 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language-Driven Global Mapping of Martian Landforms
Jan 22, 2026Planetary surfaces are typically analyzed using high-level semantic concepts in natural language, yet vast orbital image archives remain organized at the pixel level. This mismatch limits scalable, open-ended exploration of planetary surfaces. Here we present MarScope, a planetary-scale vision-language framework enabling natural language-driven, label-free mapping of Martian landforms. MarScope aligns planetary images and text in a shared semantic space, trained on over 200,000 curated image-text pairs. This framework transforms global geomorphic mapping on Mars by replacing pre-defined classifications with flexible semantic retrieval, enabling arbitrary user queries across the entire planet in 5 seconds with F1 scores up to 0.978. Applications further show that it extends beyond morphological classification to facilitate process-oriented analysis and similarity-based geomorphological mapping at a planetary scale. MarScope establishes a new paradigm where natural language serves as a direct interface for scientific discovery over massive geospatial datasets.
Your Pre-trained LLM is Secretly an Unsupervised Confidence Calibrator
May 22, 2025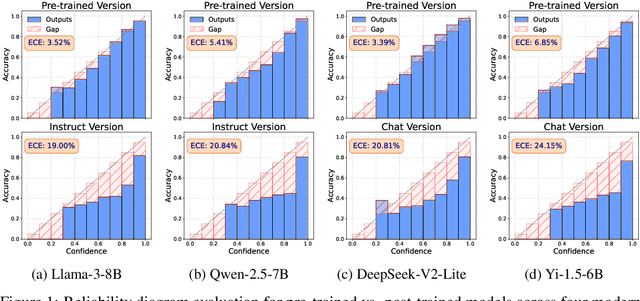
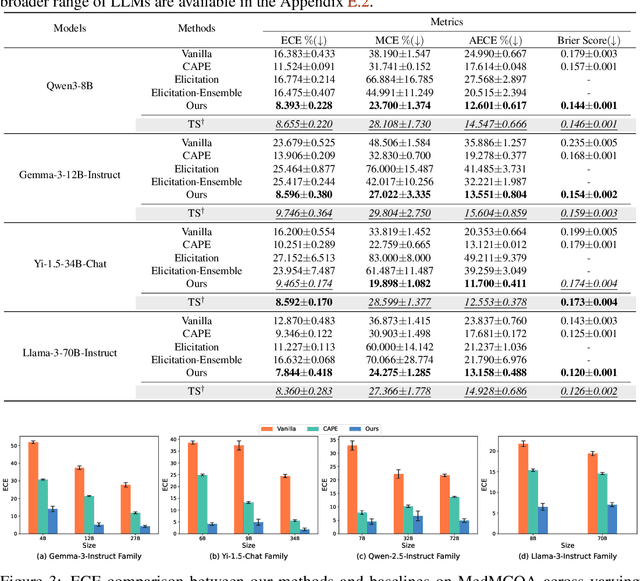
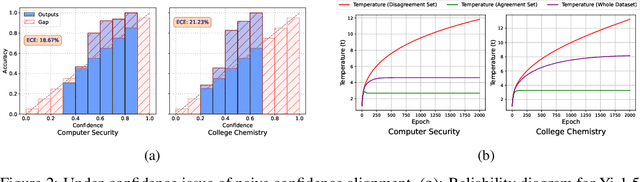

Post-training of large language models is essential for adapting pre-trained language models (PLMs) to align with human preferences and downstream tasks. While PLMs typically exhibit well-calibrated confidence, post-trained language models (PoLMs) often suffer from over-confidence, assigning high confidence to both correct and incorrect outputs, which can undermine reliability in critical applications. A major obstacle in calibrating PoLMs is the scarcity of labeled data for individual downstream tasks. To address this, we propose Disagreement-Aware Confidence Alignment (DACA), a novel unsupervised method to optimize the parameters (e.g., temperature $\tau$) in post-hoc confidence calibration. Our method is motivated by the under-confidence issue caused by prediction disagreement between the PLM and PoLM while aligning their confidence via temperature scaling. Theoretically, the PLM's confidence underestimates PoLM's prediction accuracy on disagreement examples, causing a larger $\tau$ and producing under-confident predictions. DACA mitigates this by selectively using only agreement examples for calibration, effectively decoupling the influence of disagreement. In this manner, our method avoids an overly large $\tau$ in temperature scaling caused by disagreement examples, improving calibration performance. Extensive experiments demonstrate the effectiveness of our method, improving the average ECE of open-sourced and API-based LLMs (e.g. GPT-4o) by up to 15.08$\%$ on common benchmarks.
Generalizable Sensor-Based Activity Recognition via Categorical Concept Invariant Learning
Dec 18, 2024



Human Activity Recognition (HAR) aims to recognize activities by training models on massive sensor data. In real-world deployment, a crucial aspect of HAR that has been largely overlooked is that the test sets may have different distributions from training sets due to inter-subject variability including age, gender, behavioral habits, etc., which leads to poor generalization performance. One promising solution is to learn domain-invariant representations to enable a model to generalize on an unseen distribution. However, most existing methods only consider the feature-invariance of the penultimate layer for domain-invariant learning, which leads to suboptimal results. In this paper, we propose a Categorical Concept Invariant Learning (CCIL) framework for generalizable activity recognition, which introduces a concept matrix to regularize the model in the training stage by simultaneously concentrating on feature-invariance and logit-invariance. Our key idea is that the concept matrix for samples belonging to the same activity category should be similar. Extensive experiments on four public HAR benchmarks demonstrate that our CCIL substantially outperforms the state-of-the-art approaches under cross-person, cross-dataset, cross-position, and one-person-to-another settings.
Manta: Enhancing Mamba for Few-Shot Action Recognition of Long Sub-Sequence
Dec 10, 2024



In few-shot action recognition~(FSAR), long sub-sequences of video naturally express entire actions more effectively. However, the computational complexity of mainstream Transformer-based methods limits their application. Recent Mamba demonstrates efficiency in modeling long sequences, but directly applying Mamba to FSAR overlooks the importance of local feature modeling and alignment. Moreover, long sub-sequences within the same class accumulate intra-class variance, which adversely impacts FSAR performance. To solve these challenges, we propose a \underline{\textbf{M}}atryoshka M\underline{\textbf{A}}mba and Co\underline{\textbf{N}}tras\underline{\textbf{T}}ive Le\underline{\textbf{A}}rning framework~(\textbf{Manta}). Firstly, the Matryoshka Mamba introduces multiple Inner Modules to enhance local feature representation, rather than directly modeling global features. An Outer Module captures dependencies of timeline between these local features for implicit temporal alignment. Secondly, a hybrid contrastive learning paradigm, combining both supervised and unsupervised methods, is designed to mitigate the negative effects of intra-class variance accumulation. The Matryoshka Mamba and the hybrid contrastive learning paradigm operate in parallel branches within Manta, enhancing Mamba for FSAR of long sub-sequence. Manta achieves new state-of-the-art performance on prominent benchmarks, including SSv2, Kinetics, UCF101, and HMDB51. Extensive empirical studies prove that Manta significantly improves FSAR of long sub-sequence from multiple perspectives. The code is released at https://github.com/wenbohuang1002/Manta.
Understanding and Mitigating Miscalibration in Prompt Tuning for Vision-Language Models
Oct 03, 2024



Confidence calibration is critical for the safe deployment of machine learning models in the real world. However, such issue in vision-language models like CLIP, particularly after fine-tuning, has not been fully addressed. In this work, we demonstrate that existing prompt tuning methods usually lead to a trade-off of calibration between base and new classes: the cross-entropy loss in CoOp causes overconfidence in new classes by increasing textual label divergence, whereas the regularization of KgCoOp maintains the confidence level but results in underconfidence in base classes due to the improved accuracy. Inspired by the observations, we introduce Dynamic Outlier Regularization (DOR) to ensure the confidence calibration on both base and new classes after fine-tuning. In particular, we propose to minimize the feature deviation of novel textual labels (instead of base classes) sampled from a large vocabulary. In effect, DOR prevents the increase in textual divergence for new labels while easing restrictions on base classes. Extensive experiments demonstrate that DOR can enhance the calibration performance of current fine-tuning methods on base and new classes.
Open-Vocabulary Calibration for Vision-Language Models
Feb 15, 2024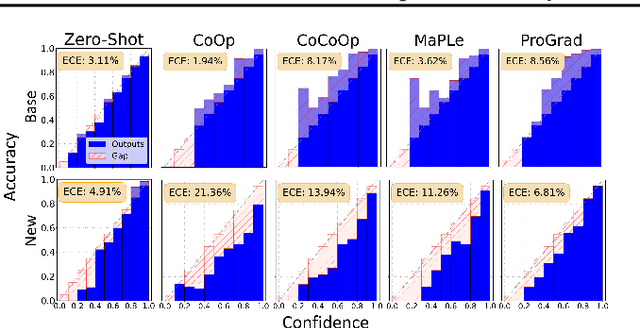
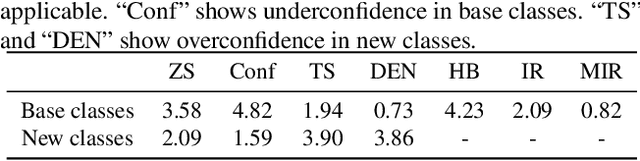
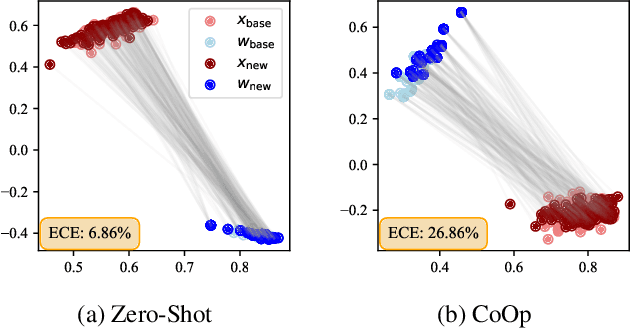
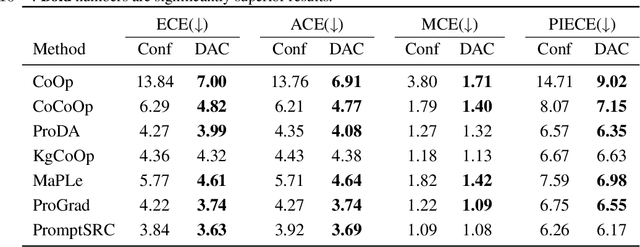
Vision-language models (VLMs) have emerged as formidable tools, showing their strong capability in handling various open-vocabulary tasks in image recognition, text-driven visual content generation, and visual chatbots, to name a few. In recent years, considerable efforts and resources have been devoted to adaptation methods for improving downstream performance of VLMs, particularly on parameter-efficient fine-tuning methods like prompt learning. However, a crucial aspect that has been largely overlooked is the confidence calibration problem in fine-tuned VLMs, which could greatly reduce reliability when deploying such models in the real world. This paper bridges the gap by systematically investigating the confidence calibration problem in the context of prompt learning and reveals that existing calibration methods are insufficient to address the problem, especially in the open-vocabulary setting. To solve the problem, we present a simple and effective approach called Distance-Aware Calibration (DAC), which is based on scaling the temperature using as guidance the distance between predicted text labels and base classes. The experiments with 7 distinct prompt learning methods applied across 11 diverse downstream datasets demonstrate the effectiveness of DAC, which achieves high efficacy without sacrificing the inference speed.
Optimization-Free Test-Time Adaptation for Cross-Person Activity Recognition
Oct 28, 2023Human Activity Recognition (HAR) models often suffer from performance degradation in real-world applications due to distribution shifts in activity patterns across individuals. Test-Time Adaptation (TTA) is an emerging learning paradigm that aims to utilize the test stream to adjust predictions in real-time inference, which has not been explored in HAR before. However, the high computational cost of optimization-based TTA algorithms makes it intractable to run on resource-constrained edge devices. In this paper, we propose an Optimization-Free Test-Time Adaptation (OFTTA) framework for sensor-based HAR. OFTTA adjusts the feature extractor and linear classifier simultaneously in an optimization-free manner. For the feature extractor, we propose Exponential DecayTest-time Normalization (EDTN) to replace the conventional batch normalization (CBN) layers. EDTN combines CBN and Test-time batch Normalization (TBN) to extract reliable features against domain shifts with TBN's influence decreasing exponentially in deeper layers. For the classifier, we adjust the prediction by computing the distance between the feature and the prototype, which is calculated by a maintained support set. In addition, the update of the support set is based on the pseudo label, which can benefit from reliable features extracted by EDTN. Extensive experiments on three public cross-person HAR datasets and two different TTA settings demonstrate that OFTTA outperforms the state-of-the-art TTA approaches in both classification performance and computational efficiency. Finally, we verify the superiority of our proposed OFTTA on edge devices, indicating possible deployment in real applications. Our code is available at \href{https://github.com/Claydon-Wang/OFTTA}{this https URL}.