 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPT-PAR:Mix-Parameters Transformer for Panoramic Activity Recognition
Aug 01, 2024



The objective of the panoramic activity recognition task is to identify behaviors at various granularities within crowded and complex environments, encompassing individual actions, social group activities, and global activities. Existing methods generally use either parameter-independent modules to capture task-specific features or parameter-sharing modules to obtain common features across all tasks. However, there is often a strong interrelatedness and complementary effect between tasks of different granularities that previous methods have yet to notice. In this paper, we propose a model called MPT-PAR that considers both the unique characteristics of each task and the synergies between different tasks simultaneously, thereby maximizing the utilization of features across multi-granularity activity recognition. Furthermore, we emphasize the significance of temporal and spatial information by introducing a spatio-temporal relation-enhanced module and a scene representation learning module, which integrate the the spatio-temporal context of action and global scene into the feature map of each granularity. Our method achieved an overall F1 score of 47.5\% on the JRDB-PAR dataset, significantly outperforming all the state-of-the-art methods.
FormalGeo: The First Step Toward Human-like IMO-level Geometric Automated Reasoning
Oct 30, 2023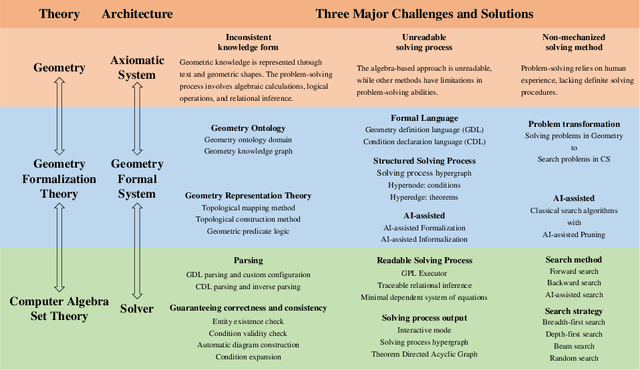
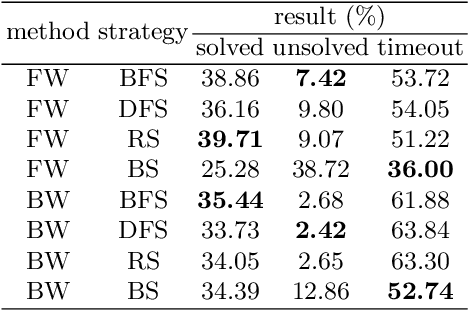
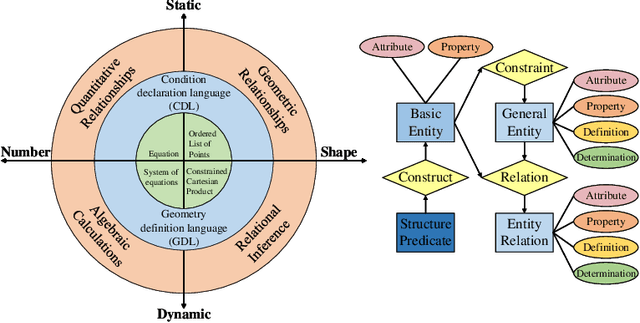
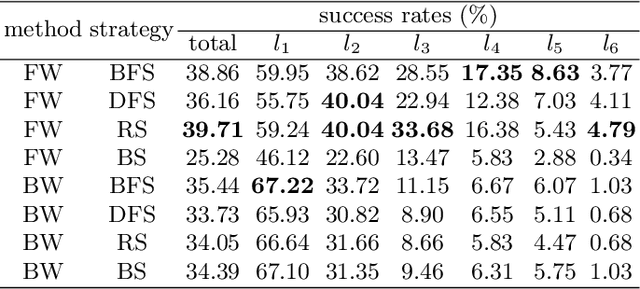
This is the first paper in a series of work we have accomplished over the past three years. In this paper, we have constructed a complete and compatible formal plane geometry system. This will serve as a crucial bridge between IMO-level plane geometry challenges and readable AI automated reasoning. With this formal system in place, we have been able to seamlessly integrate modern AI models with our formal system. Within this formal framework, AI is now capable of providing deductive reasoning solutions to IMO-level plane geometry problems, just like handling other natural languages, and these proofs are readable, traceable, and verifiable. We propose the geometry formalization theory (GFT) to guide the development of the geometry formal system. Based on the GFT, we have established the FormalGeo, which consists of 88 geometric predicates and 196 theorems. It can represent, validate, and solve IMO-level geometry problems. we also have crafted the FGPS (formal geometry problem solver) in Python. It serves as both an interactive assistant for verifying problem-solving processes and an automated problem solver, utilizing various methods such as forward search, backward search and AI-assisted search. We've annotated the FormalGeo7k dataset, containing 6,981 (expand to 186,832 through data augmentation) geometry problems with complete formal language annotations. Implementation of the formal system and experiments on the FormalGeo7k validate the correctness and utility of the GFT. The backward depth-first search method only yields a 2.42% problem-solving failure rate, and we can incorporate deep learning techniques to achieve lower one. The source code of FGPS and FormalGeo7k dataset are available at https://github.com/BitSecret/FormalGeo.
Back to Prior Knowledge: Joint Event Causality Extraction via Convolutional Semantic Infusion
Feb 19, 2021



Joint event and causality extraction is a challenging yet essential task in information retrieval and data mining. Recently, pre-trained language models (e.g., BERT) yield state-of-the-art results and dominate in a variety of NLP tasks. However, these models are incapable of imposing external knowledge in domain-specific extraction. Considering the prior knowledge of frequent n-grams that represent cause/effect events may benefit both event and causality extraction, in this paper, we propose convolutional knowledge infusion for frequent n-grams with different windows of length within a joint extraction framework. Knowledge infusion during convolutional filter initialization not only helps the model capture both intra-event (i.e., features in an event cluster) and inter-event (i.e., associations across event clusters) features but also boosts training convergence. Experimental results on the benchmark datasets show that our model significantly outperforms the strong BERT+CSNN baseline.
A Targeted Universal Attack on Graph Convolutional Network
Nov 29, 2020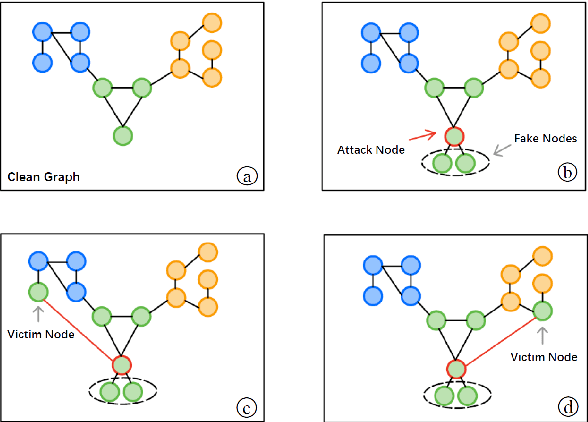

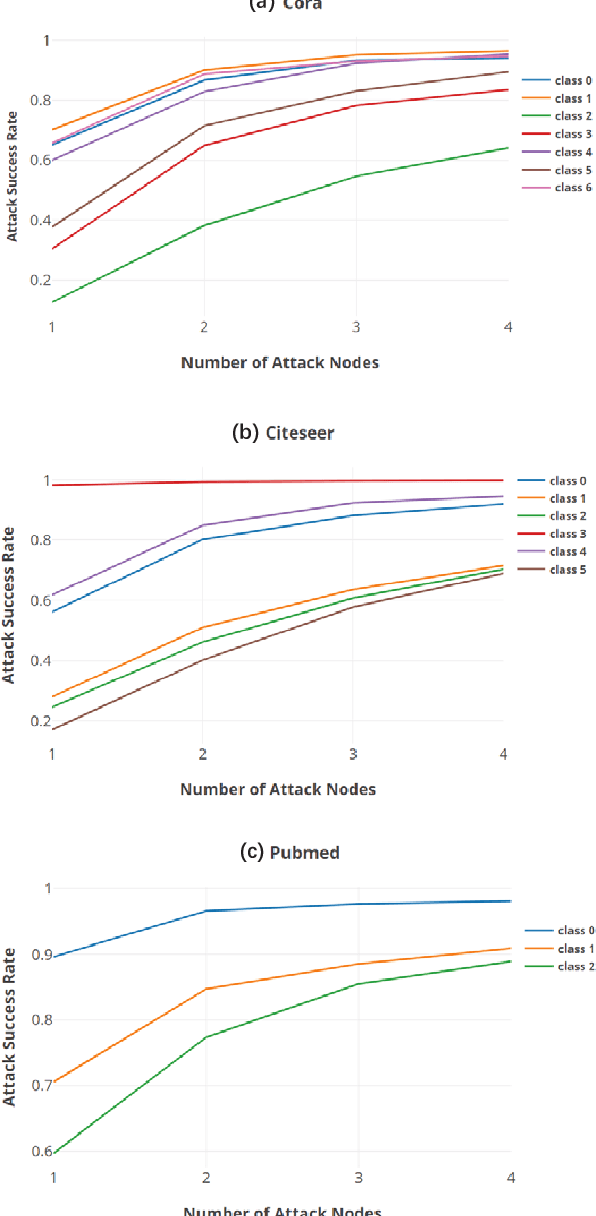
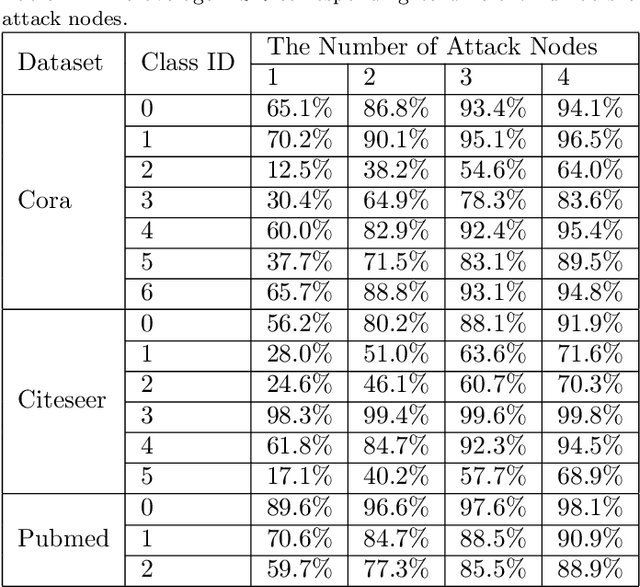
Graph-structured data exist in numerous applications in real life. As a state-of-the-art graph neural network, the graph convolutional network (GCN) plays an important role in processing graph-structured data. However, a recent study reported that GCNs are also vulnerable to adversarial attacks, which means that GCN models may suffer malicious attacks with unnoticeable modifications of the data. Among all the adversarial attacks on GCNs, there is a special kind of attack method called the universal adversarial attack, which generates a perturbation that can be applied to any sample and causes GCN models to output incorrect results. Although universal adversarial attacks in computer vision have been extensively researched, there are few research works on universal adversarial attacks on graph structured data. In this paper, we propose a targeted universal adversarial attack against GCNs. Our method employs a few nodes as the attack nodes. The attack capability of the attack nodes is enhanced through a small number of fake nodes connected to them. During an attack, any victim node will be misclassified by the GCN as the attack node class as long as it is linked to them. The experiments on three popular datasets show that the average attack success rate of the proposed attack on any victim node in the graph reaches 83% when using only 3 attack nodes and 6 fake nodes. We hope that our work will make the community aware of the threat of this type of attack and raise the attention given to its future defense.
Emotion Correlation Mining Through Deep Learning Models on Natural Language Text
Jul 28, 2020


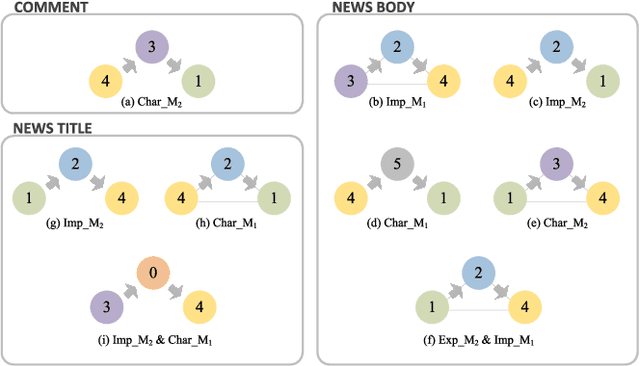
Emotion analysis has been attracting researchers' attention. Most previous works in the artificial intelligence field focus on recognizing emotion rather than mining the reason why emotions are not or wrongly recognized. Correlation among emotions contributes to the failure of emotion recognition. In this paper, we try to fill the gap between emotion recognition and emotion correlation mining through natural language text from web news. Correlation among emotions, expressed as the confusion and evolution of emotion, is primarily caused by human emotion cognitive bias. To mine emotion correlation from emotion recognition through text, three kinds of features and two deep neural network models are presented. The emotion confusion law is extracted through orthogonal basis. The emotion evolution law is evaluated from three perspectives, one-step shift, limited-step shifts, and shortest path transfer. The method is validated using three datasets-the titles, the bodies, and the comments of news articles, covering both objective and subjective texts in varying lengths (long and short). The experimental results show that, in subjective comments, emotions are easily mistaken as anger. Comments tend to arouse emotion circulations of love-anger and sadness-anger. In objective news, it is easy to recognize text emotion as love and cause fear-joy circulation. That means, journalists may try to attract attention using fear and joy words but arouse the emotion love instead; After news release, netizens generate emotional comments to express their intense emotions, i.e., anger, sadness, and love. These findings could provide insights for applications regarding affective interaction such as network public sentiment, social media communication, and human-computer interaction.
Enhancing Relation Extraction Using Syntactic Indicators and Sentential Contexts
Dec 04, 2019

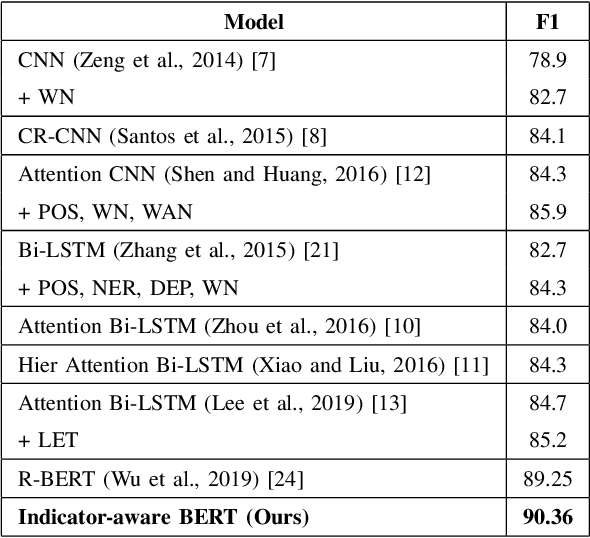

State-of-the-art methods for relation extraction consider the sentential context by modeling the entire sentence. However, syntactic indicators, certain phrases or words like prepositions that are more informative than other words and may be beneficial for identifying semantic relations. Other approaches using fixed text triggers capture such information but ignore the lexical diversity. To leverage both syntactic indicators and sentential contexts, we propose an indicator-aware approach for relation extraction. Firstly, we extract syntactic indicators under the guidance of syntactic knowledge. Then we construct a neural network to incorporate both syntactic indicators and the entire sentences into better relation representations. By this way, the proposed model alleviates the impact of noisy information from entire sentences and breaks the limit of text triggers. Experiments on the SemEval-2010 Task 8 benchmark dataset show that our model significantly outperforms the state-of-the-art methods.
Proximal Policy Optimization with Mixed Distributed Training
Sep 08, 2019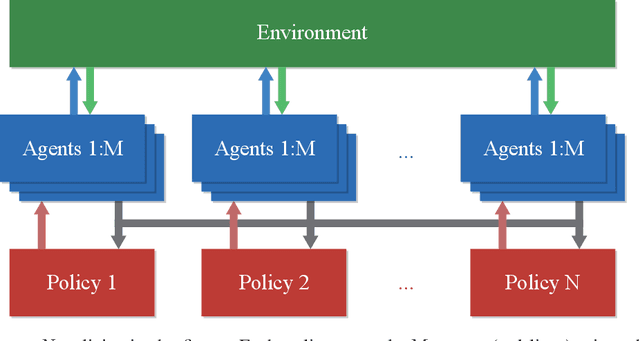
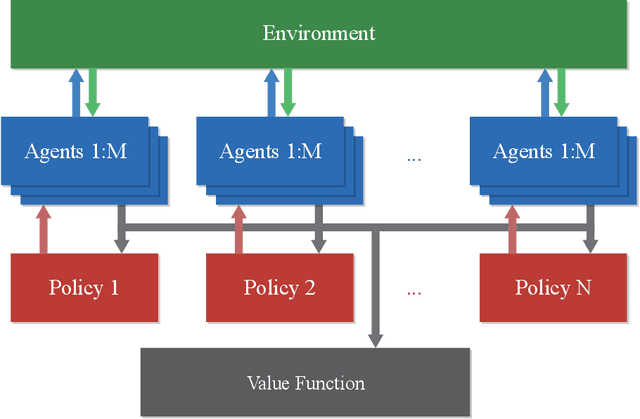

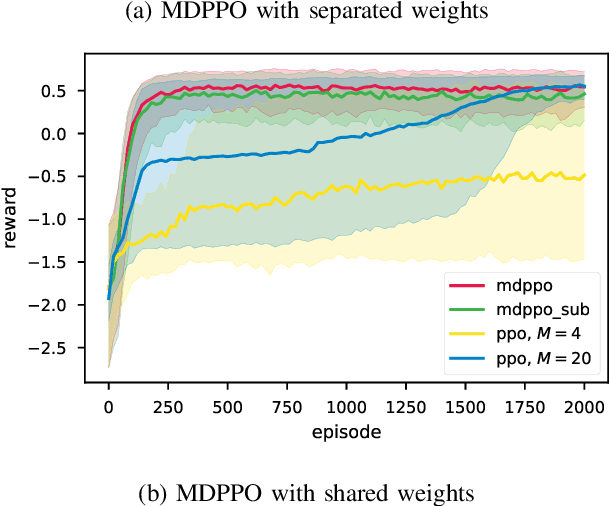
Instability and slowness are two main problems in deep reinforcement learning. Even if proximal policy optimization (PPO) is the state of the art, it still suffers from these two problems. We introduce an improved algorithm based on proximal policy optimization, mixed distributed proximal policy optimization (MDPPO), and show that it can accelerate and stabilize the training process. In our algorithm, multiple different policies train simultaneously and each of them controls several identical agents that interact with environments. Actions are sampled by each policy separately as usual, but the trajectories for the training process are collected from all agents, instead of only one policy. We find that if we choose some auxiliary trajectories elaborately to train policies, the algorithm will be more stable and quicker to converge especially in the environments with sparse rewards.
Dependent Indian Buffet Process-based Sparse Nonparametric Nonnegative Matrix Factorization
Jul 12, 2015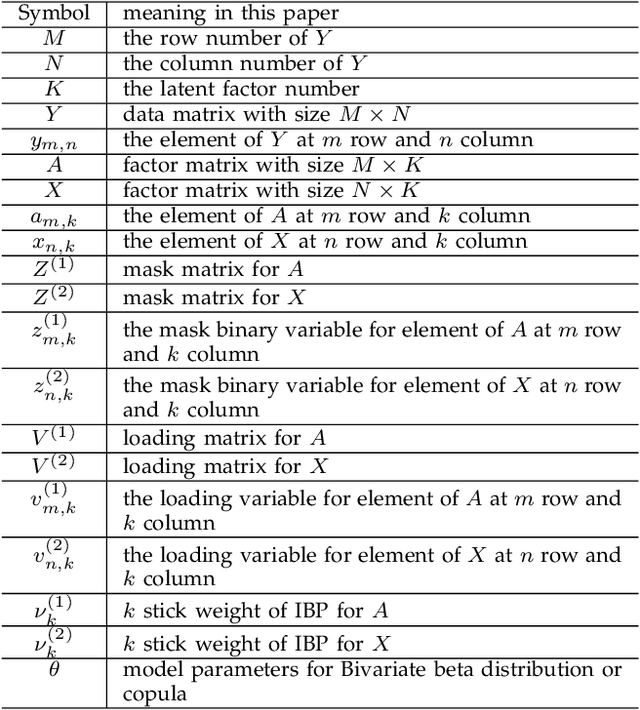


Nonnegative Matrix Factorization (NMF) aims to factorize a matrix into two optimized nonnegative matrices appropriate for the intended applications. The method has been widely used for unsupervised learning tasks, including recommender systems (rating matrix of users by items) and document clustering (weighting matrix of papers by keywords). However, traditional NMF methods typically assume the number of latent factors (i.e., dimensionality of the loading matrices) to be fixed. This assumption makes them inflexible for many applications. In this paper, we propose a nonparametric NMF framework to mitigate this issue by using dependent Indian Buffet Processes (dIBP). In a nutshell, we apply a correlation function for the generation of two stick weights associated with each pair of columns of loading matrices, while still maintaining their respective marginal distribution specified by IBP. As a consequence, the generation of two loading matrices will be column-wise (indirectly) correlated. Under this same framework, two classes of correlation function are proposed (1) using Bivariate beta distribution and (2) using Copula function. Both methods allow us to adopt our work for various applications by flexibly choosing an appropriate parameter settings. Compared with the other state-of-the art approaches in this area, such as using Gaussian Process (GP)-based dIBP, our work is seen to be much more flexible in terms of allowing the two corresponding binary matrix columns to have greater variations in their non-zero entries. Our experiments on the real-world and synthetic datasets show that three proposed models perform well on the document clustering task comparing standard NMF without predefining the dimension for the factor matrices, and the Bivariate beta distribution-based and Copula-based models have better flexibility than the GP-based model.
Nonparametric Relational Topic Models through Dependent Gamma Processes
Mar 30, 2015
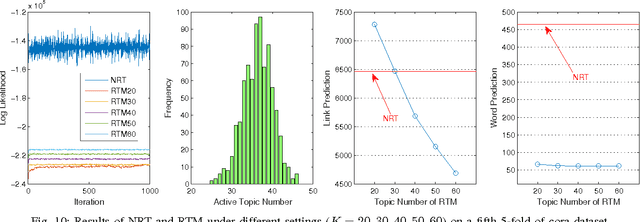

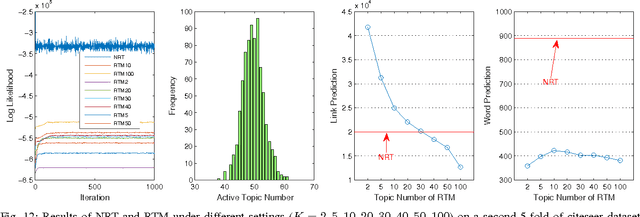
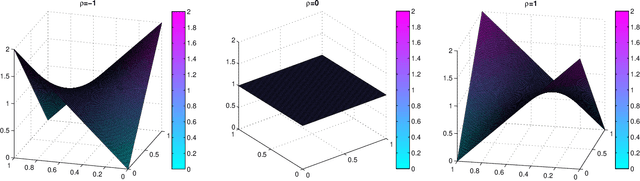
Traditional Relational Topic Models provide a way to discover the hidden topics from a document network. Many theoretical and practical tasks, such as dimensional reduction, document clustering, link prediction, benefit from this revealed knowledge. However, existing relational topic models are based on an assumption that the number of hidden topics is known in advance, and this is impractical in many real-world applications. Therefore, in order to relax this assumption, we propose a nonparametric relational topic model in this paper. Instead of using fixed-dimensional probability distributions in its generative model, we use stochastic processes. Specifically, a gamma process is assigned to each document, which represents the topic interest of this document. Although this method provides an elegant solution, it brings additional challenges when mathematically modeling the inherent network structure of typical document network, i.e., two spatially closer documents tend to have more similar topics. Furthermore, we require that the topics are shared by all the documents. In order to resolve these challenges, we use a subsampling strategy to assign each document a different gamma process from the global gamma process, and the subsampling probabilities of documents are assigned with a Markov Random Field constraint that inherits the document network structure. Through the designed posterior inference algorithm, we can discover the hidden topics and its number simultaneously. Experimental results on both synthetic and real-world network datasets demonstrate the capabilities of learning the hidden topics and, more importantly, the number of topics.
Infinite Author Topic Model based on Mixed Gamma-Negative Binomial Process
Mar 30, 2015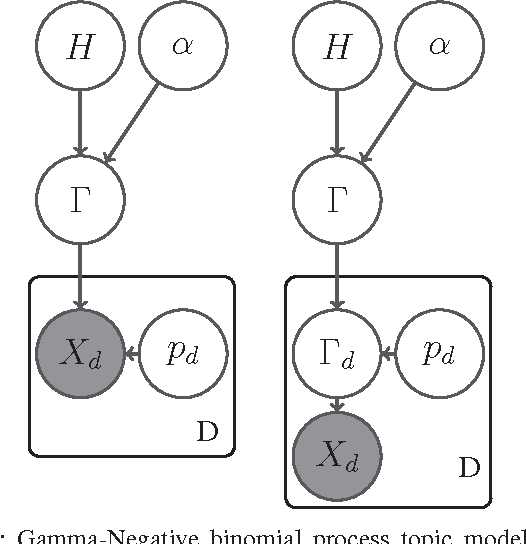


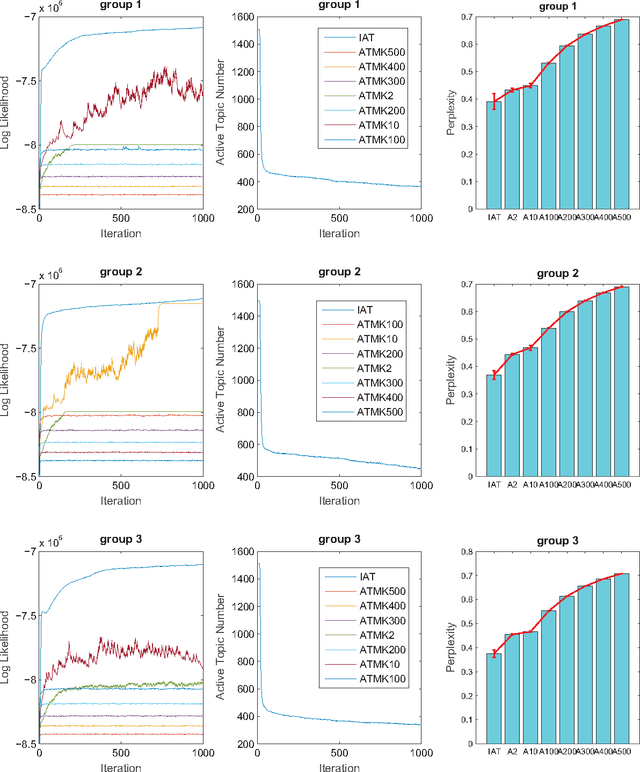
Incorporating the side information of text corpus, i.e., authors, time stamps, and emotional tags, into the traditional text mining models has gained significant interests in the area of information retrieval, statistical natural language processing, and machine learning. One branch of these works is the so-called Author Topic Model (ATM), which incorporates the authors's interests as side information into the classical topic model. However, the existing ATM needs to predefine the number of topics, which is difficult and inappropriate in many real-world settings. In this paper, we propose an Infinite Author Topic (IAT) model to resolve this issue. Instead of assigning a discrete probability on fixed number of topics, we use a stochastic process to determine the number of topics from the data itself. To be specific, we extend a gamma-negative binomial process to three levels in order to capture the author-document-keyword hierarchical structure. Furthermore, each document is assigned a mixed gamma process that accounts for the multi-author's contribution towards this document. An efficient Gibbs sampling inference algorithm with each conditional distribution being closed-form is developed for the IAT model. Experiments on several real-world datasets show the capabilities of our IAT model to learn the hidden topics, authors' interests on these topics and the number of topics simultaneously.