 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cylindrical Representation Hypothesis for Language Model Steering
May 03, 2026Steering is a widely used technique for controlling large language models, yet its effects are often unstable and hard to predict. Existing theoretical accounts are largely based on the Linear Representation Hypothesis (LRH). While LRH assumes that concepts can be orthogonalized for lossless control, this idealized mapping fails in real representations and cannot account for the observed unpredictability of steering. By relaxing LRH's orthogonality assumption while preserving linear representations, we show that overlapping concept contributions naturally yield a sample-specific axis-orthogonal structure. We formalize this as the Cylindrical Representation Hypothesis (CRH). In CRH, a central axis captures the main difference between concept absence and presence and drives concept generation. A surrounding normal plane controls steering sensitivity by determining how easily the axis can activate the target concept. Within this plane, only specific sensitive sectors strongly facilitate concept activation, while other sectors can suppress or delay it. While the surrounding normal plane can be reliably identified from difference vectors, the sensitive sector cannot, introducing intrinsic uncertainty at the sector level. This uncertainty provides a principled explanation for why steering outcomes often fluctuate even when using well-aligned directions. Our experiments verify the existence of the cylindrical structure and demonstrate that CRH provides a valid and practical way to interpret model steering behavior in real settings: https://github.com/mbzuai-nlp/CRH.
ServImage: An Image Generation and Editing Benchmark from Real-world Commercial Imaging Services
Apr 27, 2026Recent image generation and editing models demonstrate robust adherence to instructions and high visual quality on academic benchmarks. However, their performance on paid, real-world design projects remains uncertain. We introduce \textbf{ServImage}, a benchmark that explicitly correlates model outputs with economic value in commercial design projects. ServImage consists of (i) \textbf{\textit{ServImageBench}}: a dataset of 1.07k paid commercial design tasks and 2.05k designer deliverables totaling over \$295k, covering portrait, product, and digital content, along with 33k candidate images and 33k human annotations. (ii) \textbf{\textit{ServImageScore}}: an integrated scoring system that combines three quality dimensions: baseline requirements fulfilment, visual execution quality, and commercial necessity satisfaction. These three dimensions are designed to characterize the factors that drive human payment decisions and indicate whether an image is commercially acceptable. (iii) \textbf{\textit{ServImageModel}}: under this scoring system, we propose a payment prediction model trained on the human-annotated candidate images, achieving 82.00\% accuracy in predicting human payment decisions and producing calibrated payment probabilities. ServImage provides a comprehensive foundation for assessing the commercial viability of image generation models and offers a scalable resource for future research on economically grounded vision systems \href{https://github.com/FengxianJi/ServImage}{Github.}
M3MAD-Bench: Are Multi-Agent Debates Really Effective Across Domains and Modalities?
Jan 06, 2026As an agent-level reasoning and coordination paradigm, Multi-Agent Debate (MAD) orchestrates multiple agents through structured debate to improve answer quality and support complex reasoning. However, existing research on MAD suffers from two fundamental limitations: evaluations are conducted under fragmented and inconsistent settings, hindering fair comparison, and are largely restricted to single-modality scenarios that rely on textual inputs only. To address these gaps, we introduce M3MAD-Bench, a unified and extensible benchmark for evaluating MAD methods across Multi-domain tasks, Multi-modal inputs, and Multi-dimensional metrics. M3MAD-Bench establishes standardized protocols over five core task domains: Knowledge, Mathematics, Medicine, Natural Sciences, and Complex Reasoning, and systematically covers both pure text and vision-language datasets, enabling controlled cross-modality comparison. We evaluate MAD methods on nine base models spanning different architectures, scales, and modality capabilities. Beyond accuracy, M3MAD-Bench incorporates efficiency-oriented metrics such as token consumption and inference time, providing a holistic view of performance--cost trade-offs. Extensive experiments yield systematic insights into the effectiveness, robustness, and efficiency of MAD across text-only and multimodal scenarios. We believe M3MAD-Bench offers a reliable foundation for future research on standardized MAD evaluation. The code is available at http://github.com/liaolea/M3MAD-Bench.
Otter: Mitigating Background Distractions of Wide-Angle Few-Shot Action Recognition with Enhanced RWKV
Nov 11, 2025Wide-angle videos in few-shot action recognition (FSAR) effectively express actions within specific scenarios. However, without a global understanding of both subjects and background, recognizing actions in such samples remains challenging because of the background distractions. Receptance Weighted Key Value (RWKV), which learns interaction between various dimensions, shows promise for global modeling. While directly applying RWKV to wide-angle FSAR may fail to highlight subjects due to excessive background information. Additionally, temporal relation degraded by frames with similar backgrounds is difficult to reconstruct, further impacting performance. Therefore, we design the CompOund SegmenTation and Temporal REconstructing RWKV (Otter). Specifically, the Compound Segmentation Module~(CSM) is devised to segment and emphasize key patches in each frame, effectively highlighting subjects against background information. The Temporal Reconstruction Module (TRM) is incorporated into the temporal-enhanced prototype construction to enable bidirectional scanning, allowing better reconstruct temporal relation. Furthermore, a regular prototype is combined with the temporal-enhanced prototype to simultaneously enhance subject emphasis and temporal modeling, improving wide-angle FSAR performance. Extensive experiments on benchmarks such as SSv2, Kinetics, UCF101, and HMDB51 demonstrate that Otter achieves state-of-the-art performance. Extra evaluation on the VideoBadminton dataset further validates the superiority of Otter in wide-angle FSAR.
When Personalization Tricks Detectors: The Feature-Inversion Trap in Machine-Generated Text Detection
Oct 14, 2025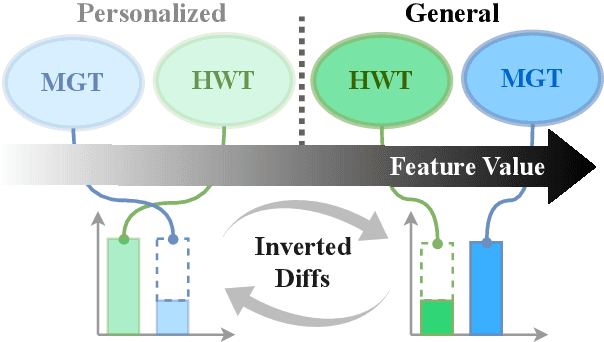

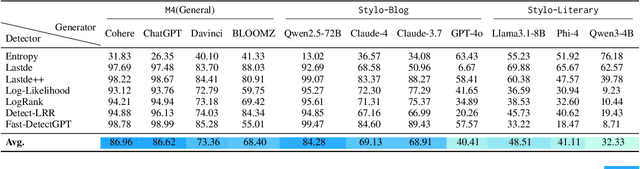
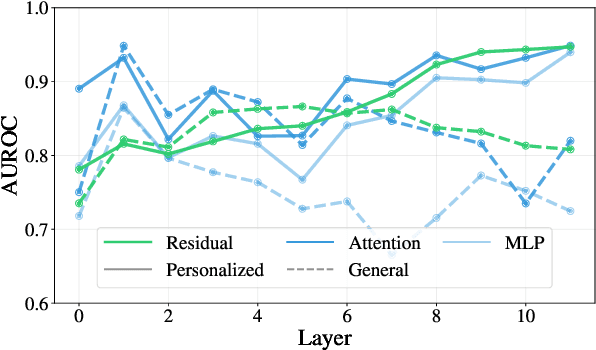
Large language models (LLMs) have grown more powerful in language generation, producing fluent text and even imitating personal style. Yet, this ability also heightens the risk of identity impersonation. To the best of our knowledge, no prior work has examined personalized machine-generated text (MGT) detection. In this paper, we introduce \dataset, the first benchmark for evaluating detector robustness in personalized settings, built from literary and blog texts paired with their LLM-generated imitations. Our experimental results demonstrate large performance gaps across detectors in personalized settings: some state-of-the-art models suffer significant drops. We attribute this limitation to the \textit{feature-inversion trap}, where features that are discriminative in general domains become inverted and misleading when applied to personalized text. Based on this finding, we propose \method, a simple and reliable way to predict detector performance changes in personalized settings. \method identifies latent directions corresponding to inverted features and constructs probe datasets that differ primarily along these features to evaluate detector dependence. Our experiments show that \method can accurately predict both the direction and the magnitude of post-transfer changes, showing 85\% correlation with the actual performance gaps. We hope that this work will encourage further research on personalized text detection.
TransPrune: Token Transition Pruning for Efficient Large Vision-Language Model
Jul 28, 2025Large Vision-Language Models (LVLMs) have advanced multimodal learning but face high computational costs due to the large number of visual tokens, motivating token pruning to improve inference efficiency. The key challenge lies in identifying which tokens are truly important. Most existing approaches rely on attention-based criteria to estimate token importance. However, they inherently suffer from certain limitations, such as positional bias. In this work, we explore a new perspective on token importance based on token transitions in LVLMs. We observe that the transition of token representations provides a meaningful signal of semantic information. Based on this insight, we propose TransPrune, a training-free and efficient token pruning method. Specifically, TransPrune progressively prunes tokens by assessing their importance through a combination of Token Transition Variation (TTV)-which measures changes in both the magnitude and direction of token representations-and Instruction-Guided Attention (IGA), which measures how strongly the instruction attends to image tokens via attention. Extensive experiments demonstrate that TransPrune achieves comparable multimodal performance to original LVLMs, such as LLaVA-v1.5 and LLaVA-Next, across eight benchmarks, while reducing inference TFLOPs by more than half. Moreover, TTV alone can serve as an effective criterion without relying on attention, achieving performance comparable to attention-based methods. The code will be made publicly available upon acceptance of the paper at https://github.com/liaolea/TransPrune.
Boundary Prompting: Elastic Urban Region Representation via Graph-based Spatial Tokenization
Mar 11, 2025Urban region representation is essential for various applications such as urban planning, resource allocation, and policy development. Traditional methods rely on fixed, predefined region boundaries, which fail to capture the dynamic and complex nature of real-world urban areas. In this paper, we propose the Boundary Prompting Urban Region Representation Framework (BPURF), a novel approach that allows for elastic urban region definitions. BPURF comprises two key components: (1) A spatial token dictionary, where urban entities are treated as tokens and integrated into a unified token graph, and (2) a region token set representation model which utilize token aggregation and a multi-channel model to embed token sets corresponding to region boundaries. Additionally, we propose fast token set extraction strategy to enable online token set extraction during training and prompting. This framework enables the definition of urban regions through boundary prompting, supporting varying region boundaries and adapting to different tasks. Extensive experiments demonstrate the effectiveness of BPURF in capturing the complex characteristics of urban regions.
Modeling Variants of Prompts for Vision-Language Models
Mar 11, 2025Large pre-trained vision-language models (VLMs) offer a promising approach to leveraging human language for enhancing downstream tasks. However, VLMs such as CLIP face significant limitation: its performance is highly sensitive to prompt template design. Although prompt learning methods can address the sensitivity issue by replacing natural language prompts with learnable ones, they are incomprehensible to humans. Ensuring consistent performance across various prompt templates enables models to adapt seamlessly to diverse phrasings, enhancing their ability to handle downstream tasks without requiring extensive prompt engineering. In this work, we introduce the RobustPrompt Benchmark, a systematic benchmark to evaluate robustness to different prompt templates for VLMs. It includes a dataset with hundreds of carefully designed prompt templates, divided into six types, covering a wide variety of commonly used templates. Beside the benchmark, we propose Modeling Variants of Prompts (MVP), a simple yet effective method that mitigates sensitivity by modeling variants of prompt structures. The innovation of MVP lies in decoupling prompts into templates and class names, and using Variational Autoencoders (VAE) to model the distribution of diverse prompt structures. Experiments across 11 datasets demonstrate that MVP can greatly enhance model robustness to variations in input prompts without a drop in performance. The code is available at https://github.com/xiaoyaoxinyi/MVP.
M2SE: A Multistage Multitask Instruction Tuning Strategy for Unified Sentiment and Emotion Analysis
Dec 11, 2024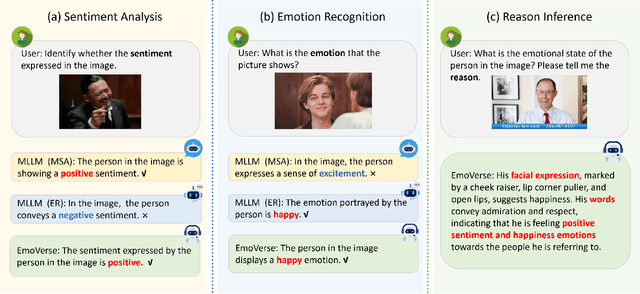
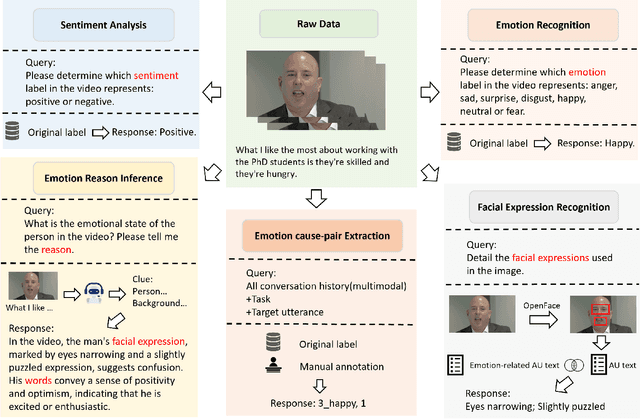


Sentiment analysis and emotion recognition are crucial for applications such as human-computer interaction and depression detection. Traditional unimodal methods often fail to capture the complexity of emotional expressions due to conflicting signals from different modalities. Current Multimodal Large Language Models (MLLMs) also face challenges in detecting subtle facial expressions and addressing a wide range of emotion-related tasks. To tackle these issues, we propose M2SE, a Multistage Multitask Sentiment and Emotion Instruction Tuning Strategy for general-purpose MLLMs. It employs a combined approach to train models on tasks such as multimodal sentiment analysis, emotion recognition, facial expression recognition, emotion reason inference, and emotion cause-pair extraction. We also introduce the Emotion Multitask dataset (EMT), a custom dataset that supports these five tasks. Our model, Emotion Universe (EmoVerse), is built on a basic MLLM framework without modifications, yet it achieves substantial improvements across these tasks when trained with the M2SE strategy. Extensive experiments demonstrate that EmoVerse outperforms existing methods, achieving state-of-the-art results in sentiment and emotion tasks. These results highlight the effectiveness of M2SE in enhancing multimodal emotion perception. The dataset and code are available at https://github.com/xiaoyaoxinyi/M2SE.
Manta: Enhancing Mamba for Few-Shot Action Recognition of Long Sub-Sequence
Dec 10, 2024



In few-shot action recognition~(FSAR), long sub-sequences of video naturally express entire actions more effectively. However, the computational complexity of mainstream Transformer-based methods limits their application. Recent Mamba demonstrates efficiency in modeling long sequences, but directly applying Mamba to FSAR overlooks the importance of local feature modeling and alignment. Moreover, long sub-sequences within the same class accumulate intra-class variance, which adversely impacts FSAR performance. To solve these challenges, we propose a \underline{\textbf{M}}atryoshka M\underline{\textbf{A}}mba and Co\underline{\textbf{N}}tras\underline{\textbf{T}}ive Le\underline{\textbf{A}}rning framework~(\textbf{Manta}). Firstly, the Matryoshka Mamba introduces multiple Inner Modules to enhance local feature representation, rather than directly modeling global features. An Outer Module captures dependencies of timeline between these local features for implicit temporal alignment. Secondly, a hybrid contrastive learning paradigm, combining both supervised and unsupervised methods, is designed to mitigate the negative effects of intra-class variance accumulation. The Matryoshka Mamba and the hybrid contrastive learning paradigm operate in parallel branches within Manta, enhancing Mamba for FSAR of long sub-sequence. Manta achieves new state-of-the-art performance on prominent benchmarks, including SSv2, Kinetics, UCF101, and HMDB51. Extensive empirical studies prove that Manta significantly improves FSAR of long sub-sequence from multiple perspectives. The code is released at https://github.com/wenbohuang1002/Manta.