 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Federated Learning with Dynamic Clustering and Adaptive Regularization for Robust Infrastructure Inspection
Jun 02, 2026The deployment of data-driven computer vision models for structural health monitoring (SHM) is heavily constrained by the data silo dilemma due to stringent privacy and security regulations. While federated learning (FL) offers a privacy-preserving collaborative alternative, its application to nationwide infrastructure networks is severely hindered by the challenge of ``double heterogeneity'': macro-level physical divergence across disparate structural types and micro-level statistical imbalances within local datasets. To overcome this challenge, this paper proposes a novel hierarchical federated learning framework. The framework orchestrates a synergistic two-tier optimization strategy. At the macro-level, a dynamic gradient-based clustering mechanism autonomously aggregates distributed clients into specialized expert groups based on their structural degradation trajectories, circumventing the need for prior geographical metadata. Concurrently, at the micro-level, an intra-cluster Dynamic Region-Adaptive Proximal Regularization (DRAPR) module computes a real-time statistical Non-IID Intensity Score for each client. By adaptively modulating a proximal penalty based on local label skewness and gradient divergence, DRAPR effectively calibrates local updates, mitigates client drift, and prevents the catastrophic forgetting of minority damage classes. Comprehensive evaluations on a large-scale, real-world structural inspection dataset demonstrate that the hierarchical integration of macro-clustering and micro-regularization successfully neutralizes dual-level heterogeneity, yielding highly robust and specialized diagnostic models for complex infrastructure inspection.
Foreground-Aware Dataset Distillation via Dynamic Patch Selection
Jan 06, 2026In this paper, we propose a foreground-aware dataset distillation method that enhances patch selection in a content-adaptive manner. With the rising computational cost of training large-scale deep models, dataset distillation has emerged as a promising approach for constructing compact synthetic datasets that retain the knowledge of their large original counterparts. However, traditional optimization-based methods often suffer from high computational overhead, memory constraints, and the generation of unrealistic, noise-like images with limited architectural generalization. Recent non-optimization methods alleviate some of these issues by constructing distilled data from real image patches, but the used rigid patch selection strategies can still discard critical information about the main objects. To solve this problem, we first leverage Grounded SAM2 to identify foreground objects and compute per-image foreground occupancy, from which we derive a category-wise patch decision threshold. Guided by these thresholds, we design a dynamic patch selection strategy that, for each image, either selects the most informative patch from multiple candidates or directly resizes the full image when the foreground dominates. This dual-path mechanism preserves more key information about the main objects while reducing redundant background content. Extensive experiments on multiple benchmarks show that the proposed method consistently improves distillation performance over existing approaches, producing more informative and representative distilled datasets and enhancing robustness across different architectures and image compositions.
Objectness Similarity: Capturing Object-Level Fidelity in 3D Scene Evaluation
Sep 11, 2025This paper presents Objectness SIMilarity (OSIM), a novel evaluation metric for 3D scenes that explicitly focuses on "objects," which are fundamental units of human visual perception. Existing metrics assess overall image quality, leading to discrepancies with human perception. Inspired by neuropsychological insights, we hypothesize that human recognition of 3D scenes fundamentally involves attention to individual objects. OSIM enables object-centric evaluations by leveraging an object detection model and its feature representations to quantify the "objectness" of each object in the scene. Our user study demonstrates that OSIM aligns more closely with human perception compared to existing metrics. We also analyze the characteristics of OSIM using various approaches. Moreover, we re-evaluate recent 3D reconstruction and generation models under a standardized experimental setup to clarify advancements in this field. The code is available at https://github.com/Objectness-Similarity/OSIM.
Hyperbolic Dataset Distillation
May 30, 2025To address the computational and storage challenges posed by large-scale datasets in deep learning, dataset distillation has been proposed to synthesize a compact dataset that replaces the original while maintaining comparable model performance. Unlike optimization-based approaches that require costly bi-level optimization, distribution matching (DM) methods improve efficiency by aligning the distributions of synthetic and original data, thereby eliminating nested optimization. DM achieves high computational efficiency and has emerged as a promising solution. However, existing DM methods, constrained to Euclidean space, treat data as independent and identically distributed points, overlooking complex geometric and hierarchical relationships. To overcome this limitation, we propose a novel hyperbolic dataset distillation method, termed HDD. Hyperbolic space, characterized by negative curvature and exponential volume growth with distance, naturally models hierarchical and tree-like structures. HDD embeds features extracted by a shallow network into the Lorentz hyperbolic space, where the discrepancy between synthetic and original data is measured by the hyperbolic (geodesic) distance between their centroids. By optimizing this distance, the hierarchical structure is explicitly integrated into the distillation process, guiding synthetic samples to gravitate towards the root-centric regions of the original data distribution while preserving their underlying geometric characteristics. Furthermore, we find that pruning in hyperbolic space requires only 20% of the distilled core set to retain model performance, while significantly improving training stability. Notably, HDD is seamlessly compatible with most existing DM methods, and extensive experiments on different datasets validate its effectiveness.
StarMAP: Global Neighbor Embedding for Faithful Data Visualization
Feb 06, 2025


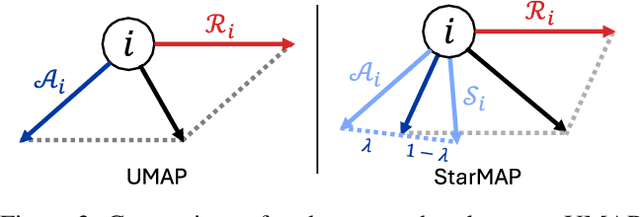
Neighbor embedding is widely employed to visualize high-dimensional data; however, it frequently overlooks the global structure, e.g., intercluster similarities, thereby impeding accurate visualization. To address this problem, this paper presents Star-attracted Manifold Approximation and Projection (StarMAP), which incorporates the advantage of principal component analysis (PCA) in neighbor embedding. Inspired by the property of PCA embedding, which can be viewed as the largest shadow of the data, StarMAP introduces the concept of \textit{star attraction} by leveraging the PCA embedding. This approach yields faithful global structure preservation while maintaining the interpretability and computational efficiency of neighbor embedding. StarMAP was compared with existing methods in the visualization tasks of toy datasets, single-cell RNA sequencing data, and deep representation. The experimental results show that StarMAP is simple but effective in realizing faithful visualizations.
Generative Dataset Distillation Based on Self-knowledge Distillation
Jan 08, 2025



Dataset distillation is an effective technique for reducing the cost and complexity of model training while maintaining performance by compressing large datasets into smaller, more efficient versions. In this paper, we present a novel generative dataset distillation method that can improve the accuracy of aligning prediction logits. Our approach integrates self-knowledge distillation to achieve more precise distribution matching between the synthetic and original data, thereby capturing the overall structure and relationships within the data. To further improve the accuracy of alignment, we introduce a standardization step on the logits before performing distribution matching, ensuring consistency in the range of logits. Through extensive experiments, we demonstrate that our method outperforms existing state-of-the-art methods, resulting in superior distillation performance.
Hyperboloid GPLVM for Discovering Continuous Hierarchies via Nonparametric Estimation
Oct 22, 2024



Dimensionality reduction (DR) offers a useful representation of complex high-dimensional data. Recent DR methods focus on hyperbolic geometry to derive a faithful low-dimensional representation of hierarchical data. However, existing methods are based on neighbor embedding, frequently ruining the continual relation of the hierarchies. This paper presents hyperboloid Gaussian process (GP) latent variable models (hGP-LVMs) to embed high-dimensional hierarchical data with implicit continuity via nonparametric estimation. We adopt generative modeling using the GP, which brings effective hierarchical embedding and executes ill-posed hyperparameter tuning. This paper presents three variants that employ original point, sparse point, and Bayesian estimations. We establish their learning algorithms by incorporating the Riemannian optimization and active approximation scheme of GP-LVM. For Bayesian inference, we further introduce the reparameterization trick to realize Bayesian latent variable learning. In the last part of this paper, we apply hGP-LVMs to several datasets and show their ability to represent high-dimensional hierarchies in low-dimensional spaces.
Think Twice Before Recognizing: Large Multimodal Models for General Fine-grained Traffic Sign Recognition
Sep 03, 2024
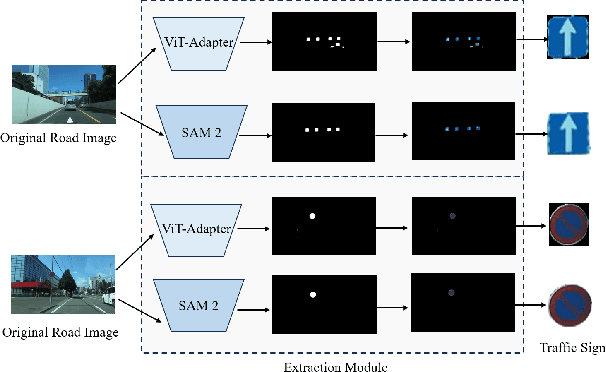

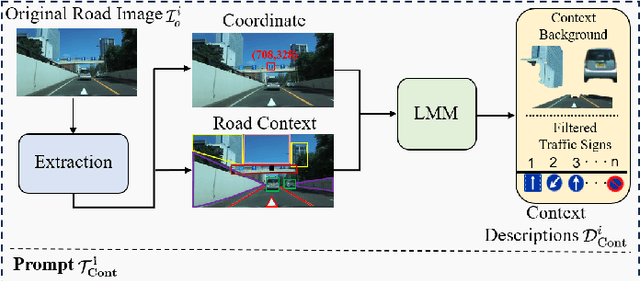
We propose a new strategy called think twice before recognizing to improve fine-grained traffic sign recognition (TSR). Fine-grained TSR in the wild is difficult due to the complex road conditions, and existing approaches particularly struggle with cross-country TSR when data is lacking. Our strategy achieves effective fine-grained TSR by stimulating the multiple-thinking capability of large multimodal models (LMM). We introduce context, characteristic, and differential descriptions to design multiple thinking processes for the LMM. The context descriptions with center coordinate prompt optimization help the LMM to locate the target traffic sign in the original road images containing multiple traffic signs and filter irrelevant answers through the proposed prior traffic sign hypothesis. The characteristic description is based on few-shot in-context learning of template traffic signs, which decreases the cross-domain difference and enhances the fine-grained recognition capability of the LMM. The differential descriptions of similar traffic signs optimize the multimodal thinking capability of the LMM. The proposed method is independent of training data and requires only simple and uniform instructions. We conducted extensive experiments on three benchmark datasets and two real-world datasets from different countries, and the proposed method achieves state-of-the-art TSR results on all five datasets.
Cross-domain Few-shot In-context Learning for Enhancing Traffic Sign Recognition
Jul 08, 2024

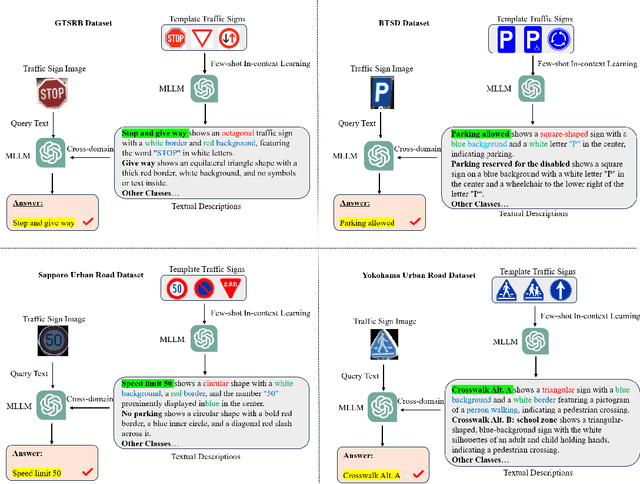

Recent multimodal large language models (MLLM) such as GPT-4o and GPT-4v have shown great potential in autonomous driving. In this paper, we propose a cross-domain few-shot in-context learning method based on the MLLM for enhancing traffic sign recognition (TSR). We first construct a traffic sign detection network based on Vision Transformer Adapter and an extraction module to extract traffic signs from the original road images. To reduce the dependence on training data and improve the performance stability of cross-country TSR, we introduce a cross-domain few-shot in-context learning method based on the MLLM. To enhance MLLM's fine-grained recognition ability of traffic signs, the proposed method generates corresponding description texts using template traffic signs. These description texts contain key information about the shape, color, and composition of traffic signs, which can stimulate the ability of MLLM to perceive fine-grained traffic sign categories. By using the description texts, our method reduces the cross-domain differences between template and real traffic signs. Our approach requires only simple and uniform textual indications, without the need for large-scale traffic sign images and labels. We perform comprehensive evaluations on the German traffic sign recognition benchmark dataset, the Belgium traffic sign dataset, and two real-world datasets taken from Japan. The experimental results show that our method significantly enhances the TSR performance.
Reinforcing Pre-trained Models Using Counterfactual Images
Jun 19, 2024



This paper proposes a novel framework to reinforce classification models using language-guided generated counterfactual images. Deep learning classification models are often trained using datasets that mirror real-world scenarios. In this training process, because learning is based solely on correlations with labels, there is a risk that models may learn spurious relationships, such as an overreliance on features not central to the subject, like background elements in images. However, due to the black-box nature of the decision-making process in deep learning models, identifying and addressing these vulnerabilities has been particularly challenging. We introduce a novel framework for reinforcing the classification models, which consists of a two-stage process. First, we identify model weaknesses by testing the model using the counterfactual image dataset, which is generated by perturbed image captions. Subsequently, we employ the counterfactual images as an augmented dataset to fine-tune and reinforce the classification model. Through extensive experiments on several classification models across various datasets, we revealed that fine-tuning with a small set of counterfactual images effectively strengthens the model.