 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Preference Representations: A Multi-Dimensional Evaluation and Analysis Method for Reward Models
Nov 16, 2025Previous methods evaluate reward models by testing them on a fixed pairwise ranking test set, but they typically do not provide performance information on each preference dimension. In this work, we address the evaluation challenge of reward models by probing preference representations. To confirm the effectiveness of this evaluation method, we construct a Multi-dimensional Reward Model Benchmark (MRMBench), a collection of six probing tasks for different preference dimensions. We design it to favor and encourage reward models that better capture preferences across different dimensions. Furthermore, we introduce an analysis method, inference-time probing, which identifies the dimensions used during the reward prediction and enhances its interpretability. Through extensive experiments, we find that MRMBench strongly correlates with the alignment performance of large language models (LLMs), making it a reliable reference for developing advanced reward models. Our analysis of MRMBench evaluation results reveals that reward models often struggle to capture preferences across multiple dimensions, highlighting the potential of multi-objective optimization in reward modeling. Additionally, our findings show that the proposed inference-time probing method offers a reliable metric for assessing the confidence of reward predictions, which ultimately improves the alignment of LLMs.
MRO: Enhancing Reasoning in Diffusion Language Models via Multi-Reward Optimization
Oct 24, 2025


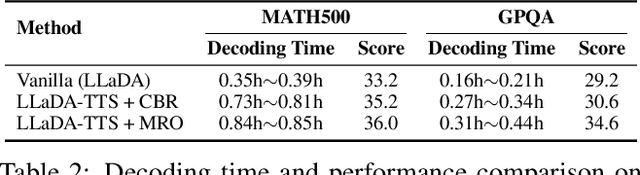
Recent advances in diffusion language models (DLMs) have presented a promising alternative to traditional autoregressive large language models (LLMs). However, DLMs still lag behind LLMs in reasoning performance, especially as the number of denoising steps decreases. Our analysis reveals that this shortcoming arises primarily from the independent generation of masked tokens across denoising steps, which fails to capture the token correlation. In this paper, we define two types of token correlation: intra-sequence correlation and inter-sequence correlation, and demonstrate that enhancing these correlations improves reasoning performance. To this end, we propose a Multi-Reward Optimization (MRO) approach, which encourages DLMs to consider the token correlation during the denoising process. More specifically, our MRO approach leverages test-time scaling, reject sampling, and reinforcement learning to directly optimize the token correlation with multiple elaborate rewards. Additionally, we introduce group step and importance sampling strategies to mitigate reward variance and enhance sampling efficiency. Through extensive experiments, we demonstrate that MRO not only improves reasoning performance but also achieves significant sampling speedups while maintaining high performance on reasoning benchmarks.
GRAM: A Generative Foundation Reward Model for Reward Generalization
Jun 18, 2025In aligning large language models (LLMs), reward models have played an important role, but are standardly trained as discriminative models and rely only on labeled human preference data. In this paper, we explore methods that train reward models using both unlabeled and labeled data. Building on the generative models in LLMs, we develop a generative reward model that is first trained via large-scale unsupervised learning and then fine-tuned via supervised learning. We also show that by using label smoothing, we are in fact optimizing a regularized pairwise ranking loss. This result, in turn, provides a new view of training reward models, which links generative models and discriminative models under the same class of training objectives. The outcome of these techniques is a foundation reward model, which can be applied to a wide range of tasks with little or no further fine-tuning effort. Extensive experiments show that this model generalizes well across several tasks, including response ranking, reinforcement learning from human feedback, and task adaptation with fine-tuning, achieving significant performance improvements over several strong baseline models.
Dissecting Long Reasoning Models: An Empirical Study
Jun 05, 2025



Despite recent progress in training long-context reasoning models via reinforcement learning (RL), several open questions and counterintuitive behaviors remain. This work focuses on three key aspects: (1) We systematically analyze the roles of positive and negative samples in RL, revealing that positive samples mainly facilitate data fitting, whereas negative samples significantly enhance generalization and robustness. Interestingly, training solely on negative samples can rival standard RL training performance. (2) We identify substantial data inefficiency in group relative policy optimization, where over half of the samples yield zero advantage. To address this, we explore two straightforward strategies, including relative length rewards and offline sample injection, to better leverage these data and enhance reasoning efficiency and capability. (3) We investigate unstable performance across various reasoning models and benchmarks, attributing instability to uncertain problems with ambiguous outcomes, and demonstrate that multiple evaluation runs mitigate this issue.
Beyond Decoder-only: Large Language Models Can be Good Encoders for Machine Translation
Mar 09, 2025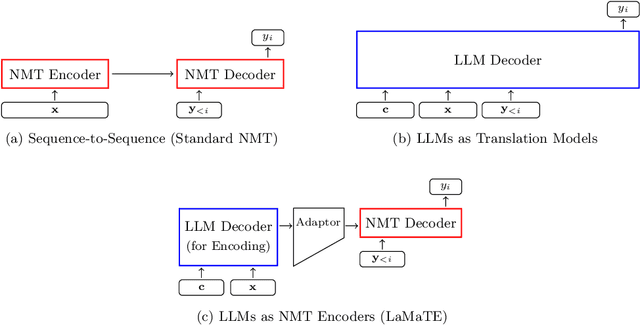
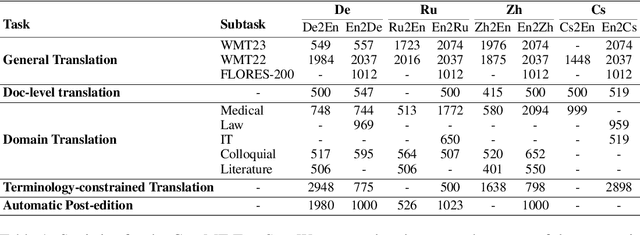
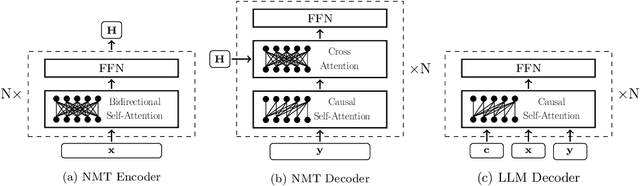
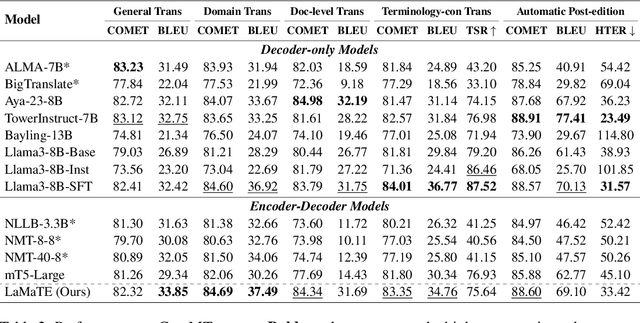
The field of neural machine translation (NMT) has changed with the advent of large language models (LLMs). Much of the recent emphasis in natural language processing (NLP) has been on modeling machine translation and many other problems using a single pre-trained Transformer decoder, while encoder-decoder architectures, which were the standard in earlier NMT models, have received relatively less attention. In this paper, we explore translation models that are universal, efficient, and easy to optimize, by marrying the world of LLMs with the world of NMT. We apply LLMs to NMT encoding and leave the NMT decoder unchanged. We also develop methods for adapting LLMs to work better with the NMT decoder. Furthermore, we construct a new dataset involving multiple tasks to assess how well the machine translation system generalizes across various tasks. Evaluations on the WMT and our datasets show that results using our method match or surpass a range of baselines in terms of translation quality, but achieve $2.4 \sim 6.5 \times$ inference speedups and a $75\%$ reduction in the memory footprint of the KV cache. It also demonstrates strong generalization across a variety of translation-related tasks.
Boosting Text-To-Image Generation via Multilingual Prompting in Large Multimodal Models
Jan 13, 2025Previous work on augmenting large multimodal models (LMMs) for text-to-image (T2I) generation has focused on enriching the input space of in-context learning (ICL). This includes providing a few demonstrations and optimizing image descriptions to be more detailed and logical. However, as demand for more complex and flexible image descriptions grows, enhancing comprehension of input text within the ICL paradigm remains a critical yet underexplored area. In this work, we extend this line of research by constructing parallel multilingual prompts aimed at harnessing the multilingual capabilities of LMMs. More specifically, we translate the input text into several languages and provide the models with both the original text and the translations. Experiments on two LMMs across 3 benchmarks show that our method, PMT2I, achieves superior performance in general, compositional, and fine-grained assessments, especially in human preference alignment. Additionally, with its advantage of generating more diverse images, PMT2I significantly outperforms baseline prompts when incorporated with reranking methods. Our code and parallel multilingual data can be found at https://github.com/takagi97/PMT2I.
SLAM: Towards Efficient Multilingual Reasoning via Selective Language Alignment
Jan 07, 2025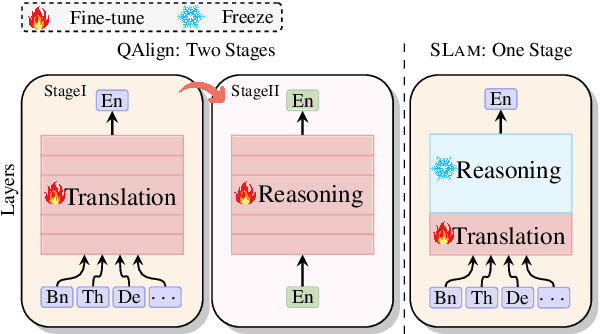


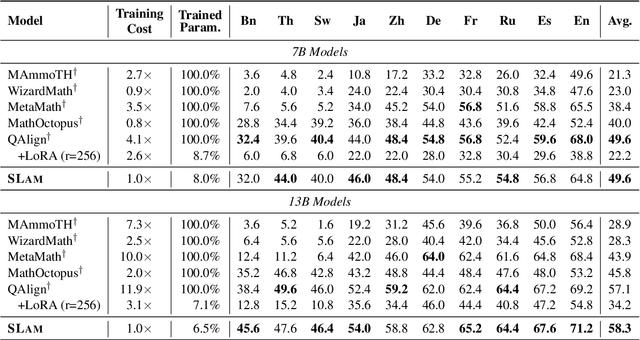
Despite the significant improvements achieved by large language models (LLMs) in English reasoning tasks, these models continue to struggle with multilingual reasoning. Recent studies leverage a full-parameter and two-stage training paradigm to teach models to first understand non-English questions and then reason. However, this method suffers from both substantial computational resource computing and catastrophic forgetting. The fundamental cause is that, with the primary goal of enhancing multilingual comprehension, an excessive number of irrelevant layers and parameters are tuned during the first stage. Given our findings that the representation learning of languages is merely conducted in lower-level layers, we propose an efficient multilingual reasoning alignment approach that precisely identifies and fine-tunes the layers responsible for handling multilingualism. Experimental results show that our method, SLAM, only tunes 6 layers' feed-forward sub-layers including 6.5-8% of all parameters within 7B and 13B LLMs, achieving superior average performance than all strong baselines across 10 languages. Meanwhile, SLAM only involves one training stage, reducing training time by 4.1-11.9 compared to the two-stage method.
LRHP: Learning Representations for Human Preferences via Preference Pairs
Oct 06, 2024



To improve human-preference alignment training, current research has developed numerous preference datasets consisting of preference pairs labeled as "preferred" or "dispreferred". These preference pairs are typically used to encode human preferences into a single numerical value through reward modeling, which acts as a reward signal during reinforcement learning from human feedback (RLHF). However, representing these human preferences as a numerical value complicates the analysis of these preferences and restricts their broader applications other than RLHF. In contrast, in this work, we introduce a preference representation learning task that aims to construct a richer and more structured representation of human preferences. We further develop a more generalizable framework, Learning Representations for Human Preferences via preference pairs (namely LRHP), which extends beyond traditional reward modeling to tackle this task. We verify the utility of preference representations in two downstream tasks: preference data selection and preference margin prediction. Building upon the human preferences in representations, we achieve strong performance in both tasks, significantly outperforming baselines.
RoVRM: A Robust Visual Reward Model Optimized via Auxiliary Textual Preference Data
Aug 22, 2024



Large vision-language models (LVLMs) often fail to align with human preferences, leading to issues like generating misleading content without proper visual context (also known as hallucination). A promising solution to this problem is using human-preference alignment techniques, such as best-of-n sampling and reinforcement learning. However, these techniques face the difficulty arising from the scarcity of visual preference data, which is required to train a visual reward model (VRM). In this work, we continue the line of research. We present a Robust Visual Reward Model (RoVRM) which improves human-preference alignment for LVLMs. RoVRM leverages auxiliary textual preference data through a three-phase progressive training and optimal transport-based preference data selection to effectively mitigate the scarcity of visual preference data. We experiment with RoVRM on the commonly used vision-language tasks based on the LLaVA-1.5-7B and -13B models. Experimental results demonstrate that RoVRM consistently outperforms traditional VRMs. Furthermore, our three-phase progressive training and preference data selection approaches can yield consistent performance gains over ranking-based alignment techniques, such as direct preference optimization.
Cross-layer Attention Sharing for Large Language Models
Aug 04, 2024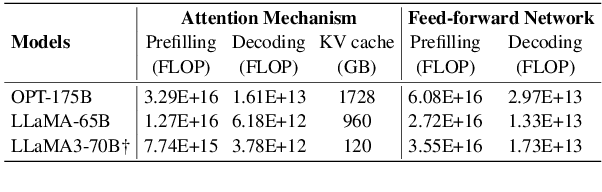
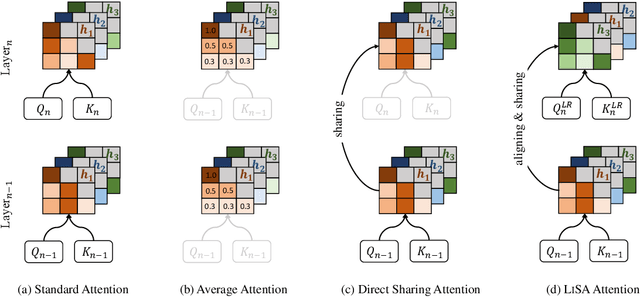
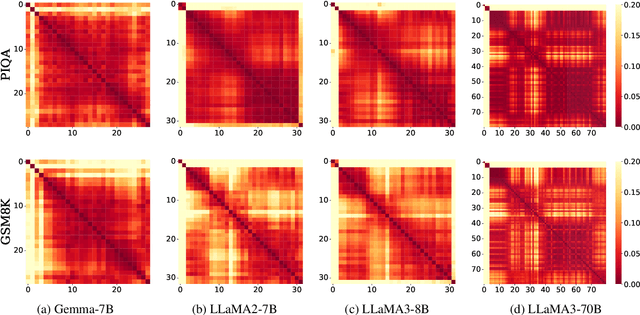
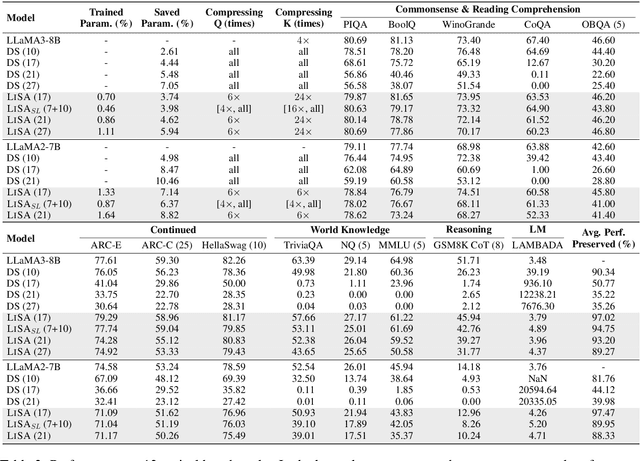
As large language models (LLMs) evolve, the increase in model depth and parameter number leads to substantial redundancy. To enhance the efficiency of the attention mechanism, previous works primarily compress the KV cache or group attention heads, while largely overlooking redundancy between layers. Our comprehensive analyses across various LLMs show that highly similar attention patterns persist within most layers. It's intuitive to save the computation by sharing attention weights across layers. However, further analysis reveals two challenges: (1) Directly sharing the weight matrix without carefully rearranging the attention heads proves to be ineffective; (2) Shallow layers are vulnerable to small deviations in attention weights. Driven by these insights, we introduce LiSA, a lightweight substitute for self-attention in well-trained LLMs. LiSA employs tiny feed-forward networks to align attention heads between adjacent layers and low-rank matrices to approximate differences in layer-wise attention weights. Evaluations encompassing 13 typical benchmarks demonstrate that LiSA maintains high response quality in terms of accuracy and perplexity while reducing redundant attention calculations within 53-84% of the total layers. Our implementations of LiSA achieve a 6X compression of Q and K, with maximum throughput improvements of 19.5% for LLaMA3-8B and 32.3% for LLaMA2-7B.