 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Restoration-Perception Learning: Maritime Infrared-Visible Image Fusion and Segmentation
Mar 30, 2026Marine scene understanding and segmentation plays a vital role in maritime monitoring and navigation safety. However, prevalent factors like fog and strong reflections in maritime environments cause severe image degradation, significantly compromising the stability of semantic perception. Existing restoration and enhancement methods typically target specific degradations or focus solely on visual quality, lacking end-to-end collaborative mechanisms that simultaneously improve structural recovery and semantic effectiveness. Moreover, publicly available infrared-visible datasets are predominantly collected from urban scenes, failing to capture the authentic characteristics of coupled degradations in marine environments. To address these challenges, the Infrared-Visible Maritime Ship Dataset (IVMSD) is proposed to cover various maritime scenarios under diverse weather and illumination conditions. Building upon this dataset, a Multi-task Complementary Learning Framework (MCLF) is proposed to collaboratively perform image restoration, multimodal fusion, and semantic segmentation within a unified architecture. The framework includes a Frequency-Spatial Enhancement Complementary (FSEC) module for degradation suppression and structural enhancement, a Semantic-Visual Consistency Attention (SVCA) module for semantic-consistent guidance, and a cross-modality guided attention mechanism for selective fusion. Experimental results on IVMSD demonstrate that the proposed method achieves state-of-the-art segmentation performance, significantly enhancing robustness and perceptual quality under complex maritime conditions.
PalmBridge: A Plug-and-Play Feature Alignment Framework for Open-Set Palmprint Verification
Jan 28, 2026Palmprint recognition is widely used in biometric systems, yet real-world performance often degrades due to feature distribution shifts caused by heterogeneous deployment conditions. Most deep palmprint models assume a closed and stationary distribution, leading to overfitting to dataset-specific textures rather than learning domain-invariant representations. Although data augmentation is commonly used to mitigate this issue, it assumes augmented samples can approximate the target deployment distribution, an assumption that often fails under significant domain mismatch. To address this limitation, we propose PalmBridge, a plug-and-play feature-space alignment framework for open-set palmprint verification based on vector quantization. Rather than relying solely on data-level augmentation, PalmBridge learns a compact set of representative vectors directly from training features. During enrollment and verification, each feature vector is mapped to its nearest representative vector under a minimum-distance criterion, and the mapped vector is then blended with the original vector. This design suppresses nuisance variation induced by domain shifts while retaining discriminative identity cues. The representative vectors are jointly optimized with the backbone network using task supervision, a feature-consistency objective, and an orthogonality regularization term to form a stable and well-structured shared embedding space. Furthermore, we analyze feature-to-representative mappings via assignment consistency and collision rate to assess model's sensitivity to blending weights. Experiments on multiple palmprint datasets and backbone architectures show that PalmBridge consistently reduces EER in intra-dataset open-set evaluation and improves cross-dataset generalization with negligible to modest runtime overhead.
A Cosine Network for Image Super-Resolution
Jan 23, 2026Deep convolutional neural networks can use hierarchical information to progressively extract structural information to recover high-quality images. However, preserving the effectiveness of the obtained structural information is important in image super-resolution. In this paper, we propose a cosine network for image super-resolution (CSRNet) by improving a network architecture and optimizing the training strategy. To extract complementary homologous structural information, odd and even heterogeneous blocks are designed to enlarge the architectural differences and improve the performance of image super-resolution. Combining linear and non-linear structural information can overcome the drawback of homologous information and enhance the robustness of the obtained structural information in image super-resolution. Taking into account the local minimum of gradient descent, a cosine annealing mechanism is used to optimize the training procedure by performing warm restarts and adjusting the learning rate. Experimental results illustrate that the proposed CSRNet is competitive with state-of-the-art methods in image super-resolution.
Palmprint De-Identification Using Diffusion Model for High-Quality and Diverse Synthesis
Apr 11, 2025



Palmprint recognition techniques have advanced significantly in recent years, enabling reliable recognition even when palmprints are captured in uncontrolled or challenging environments. However, this strength also introduces new risks, as publicly available palmprint images can be misused by adversaries for malicious activities. Despite this growing concern, research on methods to obscure or anonymize palmprints remains largely unexplored. Thus, it is essential to develop a palmprint de-identification technique capable of removing identity-revealing features while retaining the image's utility and preserving non-sensitive information. In this paper, we propose a training-free framework that utilizes pre-trained diffusion models to generate diverse, high-quality palmprint images that conceal identity features for de-identification purposes. To ensure greater stability and controllability in the synthesis process, we incorporate a semantic-guided embedding fusion alongside a prior interpolation mechanism. We further propose the de-identification ratio, a novel metric for intuitive de-identification assessment. Extensive experiments across multiple palmprint datasets and recognition methods demonstrate that our method effectively conceals identity-related traits with significant diversity across de-identified samples. The de-identified samples preserve high visual fidelity and maintain excellent usability, achieving a balance between de-identification and retaining non-identity information.
FedPalm: A General Federated Learning Framework for Closed- and Open-Set Palmprint Verification
Mar 05, 2025



Current deep learning (DL)-based palmprint verification models rely on centralized training with large datasets, which raises significant privacy concerns due to biometric data's sensitive and immutable nature. Federated learning~(FL), a privacy-preserving distributed learning paradigm, offers a compelling alternative by enabling collaborative model training without the need for data sharing. However, FL-based palmprint verification faces critical challenges, including data heterogeneity from diverse identities and the absence of standardized evaluation benchmarks. This paper addresses these gaps by establishing a comprehensive benchmark for FL-based palmprint verification, which explicitly defines and evaluates two practical scenarios: closed-set and open-set verification. We propose FedPalm, a unified FL framework that balances local adaptability with global generalization. Each client trains a personalized textural expert tailored to local data and collaboratively contributes to a shared global textural expert for extracting generalized features. To further enhance verification performance, we introduce a Textural Expert Interaction Module that dynamically routes textural features among experts to generate refined side textural features. Learnable parameters are employed to model relationships between original and side features, fostering cross-texture-expert interaction and improving feature discrimination. Extensive experiments validate the effectiveness of FedPalm, demonstrating robust performance across both scenarios and providing a promising foundation for advancing FL-based palmprint verification research.
PhenoProfiler: Advancing Phenotypic Learning for Image-based Drug Discovery
Feb 26, 2025In the field of image-based drug discovery, capturing the phenotypic response of cells to various drug treatments and perturbations is a crucial step. However, existing methods require computationally extensive and complex multi-step procedures, which can introduce inefficiencies, limit generalizability, and increase potential errors. To address these challenges, we present PhenoProfiler, an innovative model designed to efficiently and effectively extract morphological representations, enabling the elucidation of phenotypic changes induced by treatments. PhenoProfiler is designed as an end-to-end tool that processes whole-slide multi-channel images directly into low-dimensional quantitative representations, eliminating the extensive computational steps required by existing methods. It also includes a multi-objective learning module to enhance robustness, accuracy, and generalization in morphological representation learning. PhenoProfiler is rigorously evaluated on large-scale publicly available datasets, including over 230,000 whole-slide multi-channel images in end-to-end scenarios and more than 8.42 million single-cell images in non-end-to-end settings. Across these benchmarks, PhenoProfiler consistently outperforms state-of-the-art methods by up to 20%, demonstrating substantial improvements in both accuracy and robustness. Furthermore, PhenoProfiler uses a tailored phenotype correction strategy to emphasize relative phenotypic changes under treatments, facilitating the detection of biologically meaningful signals. UMAP visualizations of treatment profiles demonstrate PhenoProfiler ability to effectively cluster treatments with similar biological annotations, thereby enhancing interpretability. These findings establish PhenoProfiler as a scalable, generalizable, and robust tool for phenotypic learning.
Deep Learning in Palmprint Recognition-A Comprehensive Survey
Jan 02, 2025



Palmprint recognition has emerged as a prominent biometric technology, widely applied in diverse scenarios. Traditional handcrafted methods for palmprint recognition often fall short in representation capability, as they heavily depend on researchers' prior knowledge. Deep learning (DL) has been introduced to address this limitation, leveraging its remarkable successes across various domains. While existing surveys focus narrowly on specific tasks within palmprint recognition-often grounded in traditional methodologies-there remains a significant gap in comprehensive research exploring DL-based approaches across all facets of palmprint recognition. This paper bridges that gap by thoroughly reviewing recent advancements in DL-powered palmprint recognition. The paper systematically examines progress across key tasks, including region-of-interest segmentation, feature extraction, and security/privacy-oriented challenges. Beyond highlighting these advancements, the paper identifies current challenges and uncovers promising opportunities for future research. By consolidating state-of-the-art progress, this review serves as a valuable resource for researchers, enabling them to stay abreast of cutting-edge technologies and drive innovation in palmprint recognition.
From Data to Insights: A Covariate Analysis of the IARPA BRIAR Dataset for Multimodal Biometric Recognition Algorithms at Altitude and Range
Sep 03, 2024


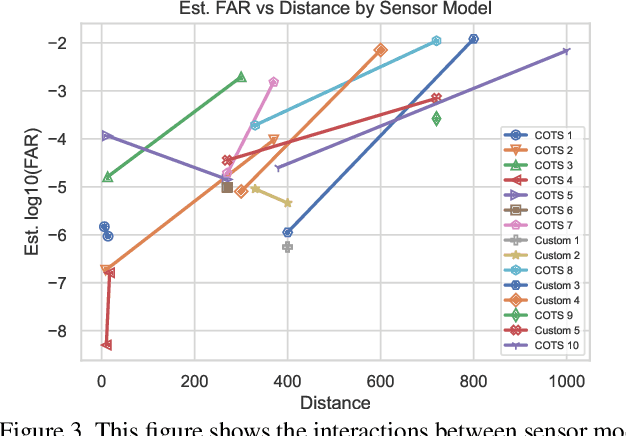
This paper examines covariate effects on fused whole body biometrics performance in the IARPA BRIAR dataset, specifically focusing on UAV platforms, elevated positions, and distances up to 1000 meters. The dataset includes outdoor videos compared with indoor images and controlled gait recordings. Normalized raw fusion scores relate directly to predicted false accept rates (FAR), offering an intuitive means for interpreting model results. A linear model is developed to predict biometric algorithm scores, analyzing their performance to identify the most influential covariates on accuracy at altitude and range. Weather factors like temperature, wind speed, solar loading, and turbulence are also investigated in this analysis. The study found that resolution and camera distance best predicted accuracy and findings can guide future research and development efforts in long-range/elevated/UAV biometrics and support the creation of more reliable and robust systems for national security and other critical domains.
Long-Range Biometric Identification in Real World Scenarios: A Comprehensive Evaluation Framework Based on Missions
Sep 03, 2024
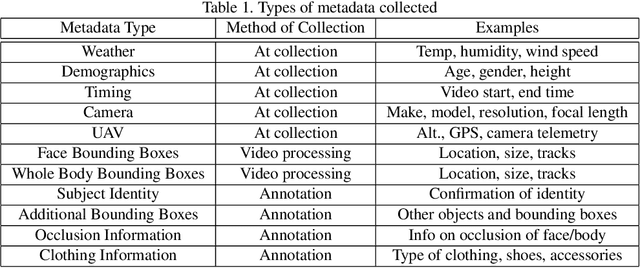
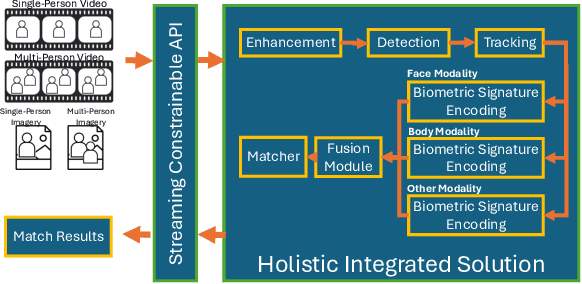
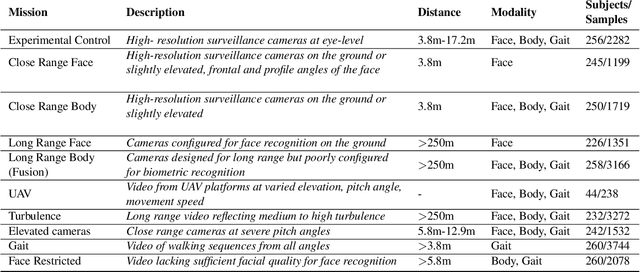
The considerable body of data available for evaluating biometric recognition systems in Research and Development (R\&D) environments has contributed to the increasingly common problem of target performance mismatch. Biometric algorithms are frequently tested against data that may not reflect the real world applications they target. From a Testing and Evaluation (T\&E) standpoint, this domain mismatch causes difficulty assessing when improvements in State-of-the-Art (SOTA) research actually translate to improved applied outcomes. This problem can be addressed with thoughtful preparation of data and experimental methods to reflect specific use-cases and scenarios. To that end, this paper evaluates research solutions for identifying individuals at ranges and altitudes, which could support various application areas such as counterterrorism, protection of critical infrastructure facilities, military force protection, and border security. We address challenges including image quality issues and reliance on face recognition as the sole biometric modality. By fusing face and body features, we propose developing robust biometric systems for effective long-range identification from both the ground and steep pitch angles. Preliminary results show promising progress in whole-body recognition. This paper presents these early findings and discusses potential future directions for advancing long-range biometric identification systems based on mission-driven metrics.
CDIMC-net: Cognitive Deep Incomplete Multi-view Clustering Network
Mar 28, 2024



In recent years, incomplete multi-view clustering, which studies the challenging multi-view clustering problem on missing views, has received growing research interests. Although a series of methods have been proposed to address this issue, the following problems still exist: 1) Almost all of the existing methods are based on shallow models, which is difficult to obtain discriminative common representations. 2) These methods are generally sensitive to noise or outliers since the negative samples are treated equally as the important samples. In this paper, we propose a novel incomplete multi-view clustering network, called Cognitive Deep Incomplete Multi-view Clustering Network (CDIMC-net), to address these issues. Specifically, it captures the high-level features and local structure of each view by incorporating the view-specific deep encoders and graph embedding strategy into a framework. Moreover, based on the human cognition, i.e., learning from easy to hard, it introduces a self-paced strategy to select the most confident samples for model training, which can reduce the negative influence of outliers. Experimental results on several incomplete datasets show that CDIMC-net outperforms the state-of-the-art incomplete multi-view clustering methods.