 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Source Knowledge Selection in Multi-Domain Adaptation
Dec 08, 2025Unsupervised multi-domain adaptation plays a key role in transfer learning by leveraging acquired rich source information from multiple source domains to solve target task from an unlabeled target domain. However, multiple source domains often contain much redundant or unrelated information which can harm transfer performance, especially when in massive-source domain settings. It is urgent to develop effective strategies for identifying and selecting the most transferable knowledge from massive source domains to address the target task. In this paper, we propose a multi-domain adaptation method named \underline{\textit{Auto}}nomous Source Knowledge \underline{\textit{S}}election (AutoS) to autonomosly select source training samples and models, enabling the prediction of target task using more relevant and transferable source information. The proposed method employs a density-driven selection strategy to choose source samples during training and to determine which source models should contribute to target prediction. Simulteneously, a pseudo-label enhancement module built on a pre-trained multimodal modal is employed to mitigate target label noise and improve self-supervision. Experiments on real-world datasets indicate the superiority of the proposed method.
SPAD: Seven-Source Token Probability Attribution with Syntactic Aggregation for Detecting Hallucinations in RAG
Dec 08, 2025Detecting hallucinations in Retrieval-Augmented Generation (RAG) remains a challenge. Prior approaches attribute hallucinations to a binary conflict between internal knowledge (stored in FFNs) and retrieved context. However, this perspective is incomplete, failing to account for the impact of other components in the generative process, such as the user query, previously generated tokens, the current token itself, and the final LayerNorm adjustment. To address this, we introduce SPAD. First, we mathematically attribute each token's probability into seven distinct sources: Query, RAG, Past, Current Token, FFN, Final LayerNorm, and Initial Embedding. This attribution quantifies how each source contributes to the generation of the current token. Then, we aggregate these scores by POS tags to quantify how different components drive specific linguistic categories. By identifying anomalies, such as Nouns relying on Final LayerNorm, SPAD effectively detects hallucinations. Extensive experiments demonstrate that SPAD achieves state-of-the-art performance
Autonomous Concept Drift Threshold Determination
Nov 13, 2025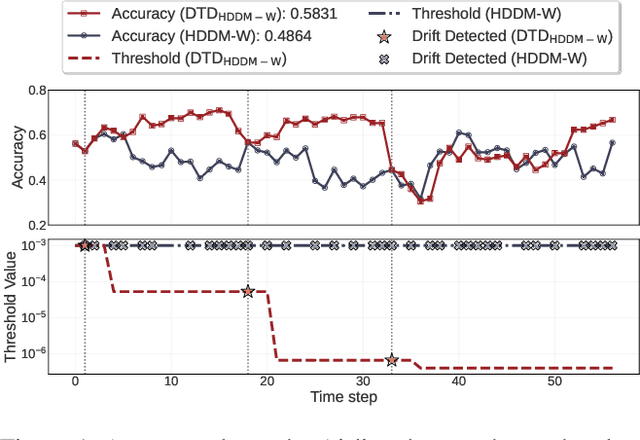
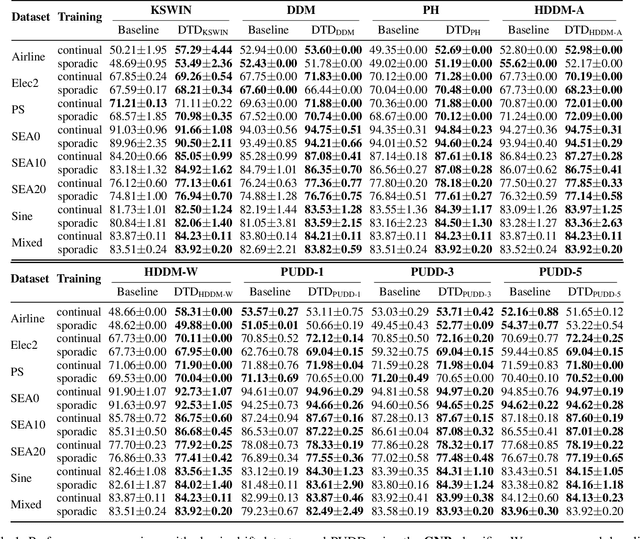
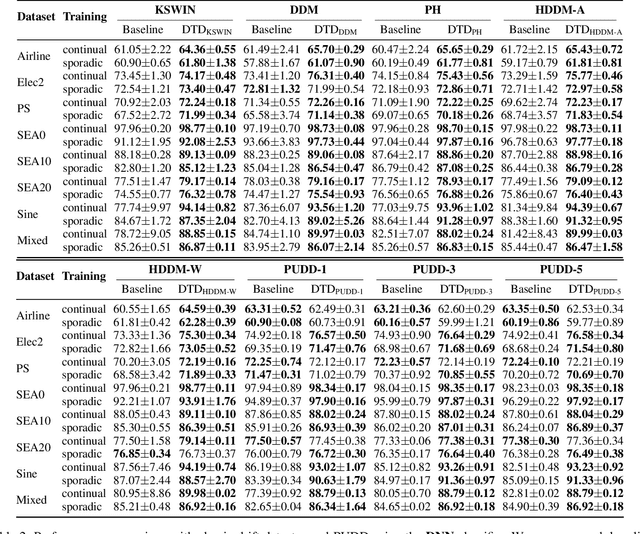
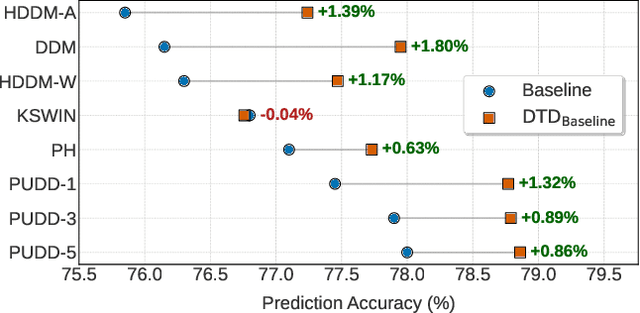
Existing drift detection methods focus on designing sensitive test statistics. They treat the detection threshold as a fixed hyperparameter, set once to balance false alarms and late detections, and applied uniformly across all datasets and over time. However, maintaining model performance is the key objective from the perspective of machine learning, and we observe that model performance is highly sensitive to this threshold. This observation inspires us to investigate whether a dynamic threshold could be provably better. In this paper, we prove that a threshold that adapts over time can outperform any single fixed threshold. The main idea of the proof is that a dynamic strategy, constructed by combining the best threshold from each individual data segment, is guaranteed to outperform any single threshold that apply to all segments. Based on the theorem, we propose a Dynamic Threshold Determination algorithm. It enhances existing drift detection frameworks with a novel comparison phase to inform how the threshold should be adjusted. Extensive experiments on a wide range of synthetic and real-world datasets, including both image and tabular data, validate that our approach substantially enhances the performance of state-of-the-art drift detectors.
Generalized Incremental Learning under Concept Drift across Evolving Data Streams
Jun 06, 2025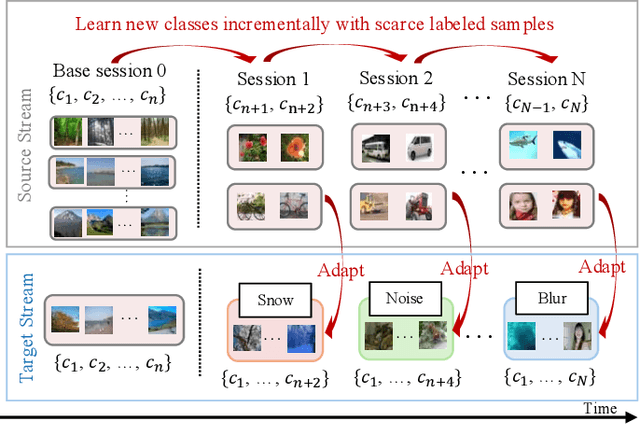
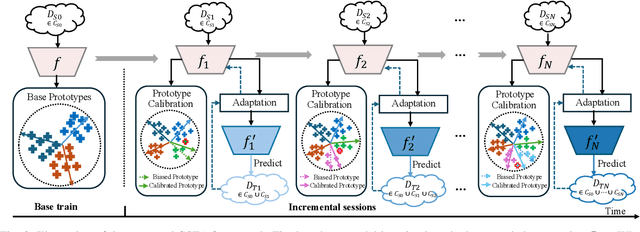
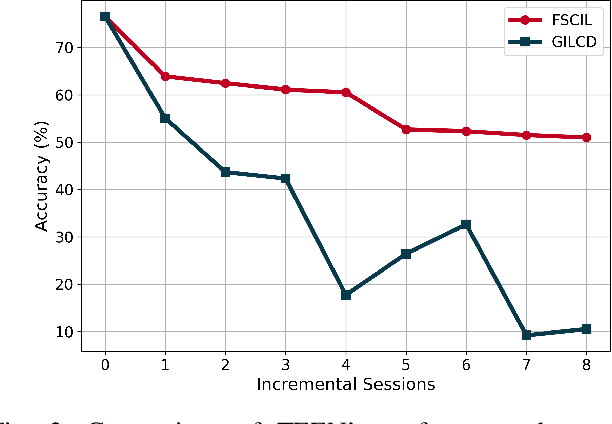
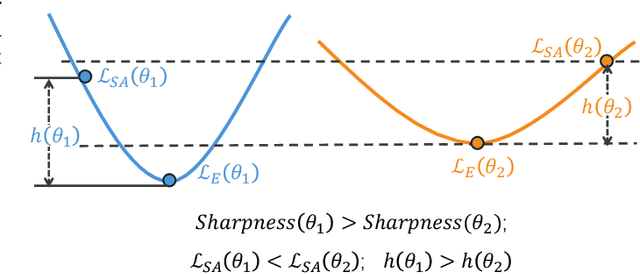
Real-world data streams exhibit inherent non-stationarity characterized by concept drift, posing significant challenges for adaptive learning systems. While existing methods address isolated distribution shifts, they overlook the critical co-evolution of label spaces and distributions under limited supervision and persistent uncertainty. To address this, we formalize Generalized Incremental Learning under Concept Drift (GILCD), characterizing the joint evolution of distributions and label spaces in open-environment streaming contexts, and propose a novel framework called Calibrated Source-Free Adaptation (CSFA). First, CSFA introduces a training-free prototype calibration mechanism that dynamically fuses emerging prototypes with base representations, enabling stable new-class identification without optimization overhead. Second, we design a novel source-free adaptation algorithm, i.e., Reliable Surrogate Gap Sharpness-aware (RSGS) minimization. It integrates sharpness-aware perturbation loss optimization with surrogate gap minimization, while employing entropy-based uncertainty filtering to discard unreliable samples. This mechanism ensures robust distribution alignment and mitigates generalization degradation caused by uncertainties. Therefore, CSFA establishes a unified framework for stable adaptation to evolving semantics and distributions in open-world streaming scenarios. Extensive experiments validate the superior performance and effectiveness of CSFA compared to state-of-the-art approaches.
Learning Robust Spectral Dynamics for Temporal Domain Generalization
May 19, 2025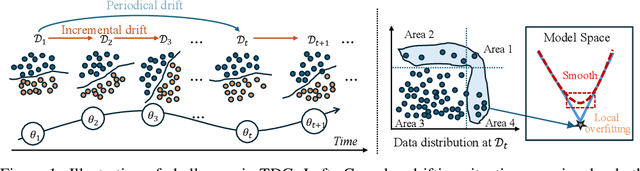
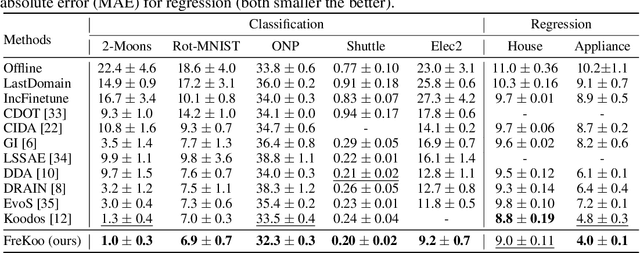
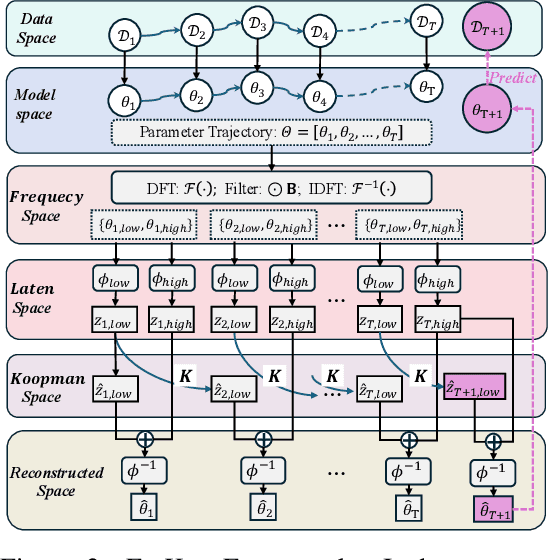

Modern machine learning models struggle to maintain performance in dynamic environments where temporal distribution shifts, \emph{i.e., concept drift}, are prevalent. Temporal Domain Generalization (TDG) seeks to enable model generalization across evolving domains, yet existing approaches typically assume smooth incremental changes, struggling with complex real-world drifts involving long-term structure (incremental evolution/periodicity) and local uncertainties. To overcome these limitations, we introduce FreKoo, which tackles these challenges via a novel frequency-domain analysis of parameter trajectories. It leverages the Fourier transform to disentangle parameter evolution into distinct spectral bands. Specifically, low-frequency component with dominant dynamics are learned and extrapolated using the Koopman operator, robustly capturing diverse drift patterns including both incremental and periodicity. Simultaneously, potentially disruptive high-frequency variations are smoothed via targeted temporal regularization, preventing overfitting to transient noise and domain uncertainties. In addition, this dual spectral strategy is rigorously grounded through theoretical analysis, providing stability guarantees for the Koopman prediction, a principled Bayesian justification for the high-frequency regularization, and culminating in a multiscale generalization bound connecting spectral dynamics to improved generalization. Extensive experiments demonstrate FreKoo's significant superiority over SOTA TDG approaches, particularly excelling in real-world streaming scenarios with complex drifts and uncertainties.
Membership Inference Attack Should Move On to Distributional Statistics for Distilled Generative Models
Feb 05, 2025



Membership inference attacks (MIAs) determine whether certain data instances were used to train a model by exploiting the differences in how the model responds to seen versus unseen instances. This capability makes MIAs important in assessing privacy leakage within modern generative AI systems. However, this paper reveals an oversight in existing MIAs against \emph{distilled generative models}: attackers can no longer detect a teacher model's training instances individually when targeting the distilled student model, as the student learns from the teacher-generated data rather than its original member data, preventing direct instance-level memorization. Nevertheless, we find that student-generated samples exhibit a significantly stronger distributional alignment with teacher's member data than non-member data. This leads us to posit that MIAs \emph{on distilled generative models should shift from instance-level to distribution-level statistics}. We thereby introduce a \emph{set-based} MIA framework that measures \emph{relative} distributional discrepancies between student-generated data\emph{sets} and potential member/non-member data\emph{sets}, Empirically, distributional statistics reliably distinguish a teacher's member data from non-member data through the distilled model. Finally, we discuss scenarios in which our setup faces limitations.
Early Concept Drift Detection via Prediction Uncertainty
Dec 15, 2024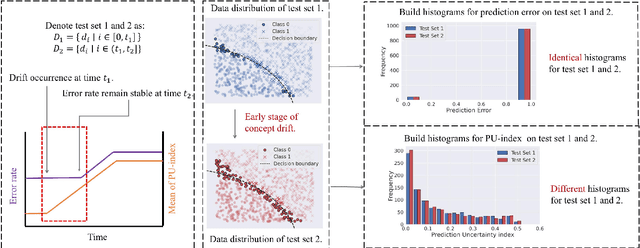
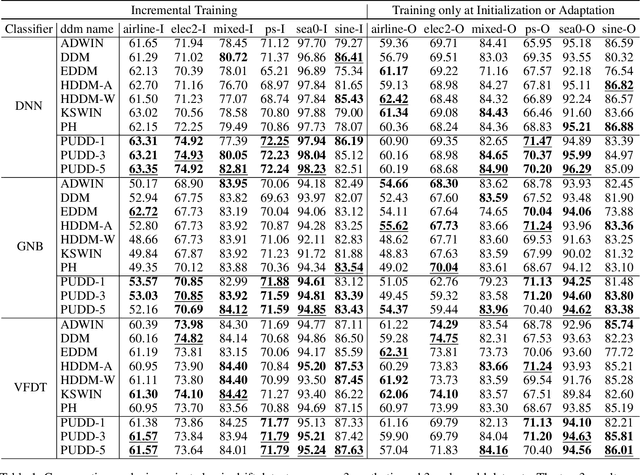
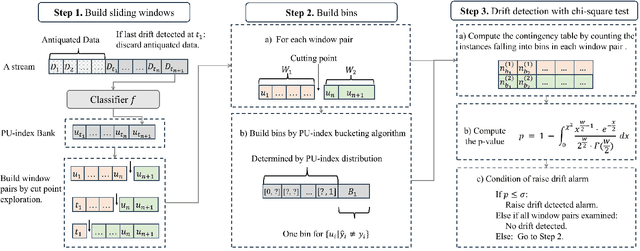
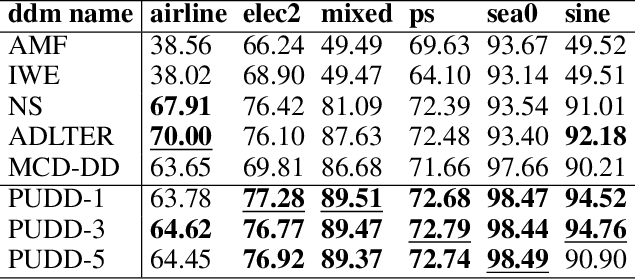
Concept drift, characterized by unpredictable changes in data distribution over time, poses significant challenges to machine learning models in streaming data scenarios. Although error rate-based concept drift detectors are widely used, they often fail to identify drift in the early stages when the data distribution changes but error rates remain constant. This paper introduces the Prediction Uncertainty Index (PU-index), derived from the prediction uncertainty of the classifier, as a superior alternative to the error rate for drift detection. Our theoretical analysis demonstrates that: (1) The PU-index can detect drift even when error rates remain stable. (2) Any change in the error rate will lead to a corresponding change in the PU-index. These properties make the PU-index a more sensitive and robust indicator for drift detection compared to existing methods. We also propose a PU-index-based Drift Detector (PUDD) that employs a novel Adaptive PU-index Bucketing algorithm for detecting drift. Empirical evaluations on both synthetic and real-world datasets demonstrate PUDD's efficacy in detecting drift in structured and image data.
Sharpness-Aware Cross-Domain Recommendation to Cold-Start Users
Aug 06, 2024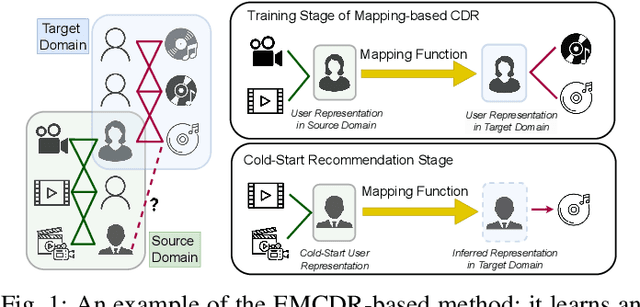
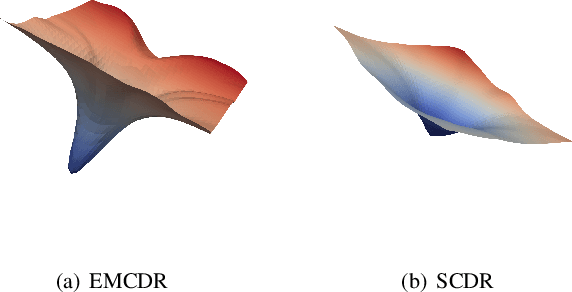
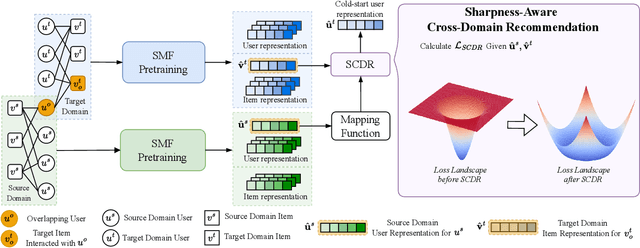
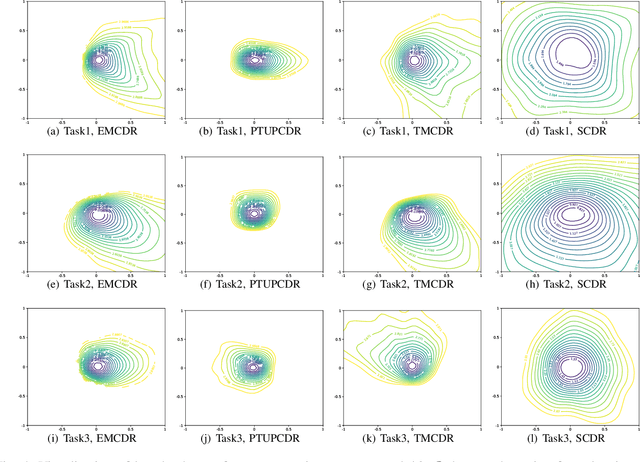
Cross-Domain Recommendation (CDR) is a promising paradigm inspired by transfer learning to solve the cold-start problem in recommender systems. Existing state-of-the-art CDR methods train an explicit mapping function to transfer the cold-start users from a data-rich source domain to a target domain. However, a limitation of these methods is that the mapping function is trained on overlapping users across domains, while only a small number of overlapping users are available for training. By visualizing the loss landscape of the existing CDR model, we find that training on a small number of overlapping users causes the model to converge to sharp minima, leading to poor generalization. Based on this observation, we leverage loss-geometry-based machine learning approach and propose a novel CDR method called Sharpness-Aware CDR (SCDR). Our proposed method simultaneously optimizes recommendation loss and loss sharpness, leading to better generalization with theoretical guarantees. Empirical studies on real-world datasets demonstrate that SCDR significantly outperforms the other CDR models for cold-start recommendation tasks, while concurrently enhancing the model's robustness to adversarial attacks.
A Behavior-Aware Approach for Deep Reinforcement Learning in Non-stationary Environments without Known Change Points
May 23, 2024Deep reinforcement learning is used in various domains, but usually under the assumption that the environment has stationary conditions like transitions and state distributions. When this assumption is not met, performance suffers. For this reason, tracking continuous environmental changes and adapting to unpredictable conditions is challenging yet crucial because it ensures that systems remain reliable and flexible in practical scenarios. Our research introduces Behavior-Aware Detection and Adaptation (BADA), an innovative framework that merges environmental change detection with behavior adaptation. The key inspiration behind our method is that policies exhibit different global behaviors in changing environments. Specifically, environmental changes are identified by analyzing variations between behaviors using Wasserstein distances without manually set thresholds. The model adapts to the new environment through behavior regularization based on the extent of changes. The results of a series of experiments demonstrate better performance relative to several current algorithms. This research also indicates significant potential for tackling this long-standing challenge.
A Neighbor-Searching Discrepancy-based Drift Detection Scheme for Learning Evolving Data
May 23, 2024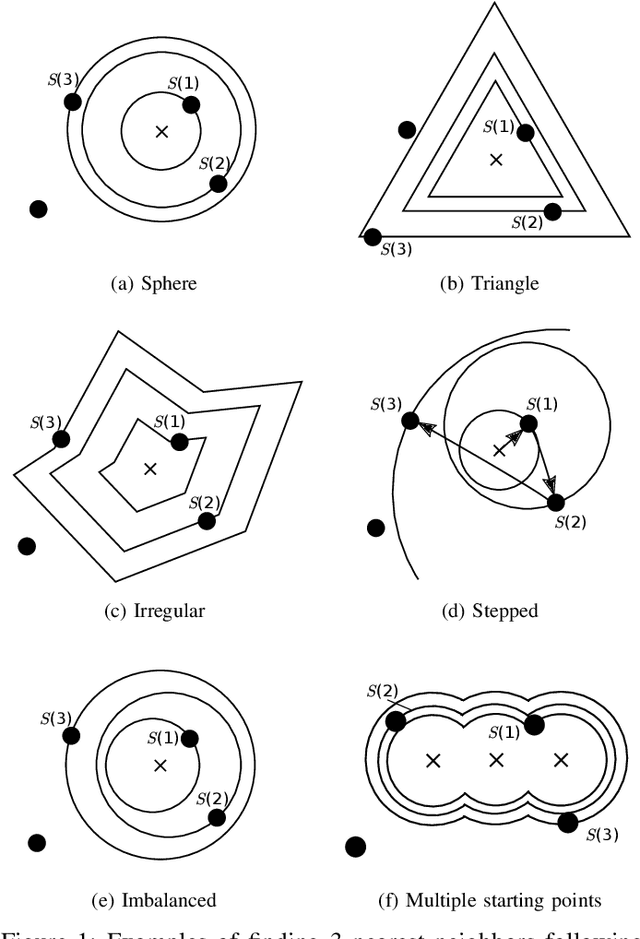
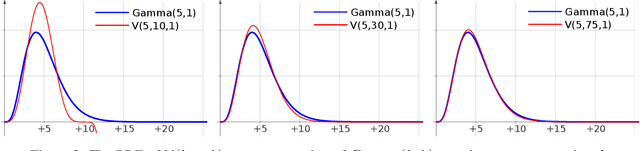
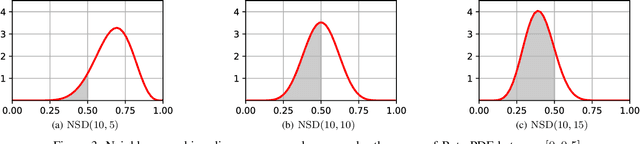
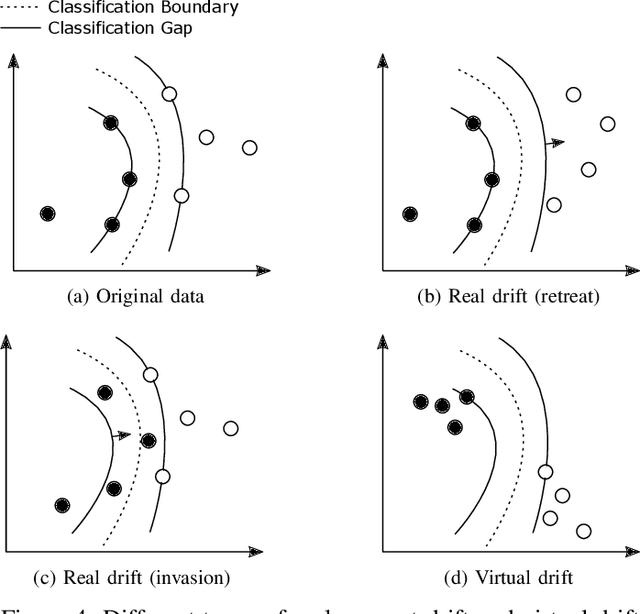
Uncertain changes in data streams present challenges for machine learning models to dynamically adapt and uphold performance in real-time. Particularly, classification boundary change, also known as real concept drift, is the major cause of classification performance deterioration. However, accurately detecting real concept drift remains challenging because the theoretical foundations of existing drift detection methods - two-sample distribution tests and monitoring classification error rate, both suffer from inherent limitations such as the inability to distinguish virtual drift (changes not affecting the classification boundary, will introduce unnecessary model maintenance), limited statistical power, or high computational cost. Furthermore, no existing detection method can provide information on the trend of the drift, which could be invaluable for model maintenance. This work presents a novel real concept drift detection method based on Neighbor-Searching Discrepancy, a new statistic that measures the classification boundary difference between two samples. The proposed method is able to detect real concept drift with high accuracy while ignoring virtual drift. It can also indicate the direction of the classification boundary change by identifying the invasion or retreat of a certain class, which is also an indicator of separability change between classes. A comprehensive evaluation of 11 experiments is conducted, including empirical verification of the proposed theory using artificial datasets, and experimental comparisons with commonly used drift handling methods on real-world datasets. The results show that the proposed theory is robust against a range of distributions and dimensions, and the drift detection method outperforms state-of-the-art alternative methods.