 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL2R: Low-Rank and Lipschitz-Controlled Routing for Mixture-of-Experts
Jan 29, 2026Mixture-of-Experts (MoE) models scale neural networks by conditionally activating a small subset of experts, where the router plays a central role in determining expert specialization and overall model performance. However, many modern MoE systems still adopt linear routers in raw high-dimensional representation spaces, where representation mismatch, angular concentration, and scale-sensitive scoring can jointly undermine routing discriminability and stable expert specialization. In this work, we propose Low-rank \& Lipschitz-controlled Routing (L2R), a unified routing framework that reshapes both the routing space and scoring geometry. L2R performs expert assignment in a shared low-rank latent routing space and introduces Saturated Inner-Product Scoring (SIPS) to explicitly control the Lipschitz behavior of routing functions, yielding smoother and more stable routing geometry. In addition, L2R incorporates a parameter-efficient multi-anchor routing mechanism to enhance expert expressiveness. Extensive experiments on a large-scale language MoE model and a vision MoE setting on ImageNet demonstrate that L2R consistently improves routing stability, expert specialization, and overall model performance.
Difficulty-guided Sampling: Bridging the Target Gap between Dataset Distillation and Downstream Tasks
Jan 15, 2026In this paper, we propose difficulty-guided sampling (DGS) to bridge the target gap between the distillation objective and the downstream task, therefore improving the performance of dataset distillation. Deep neural networks achieve remarkable performance but have time and storage-consuming training processes. Dataset distillation is proposed to generate compact, high-quality distilled datasets, enabling effective model training while maintaining downstream performance. Existing approaches typically focus on features extracted from the original dataset, overlooking task-specific information, which leads to a target gap between the distillation objective and the downstream task. We propose leveraging characteristics that benefit the downstream training into data distillation to bridge this gap. Focusing on the downstream task of image classification, we introduce the concept of difficulty and propose DGS as a plug-in post-stage sampling module. Following the specific target difficulty distribution, the final distilled dataset is sampled from image pools generated by existing methods. We also propose difficulty-aware guidance (DAG) to explore the effect of difficulty in the generation process. Extensive experiments across multiple settings demonstrate the effectiveness of the proposed methods. It also highlights the broader potential of difficulty for diverse downstream tasks.
Foreground-Aware Dataset Distillation via Dynamic Patch Selection
Jan 06, 2026In this paper, we propose a foreground-aware dataset distillation method that enhances patch selection in a content-adaptive manner. With the rising computational cost of training large-scale deep models, dataset distillation has emerged as a promising approach for constructing compact synthetic datasets that retain the knowledge of their large original counterparts. However, traditional optimization-based methods often suffer from high computational overhead, memory constraints, and the generation of unrealistic, noise-like images with limited architectural generalization. Recent non-optimization methods alleviate some of these issues by constructing distilled data from real image patches, but the used rigid patch selection strategies can still discard critical information about the main objects. To solve this problem, we first leverage Grounded SAM2 to identify foreground objects and compute per-image foreground occupancy, from which we derive a category-wise patch decision threshold. Guided by these thresholds, we design a dynamic patch selection strategy that, for each image, either selects the most informative patch from multiple candidates or directly resizes the full image when the foreground dominates. This dual-path mechanism preserves more key information about the main objects while reducing redundant background content. Extensive experiments on multiple benchmarks show that the proposed method consistently improves distillation performance over existing approaches, producing more informative and representative distilled datasets and enhancing robustness across different architectures and image compositions.
Otter: Mitigating Background Distractions of Wide-Angle Few-Shot Action Recognition with Enhanced RWKV
Nov 11, 2025Wide-angle videos in few-shot action recognition (FSAR) effectively express actions within specific scenarios. However, without a global understanding of both subjects and background, recognizing actions in such samples remains challenging because of the background distractions. Receptance Weighted Key Value (RWKV), which learns interaction between various dimensions, shows promise for global modeling. While directly applying RWKV to wide-angle FSAR may fail to highlight subjects due to excessive background information. Additionally, temporal relation degraded by frames with similar backgrounds is difficult to reconstruct, further impacting performance. Therefore, we design the CompOund SegmenTation and Temporal REconstructing RWKV (Otter). Specifically, the Compound Segmentation Module~(CSM) is devised to segment and emphasize key patches in each frame, effectively highlighting subjects against background information. The Temporal Reconstruction Module (TRM) is incorporated into the temporal-enhanced prototype construction to enable bidirectional scanning, allowing better reconstruct temporal relation. Furthermore, a regular prototype is combined with the temporal-enhanced prototype to simultaneously enhance subject emphasis and temporal modeling, improving wide-angle FSAR performance. Extensive experiments on benchmarks such as SSv2, Kinetics, UCF101, and HMDB51 demonstrate that Otter achieves state-of-the-art performance. Extra evaluation on the VideoBadminton dataset further validates the superiority of Otter in wide-angle FSAR.
Privacy-Aware Continual Self-Supervised Learning on Multi-Window Chest Computed Tomography for Domain-Shift Robustness
Oct 31, 2025We propose a novel continual self-supervised learning (CSSL) framework for simultaneously learning diverse features from multi-window-obtained chest computed tomography (CT) images and ensuring data privacy. Achieving a robust and highly generalizable model in medical image diagnosis is challenging, mainly because of issues, such as the scarcity of large-scale, accurately annotated datasets and domain shifts inherent to dynamic healthcare environments. Specifically, in chest CT, these domain shifts often arise from differences in window settings, which are optimized for distinct clinical purposes. Previous CSSL frameworks often mitigated domain shift by reusing past data, a typically impractical approach owing to privacy constraints. Our approach addresses these challenges by effectively capturing the relationship between previously learned knowledge and new information across different training stages through continual pretraining on unlabeled images. Specifically, by incorporating a latent replay-based mechanism into CSSL, our method mitigates catastrophic forgetting due to domain shifts during continual pretraining while ensuring data privacy. Additionally, we introduce a feature distillation technique that integrates Wasserstein distance-based knowledge distillation (WKD) and batch-knowledge ensemble (BKE), enhancing the ability of the model to learn meaningful, domain-shift-robust representations. Finally, we validate our approach using chest CT images obtained across two different window settings, demonstrating superior performance compared with other approaches.
Adaptive Shared Experts with LoRA-Based Mixture of Experts for Multi-Task Learning
Oct 01, 2025Mixture-of-Experts (MoE) has emerged as a powerful framework for multi-task learning (MTL). However, existing MoE-MTL methods often rely on single-task pretrained backbones and suffer from redundant adaptation and inefficient knowledge sharing during the transition from single-task to multi-task learning (STL to MTL). To address these limitations, we propose adaptive shared experts (ASE) within a low-rank adaptation (LoRA) based MoE, where shared experts are assigned router-computed gating weights jointly normalized with sparse experts. This design facilitates STL to MTL transition, enhances expert specialization, and cooperation. Furthermore, we incorporate fine-grained experts by increasing the number of LoRA experts while proportionally reducing their rank, enabling more effective knowledge sharing under a comparable parameter budget. Extensive experiments on the PASCAL-Context benchmark, under unified training settings, demonstrate that ASE consistently improves performance across diverse configurations and validates the effectiveness of fine-grained designs for MTL.
Objectness Similarity: Capturing Object-Level Fidelity in 3D Scene Evaluation
Sep 11, 2025This paper presents Objectness SIMilarity (OSIM), a novel evaluation metric for 3D scenes that explicitly focuses on "objects," which are fundamental units of human visual perception. Existing metrics assess overall image quality, leading to discrepancies with human perception. Inspired by neuropsychological insights, we hypothesize that human recognition of 3D scenes fundamentally involves attention to individual objects. OSIM enables object-centric evaluations by leveraging an object detection model and its feature representations to quantify the "objectness" of each object in the scene. Our user study demonstrates that OSIM aligns more closely with human perception compared to existing metrics. We also analyze the characteristics of OSIM using various approaches. Moreover, we re-evaluate recent 3D reconstruction and generation models under a standardized experimental setup to clarify advancements in this field. The code is available at https://github.com/Objectness-Similarity/OSIM.
Hyperbolic Dataset Distillation
May 30, 2025To address the computational and storage challenges posed by large-scale datasets in deep learning, dataset distillation has been proposed to synthesize a compact dataset that replaces the original while maintaining comparable model performance. Unlike optimization-based approaches that require costly bi-level optimization, distribution matching (DM) methods improve efficiency by aligning the distributions of synthetic and original data, thereby eliminating nested optimization. DM achieves high computational efficiency and has emerged as a promising solution. However, existing DM methods, constrained to Euclidean space, treat data as independent and identically distributed points, overlooking complex geometric and hierarchical relationships. To overcome this limitation, we propose a novel hyperbolic dataset distillation method, termed HDD. Hyperbolic space, characterized by negative curvature and exponential volume growth with distance, naturally models hierarchical and tree-like structures. HDD embeds features extracted by a shallow network into the Lorentz hyperbolic space, where the discrepancy between synthetic and original data is measured by the hyperbolic (geodesic) distance between their centroids. By optimizing this distance, the hierarchical structure is explicitly integrated into the distillation process, guiding synthetic samples to gravitate towards the root-centric regions of the original data distribution while preserving their underlying geometric characteristics. Furthermore, we find that pruning in hyperbolic space requires only 20% of the distilled core set to retain model performance, while significantly improving training stability. Notably, HDD is seamlessly compatible with most existing DM methods, and extensive experiments on different datasets validate its effectiveness.
Diversity-Driven Generative Dataset Distillation Based on Diffusion Model with Self-Adaptive Memory
May 26, 2025Dataset distillation enables the training of deep neural networks with comparable performance in significantly reduced time by compressing large datasets into small and representative ones. Although the introduction of generative models has made great achievements in this field, the distributions of their distilled datasets are not diverse enough to represent the original ones, leading to a decrease in downstream validation accuracy. In this paper, we present a diversity-driven generative dataset distillation method based on a diffusion model to solve this problem. We introduce self-adaptive memory to align the distribution between distilled and real datasets, assessing the representativeness. The degree of alignment leads the diffusion model to generate more diverse datasets during the distillation process. Extensive experiments show that our method outperforms existing state-of-the-art methods in most situations, proving its ability to tackle dataset distillation tasks.
StarMAP: Global Neighbor Embedding for Faithful Data Visualization
Feb 06, 2025


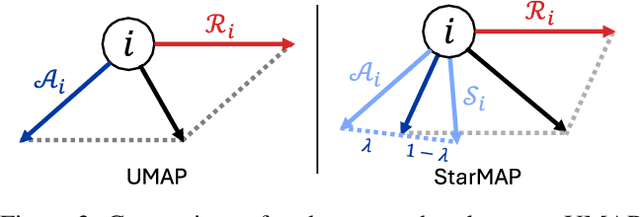
Neighbor embedding is widely employed to visualize high-dimensional data; however, it frequently overlooks the global structure, e.g., intercluster similarities, thereby impeding accurate visualization. To address this problem, this paper presents Star-attracted Manifold Approximation and Projection (StarMAP), which incorporates the advantage of principal component analysis (PCA) in neighbor embedding. Inspired by the property of PCA embedding, which can be viewed as the largest shadow of the data, StarMAP introduces the concept of \textit{star attraction} by leveraging the PCA embedding. This approach yields faithful global structure preservation while maintaining the interpretability and computational efficiency of neighbor embedding. StarMAP was compared with existing methods in the visualization tasks of toy datasets, single-cell RNA sequencing data, and deep representation. The experimental results show that StarMAP is simple but effective in realizing faithful visualizations.