 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Text-To-Image Generation via Multilingual Prompting in Large Multimodal Models
Jan 13, 2025Previous work on augmenting large multimodal models (LMMs) for text-to-image (T2I) generation has focused on enriching the input space of in-context learning (ICL). This includes providing a few demonstrations and optimizing image descriptions to be more detailed and logical. However, as demand for more complex and flexible image descriptions grows, enhancing comprehension of input text within the ICL paradigm remains a critical yet underexplored area. In this work, we extend this line of research by constructing parallel multilingual prompts aimed at harnessing the multilingual capabilities of LMMs. More specifically, we translate the input text into several languages and provide the models with both the original text and the translations. Experiments on two LMMs across 3 benchmarks show that our method, PMT2I, achieves superior performance in general, compositional, and fine-grained assessments, especially in human preference alignment. Additionally, with its advantage of generating more diverse images, PMT2I significantly outperforms baseline prompts when incorporated with reranking methods. Our code and parallel multilingual data can be found at https://github.com/takagi97/PMT2I.
Cross-layer Attention Sharing for Large Language Models
Aug 04, 2024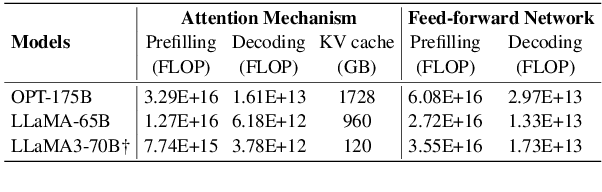
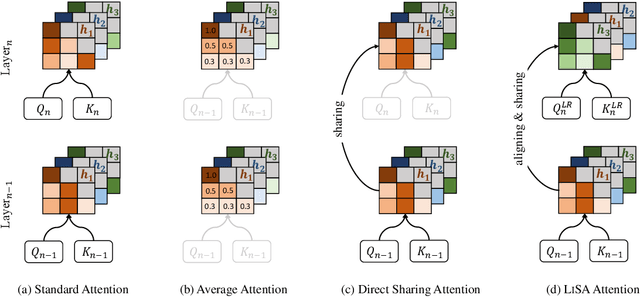
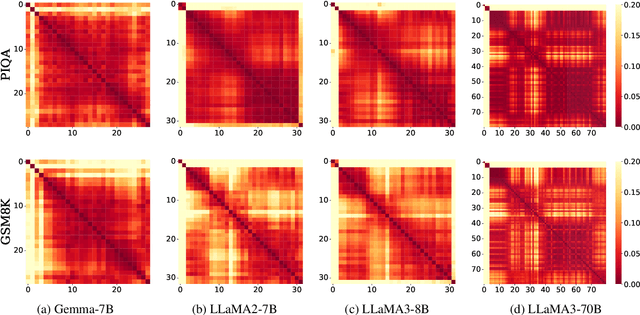
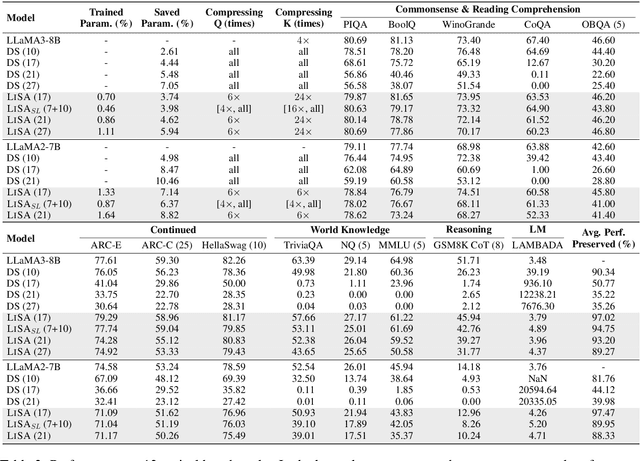
As large language models (LLMs) evolve, the increase in model depth and parameter number leads to substantial redundancy. To enhance the efficiency of the attention mechanism, previous works primarily compress the KV cache or group attention heads, while largely overlooking redundancy between layers. Our comprehensive analyses across various LLMs show that highly similar attention patterns persist within most layers. It's intuitive to save the computation by sharing attention weights across layers. However, further analysis reveals two challenges: (1) Directly sharing the weight matrix without carefully rearranging the attention heads proves to be ineffective; (2) Shallow layers are vulnerable to small deviations in attention weights. Driven by these insights, we introduce LiSA, a lightweight substitute for self-attention in well-trained LLMs. LiSA employs tiny feed-forward networks to align attention heads between adjacent layers and low-rank matrices to approximate differences in layer-wise attention weights. Evaluations encompassing 13 typical benchmarks demonstrate that LiSA maintains high response quality in terms of accuracy and perplexity while reducing redundant attention calculations within 53-84% of the total layers. Our implementations of LiSA achieve a 6X compression of Q and K, with maximum throughput improvements of 19.5% for LLaMA3-8B and 32.3% for LLaMA2-7B.
Refining Self-Supervised Learnt Speech Representation using Brain Activations
Jun 12, 2024



It was shown in literature that speech representations extracted by self-supervised pre-trained models exhibit similarities with brain activations of human for speech perception and fine-tuning speech representation models on downstream tasks can further improve the similarity. However, it still remains unclear if this similarity can be used to optimize the pre-trained speech models. In this work, we therefore propose to use the brain activations recorded by fMRI to refine the often-used wav2vec2.0 model by aligning model representations toward human neural responses. Experimental results on SUPERB reveal that this operation is beneficial for several downstream tasks, e.g., speaker verification, automatic speech recognition, intent classification.One can then consider the proposed method as a new alternative to improve self-supervised speech models.
A Novel Method for Extrinsic Calibration of Multiple RGB-D Cameras Using Descriptor-Based Patterns
Sep 10, 2018



This letter presents a novel method to estimate the relative poses between RGB-D cameras with minimal overlapping fields of view in a panoramic RGB-D camera system. This calibration problem is relevant to applications such as indoor 3D mapping and robot navigation that can benefit from a 360$^\circ$ field of view using RGB-D cameras. The proposed approach relies on descriptor-based patterns to provide well-matched 2D keypoints in the case of a minimal overlapping field of view between cameras. Integrating the matched 2D keypoints with corresponding depth values, a set of 3D matched keypoints are constructed to calibrate multiple RGB-D cameras. Experiments validated the accuracy and efficiency of the proposed calibration approach, both superior to those of existing methods (800 ms vs. 5 seconds; rotation error of 0.56 degrees vs. 1.6 degrees; and translation error of 1.80 cm vs. 2.5 cm.
Construction of all-in-focus images assisted by depth sensing
Jun 05, 2018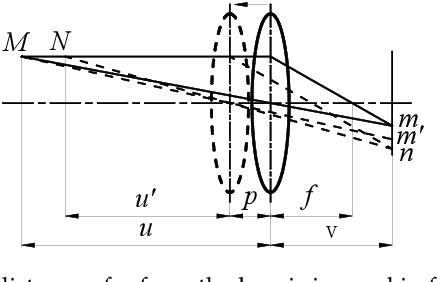


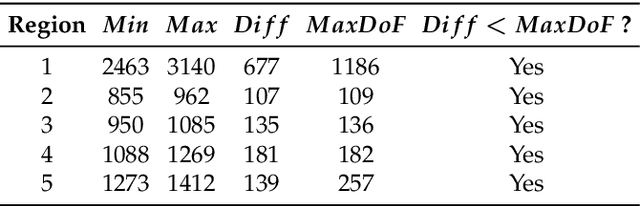
Multi-focus image fusion is a technique for obtaining an all-in-focus image in which all objects are in focus to extend the limited depth of field (DoF) of an imaging system. Different from traditional RGB-based methods, this paper presents a new multi-focus image fusion method assisted by depth sensing. In this work, a depth sensor is used together with a color camera to capture images of a scene. A graph-based segmentation algorithm is used to segment the depth map from the depth sensor, and the segmented regions are used to guide a focus algorithm to locate in-focus image blocks from among multi-focus source images to construct the reference all-in-focus image. Five test scenes and six evaluation metrics were used to compare the proposed method and representative state-of-the-art algorithms. Experimental results quantitatively demonstrate that this method outperforms existing methods in both speed and quality (in terms of comprehensive fusion metrics). The generated images can potentially be used as reference all-in-focus images.