 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Data Laundering in LLM Training
Apr 02, 2026Data rights owners can detect unauthorized data use in large language model (LLM) training by querying with proprietary samples. Often, superior performance (e.g., higher confidence or lower loss) on a sample relative to the untrained data implies it was part of the training corpus, as LLMs tend to perform better on data they have seen during training. However, this detection becomes fragile under data laundering, a practice of transforming the stylistic form of proprietary data, while preserving critical information to obfuscate data provenance. When an LLM is trained exclusively on such laundered variants, it no longer performs better on originals, erasing the signals that standard detections rely on. We counter this by inferring the unknown laundering transformation from black-box access to the target LLM and, via an auxiliary LLM, synthesizing queries that mimic the laundered data, even if rights owners have only the originals. As the search space of finding true laundering transformations is infinite, we abstract such a process into a high-level transformation goal (e.g., "lyrical rewriting") and concrete details (e.g., "with vivid imagery"), and introduce synthesis data reversion (SDR) that instantiates this abstraction. SDR first identifies the most probable goal for synthesis to narrow the search; it then iteratively refines details so that synthesized queries gradually elicit stronger detection signals from the target LLM. Evaluated on the MIMIR benchmark against diverse laundering practices and target LLM families (Pythia, Llama2, and Falcon), SDR consistently strengthens data misuse detection, providing a practical countermeasure to data laundering.
Unlearning Evaluation through Subset Statistical Independence
Feb 28, 2026Evaluating machine unlearning remains challenging, as existing methods typically require retraining reference models or performing membership inference attacks, both of which rely on prior access to training configuration or supervision labels, making them impractical in realistic scenarios. Motivated by the fact that most unlearning algorithms remove a small, random subset of the training data, we propose a subset-level evaluation framework based on statistical independence. Specifically, we design a tailored use of the Hilbert-Schmidt Independence Criterion to assess whether the model outputs on a given subset exhibit statistical dependence, without requiring model retraining or auxiliary classifiers. Our method provides a simple, standalone evaluation procedure that aligns with unlearning workflows. Extensive experiments demonstrate that our approach reliably distinguishes in-training from out-of-training subsets and clearly differentiates unlearning effectiveness, even when existing evaluations fall short.
Membership Inference Attack Should Move On to Distributional Statistics for Distilled Generative Models
Feb 05, 2025



Membership inference attacks (MIAs) determine whether certain data instances were used to train a model by exploiting the differences in how the model responds to seen versus unseen instances. This capability makes MIAs important in assessing privacy leakage within modern generative AI systems. However, this paper reveals an oversight in existing MIAs against \emph{distilled generative models}: attackers can no longer detect a teacher model's training instances individually when targeting the distilled student model, as the student learns from the teacher-generated data rather than its original member data, preventing direct instance-level memorization. Nevertheless, we find that student-generated samples exhibit a significantly stronger distributional alignment with teacher's member data than non-member data. This leads us to posit that MIAs \emph{on distilled generative models should shift from instance-level to distribution-level statistics}. We thereby introduce a \emph{set-based} MIA framework that measures \emph{relative} distributional discrepancies between student-generated data\emph{sets} and potential member/non-member data\emph{sets}, Empirically, distributional statistics reliably distinguish a teacher's member data from non-member data through the distilled model. Finally, we discuss scenarios in which our setup faces limitations.
NFANet: A Novel Method for Weakly Supervised Water Extraction from High-Resolution Remote Sensing Imagery
Jan 10, 2022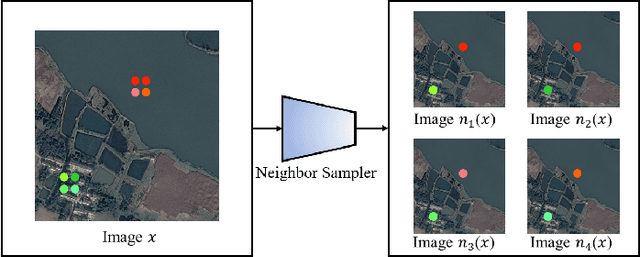
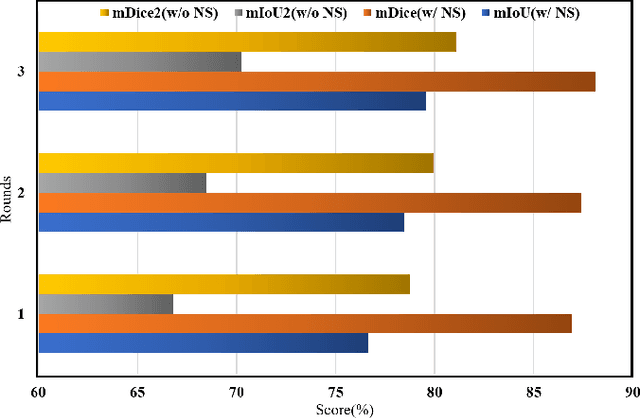

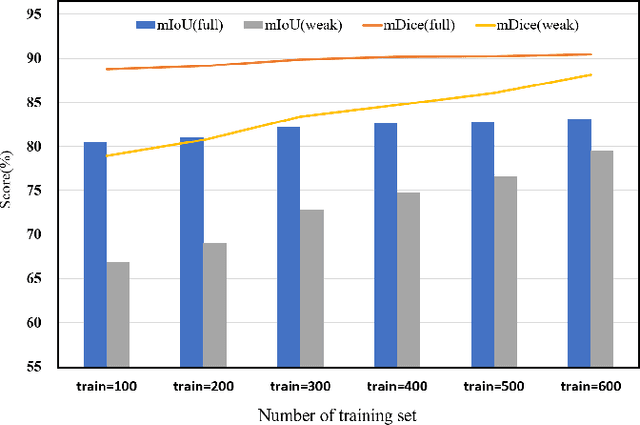
The use of deep learning for water extraction requires precise pixel-level labels. However, it is very difficult to label high-resolution remote sensing images at the pixel level. Therefore, we study how to utilize point labels to extract water bodies and propose a novel method called the neighbor feature aggregation network (NFANet). Compared with pixellevel labels, point labels are much easier to obtain, but they will lose much information. In this paper, we take advantage of the similarity between the adjacent pixels of a local water-body, and propose a neighbor sampler to resample remote sensing images. Then, the sampled images are sent to the network for feature aggregation. In addition, we use an improved recursive training algorithm to further improve the extraction accuracy, making the water boundary more natural. Furthermore, our method utilizes neighboring features instead of global or local features to learn more representative features. The experimental results show that the proposed NFANet method not only outperforms other studied weakly supervised approaches, but also obtains similar results as the state-of-the-art ones.