 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalGeo: The First Step Toward Human-like IMO-level Geometric Automated Reasoning
Oct 30, 2023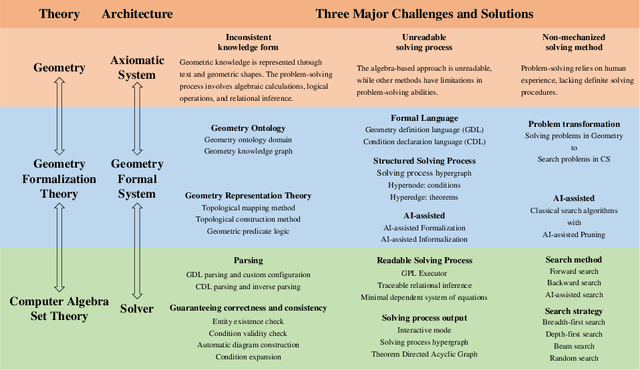
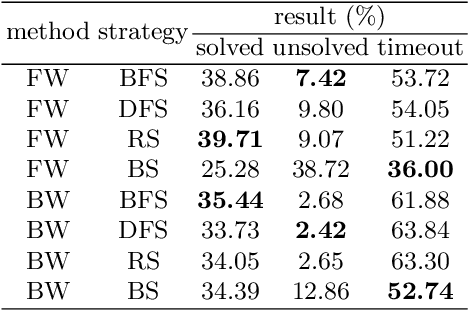
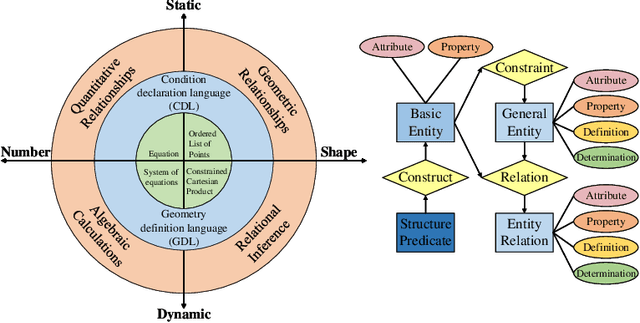
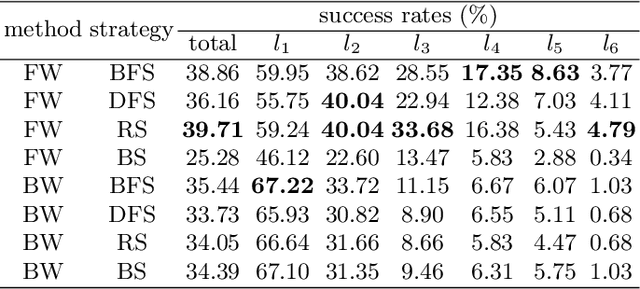
This is the first paper in a series of work we have accomplished over the past three years. In this paper, we have constructed a complete and compatible formal plane geometry system. This will serve as a crucial bridge between IMO-level plane geometry challenges and readable AI automated reasoning. With this formal system in place, we have been able to seamlessly integrate modern AI models with our formal system. Within this formal framework, AI is now capable of providing deductive reasoning solutions to IMO-level plane geometry problems, just like handling other natural languages, and these proofs are readable, traceable, and verifiable. We propose the geometry formalization theory (GFT) to guide the development of the geometry formal system. Based on the GFT, we have established the FormalGeo, which consists of 88 geometric predicates and 196 theorems. It can represent, validate, and solve IMO-level geometry problems. we also have crafted the FGPS (formal geometry problem solver) in Python. It serves as both an interactive assistant for verifying problem-solving processes and an automated problem solver, utilizing various methods such as forward search, backward search and AI-assisted search. We've annotated the FormalGeo7k dataset, containing 6,981 (expand to 186,832 through data augmentation) geometry problems with complete formal language annotations. Implementation of the formal system and experiments on the FormalGeo7k validate the correctness and utility of the GFT. The backward depth-first search method only yields a 2.42% problem-solving failure rate, and we can incorporate deep learning techniques to achieve lower one. The source code of FGPS and FormalGeo7k dataset are available at https://github.com/BitSecret/FormalGeo.
Open-World Object Detection via Discriminative Class Prototype Learning
Feb 23, 2023



Open-world object detection (OWOD) is a challenging problem that combines object detection with incremental learning and open-set learning. Compared to standard object detection, the OWOD setting is task to: 1) detect objects seen during training while identifying unseen classes, and 2) incrementally learn the knowledge of the identified unknown objects when the corresponding annotations is available. We propose a novel and efficient OWOD solution from a prototype perspective, which we call OCPL: Open-world object detection via discriminative Class Prototype Learning, which consists of a Proposal Embedding Aggregator (PEA), an Embedding Space Compressor (ESC) and a Cosine Similarity-based Classifier (CSC). All our proposed modules aim to learn the discriminative embeddings of known classes in the feature space to minimize the overlapping distributions of known and unknown classes, which is beneficial to differentiate known and unknown classes. Extensive experiments performed on PASCAL VOC and MS-COCO benchmark demonstrate the effectiveness of our proposed method.
* 4 pages, 3 figures, ICIP2022
Learning Discriminative Representations for Fine-Grained Diabetic Retinopathy Grading
Nov 04, 2020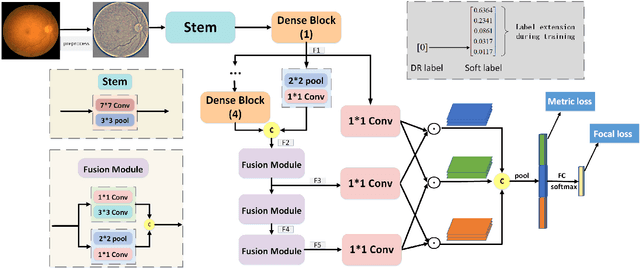
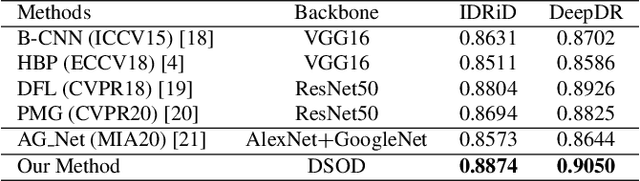
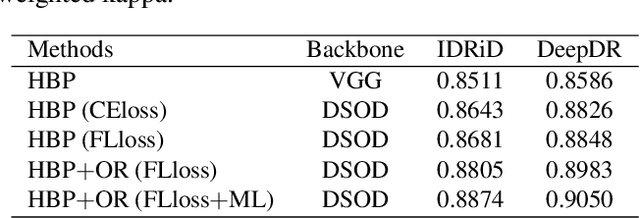
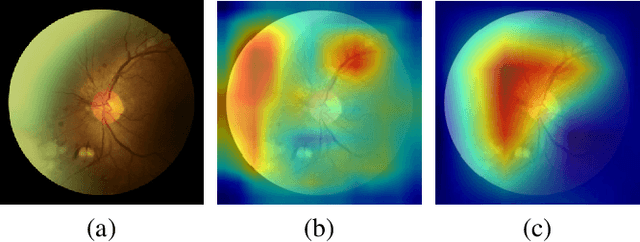
Diabetic retinopathy (DR) is one of the leading causes of blindness. However, no specific symptoms of early DR lead to a delayed diagnosis, which results in disease progression in patients. To determine the disease severity levels, ophthalmologists need to focus on the discriminative parts of the fundus images. In recent years, deep learning has achieved great success in medical image analysis. However, most works directly employ algorithms based on convolutional neural networks (CNNs), which ignore the fact that the difference among classes is subtle and gradual. Hence, we consider automatic image grading of DR as a fine-grained classification task, and construct a bilinear model to identify the pathologically discriminative areas. In order to leverage the ordinal information among classes, we use an ordinal regression method to obtain the soft labels. In addition, other than only using a categorical loss to train our network, we also introduce the metric loss to learn a more discriminative feature space. Experimental results demonstrate the superior performance of the proposed method on two public IDRiD and DeepDR datasets.
Proximal Policy Optimization with Mixed Distributed Training
Sep 08, 2019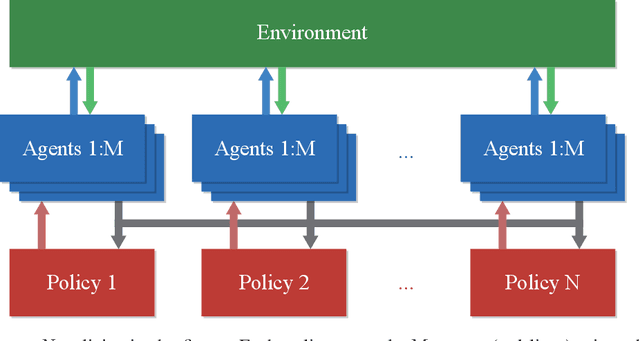
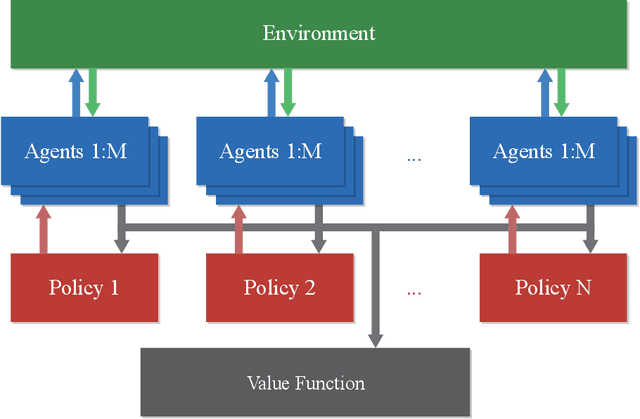

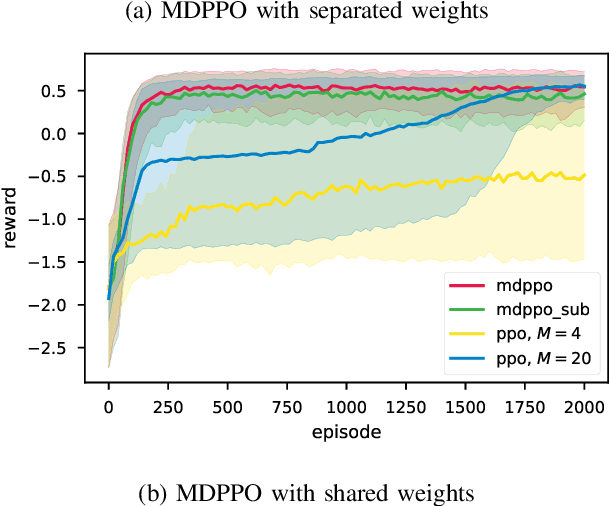
Instability and slowness are two main problems in deep reinforcement learning. Even if proximal policy optimization (PPO) is the state of the art, it still suffers from these two problems. We introduce an improved algorithm based on proximal policy optimization, mixed distributed proximal policy optimization (MDPPO), and show that it can accelerate and stabilize the training process. In our algorithm, multiple different policies train simultaneously and each of them controls several identical agents that interact with environments. Actions are sampled by each policy separately as usual, but the trajectories for the training process are collected from all agents, instead of only one policy. We find that if we choose some auxiliary trajectories elaborately to train policies, the algorithm will be more stable and quicker to converge especially in the environments with sparse rewards.
A Novel Method for Extrinsic Calibration of Multiple RGB-D Cameras Using Descriptor-Based Patterns
Sep 10, 2018



This letter presents a novel method to estimate the relative poses between RGB-D cameras with minimal overlapping fields of view in a panoramic RGB-D camera system. This calibration problem is relevant to applications such as indoor 3D mapping and robot navigation that can benefit from a 360$^\circ$ field of view using RGB-D cameras. The proposed approach relies on descriptor-based patterns to provide well-matched 2D keypoints in the case of a minimal overlapping field of view between cameras. Integrating the matched 2D keypoints with corresponding depth values, a set of 3D matched keypoints are constructed to calibrate multiple RGB-D cameras. Experiments validated the accuracy and efficiency of the proposed calibration approach, both superior to those of existing methods (800 ms vs. 5 seconds; rotation error of 0.56 degrees vs. 1.6 degrees; and translation error of 1.80 cm vs. 2.5 cm.
Construction of all-in-focus images assisted by depth sensing
Jun 05, 2018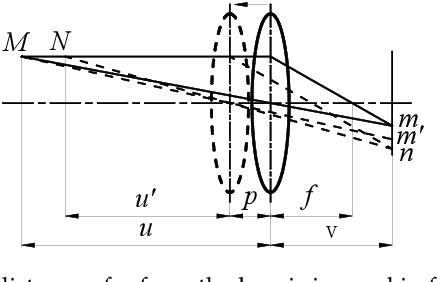


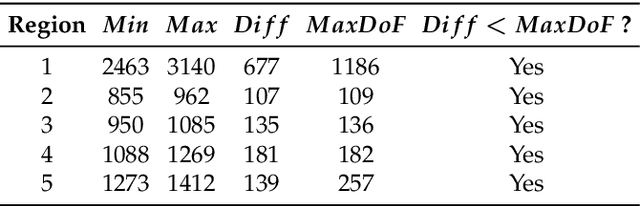
Multi-focus image fusion is a technique for obtaining an all-in-focus image in which all objects are in focus to extend the limited depth of field (DoF) of an imaging system. Different from traditional RGB-based methods, this paper presents a new multi-focus image fusion method assisted by depth sensing. In this work, a depth sensor is used together with a color camera to capture images of a scene. A graph-based segmentation algorithm is used to segment the depth map from the depth sensor, and the segmented regions are used to guide a focus algorithm to locate in-focus image blocks from among multi-focus source images to construct the reference all-in-focus image. Five test scenes and six evaluation metrics were used to compare the proposed method and representative state-of-the-art algorithms. Experimental results quantitatively demonstrate that this method outperforms existing methods in both speed and quality (in terms of comprehensive fusion metrics). The generated images can potentially be used as reference all-in-focus images.