the potential of integrating preference-based learning techniques with CoT processes to enhance the decision-making capabilities of vision-language models in embodied agents.
SLAM: Towards Efficient Multilingual Reasoning via Selective Language Alignment
Jan 07, 2025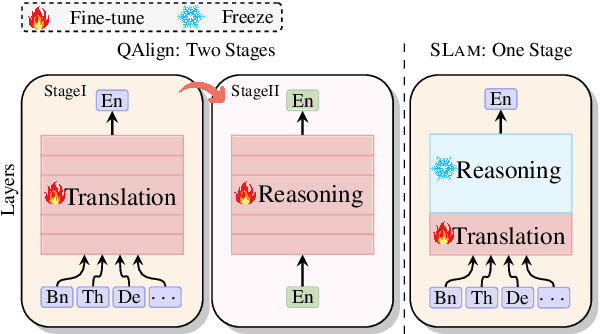


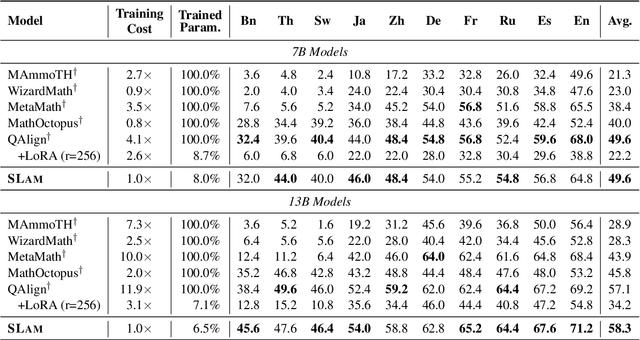
Despite the significant improvements achieved by large language models (LLMs) in English reasoning tasks, these models continue to struggle with multilingual reasoning. Recent studies leverage a full-parameter and two-stage training paradigm to teach models to first understand non-English questions and then reason. However, this method suffers from both substantial computational resource computing and catastrophic forgetting. The fundamental cause is that, with the primary goal of enhancing multilingual comprehension, an excessive number of irrelevant layers and parameters are tuned during the first stage. Given our findings that the representation learning of languages is merely conducted in lower-level layers, we propose an efficient multilingual reasoning alignment approach that precisely identifies and fine-tunes the layers responsible for handling multilingualism. Experimental results show that our method, SLAM, only tunes 6 layers' feed-forward sub-layers including 6.5-8% of all parameters within 7B and 13B LLMs, achieving superior average performance than all strong baselines across 10 languages. Meanwhile, SLAM only involves one training stage, reducing training time by 4.1-11.9 compared to the two-stage method.
NDP: Next Distribution Prediction as a More Broad Target
Aug 30, 2024


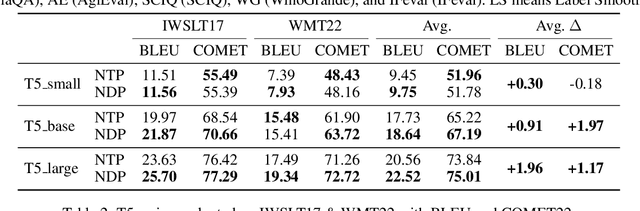
Large language models (LLMs) trained on next-token prediction (NTP) paradigm have demonstrated powerful capabilities. However, the existing NTP paradigm contains several limitations, particularly related to planned task complications and error propagation during inference. In our work, we extend the critique of NTP, highlighting its limitation also due to training with a narrow objective: the prediction of a sub-optimal one-hot distribution. To support this critique, we conducted a pre-experiment treating the output distribution from powerful LLMs as efficient world data compression. By evaluating the similarity between the $n$-gram distribution and the one-hot distribution with LLMs, we observed that the $n$-gram distributions align more closely with the output distribution of LLMs. Based on this insight, we introduce Next Distribution Prediction (NDP), which uses $n$-gram distributions to replace the one-hot targets, enhancing learning without extra online training time. We conducted experiments across translation, general task, language transfer, and medical domain adaptation. Compared to NTP, NDP can achieve up to +2.97 COMET improvement in translation tasks, +0.61 average improvement in general tasks, and incredible +10.75 average improvement in the medical domain. This demonstrates the concrete benefits of addressing the target narrowing problem, pointing to a new direction for future work on improving NTP.