 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDependent Indian Buffet Process-based Sparse Nonparametric Nonnegative Matrix Factorization
Paper and Code
Jul 12, 2015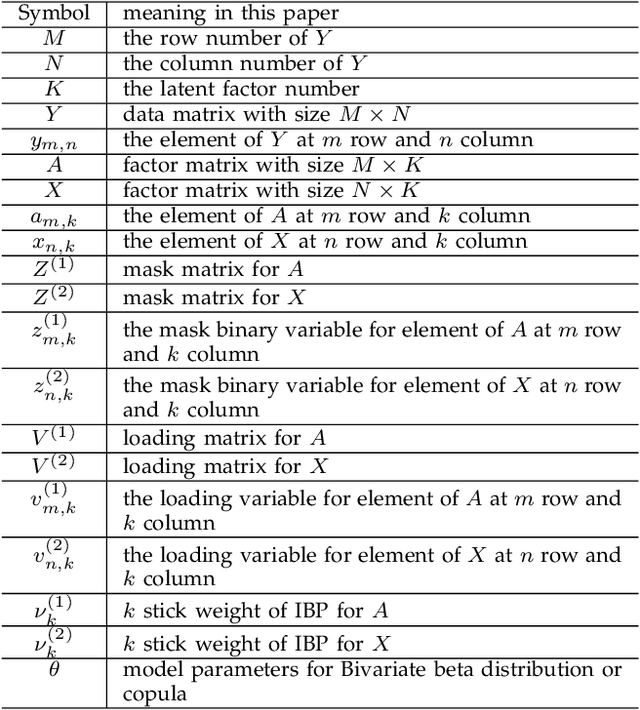


Nonnegative Matrix Factorization (NMF) aims to factorize a matrix into two optimized nonnegative matrices appropriate for the intended applications. The method has been widely used for unsupervised learning tasks, including recommender systems (rating matrix of users by items) and document clustering (weighting matrix of papers by keywords). However, traditional NMF methods typically assume the number of latent factors (i.e., dimensionality of the loading matrices) to be fixed. This assumption makes them inflexible for many applications. In this paper, we propose a nonparametric NMF framework to mitigate this issue by using dependent Indian Buffet Processes (dIBP). In a nutshell, we apply a correlation function for the generation of two stick weights associated with each pair of columns of loading matrices, while still maintaining their respective marginal distribution specified by IBP. As a consequence, the generation of two loading matrices will be column-wise (indirectly) correlated. Under this same framework, two classes of correlation function are proposed (1) using Bivariate beta distribution and (2) using Copula function. Both methods allow us to adopt our work for various applications by flexibly choosing an appropriate parameter settings. Compared with the other state-of-the art approaches in this area, such as using Gaussian Process (GP)-based dIBP, our work is seen to be much more flexible in terms of allowing the two corresponding binary matrix columns to have greater variations in their non-zero entries. Our experiments on the real-world and synthetic datasets show that three proposed models perform well on the document clustering task comparing standard NMF without predefining the dimension for the factor matrices, and the Bivariate beta distribution-based and Copula-based models have better flexibility than the GP-based model.