 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Twice Before Recognizing: Large Multimodal Models for General Fine-grained Traffic Sign Recognition
Sep 03, 2024

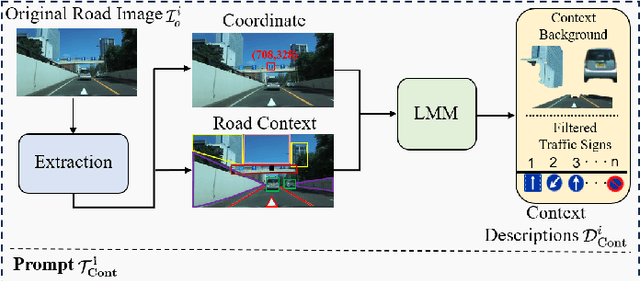
We propose a new strategy called think twice before recognizing to improve fine-grained traffic sign recognition (TSR). Fine-grained TSR in the wild is difficult due to the complex road conditions, and existing approaches particularly struggle with cross-country TSR when data is lacking. Our strategy achieves effective fine-grained TSR by stimulating the multiple-thinking capability of large multimodal models (LMM). We introduce context, characteristic, and differential descriptions to design multiple thinking processes for the LMM. The context descriptions with center coordinate prompt optimization help the LMM to locate the target traffic sign in the original road images containing multiple traffic signs and filter irrelevant answers through the proposed prior traffic sign hypothesis. The characteristic description is based on few-shot in-context learning of template traffic signs, which decreases the cross-domain difference and enhances the fine-grained recognition capability of the LMM. The differential descriptions of similar traffic signs optimize the multimodal thinking capability of the LMM. The proposed method is independent of training data and requires only simple and uniform instructions. We conducted extensive experiments on three benchmark datasets and two real-world datasets from different countries, and the proposed method achieves state-of-the-art TSR results on all five datasets.
Cross-domain Few-shot In-context Learning for Enhancing Traffic Sign Recognition
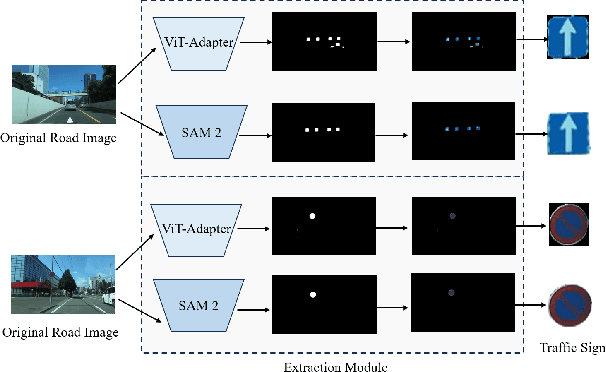
Jul 08, 2024

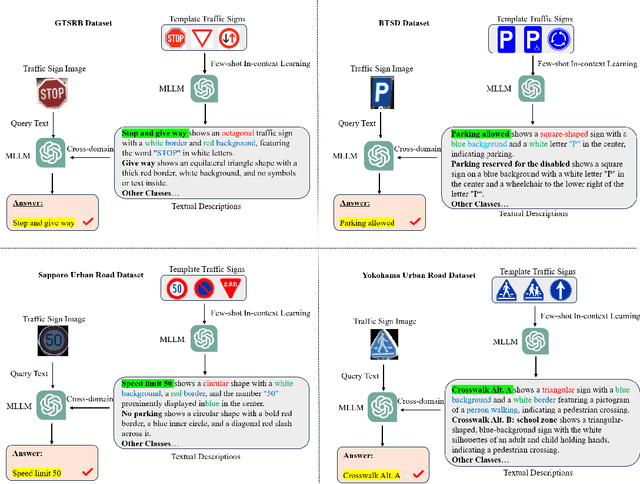

Recent multimodal large language models (MLLM) such as GPT-4o and GPT-4v have shown great potential in autonomous driving. In this paper, we propose a cross-domain few-shot in-context learning method based on the MLLM for enhancing traffic sign recognition (TSR). We first construct a traffic sign detection network based on Vision Transformer Adapter and an extraction module to extract traffic signs from the original road images. To reduce the dependence on training data and improve the performance stability of cross-country TSR, we introduce a cross-domain few-shot in-context learning method based on the MLLM. To enhance MLLM's fine-grained recognition ability of traffic signs, the proposed method generates corresponding description texts using template traffic signs. These description texts contain key information about the shape, color, and composition of traffic signs, which can stimulate the ability of MLLM to perceive fine-grained traffic sign categories. By using the description texts, our method reduces the cross-domain differences between template and real traffic signs. Our approach requires only simple and uniform textual indications, without the need for large-scale traffic sign images and labels. We perform comprehensive evaluations on the German traffic sign recognition benchmark dataset, the Belgium traffic sign dataset, and two real-world datasets taken from Japan. The experimental results show that our method significantly enhances the TSR performance.