 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDTTNet: Improving Video Shadow Detection via Dark-Aware Guidance and Tokenized Temporal Modeling
Nov 10, 2025Video shadow detection confronts two entwined difficulties: distinguishing shadows from complex backgrounds and modeling dynamic shadow deformations under varying illumination. To address shadow-background ambiguity, we leverage linguistic priors through the proposed Vision-language Match Module (VMM) and a Dark-aware Semantic Block (DSB), extracting text-guided features to explicitly differentiate shadows from dark objects. Furthermore, we introduce adaptive mask reweighting to downweight penumbra regions during training and apply edge masks at the final decoder stage for better supervision. For temporal modeling of variable shadow shapes, we propose a Tokenized Temporal Block (TTB) that decouples spatiotemporal learning. TTB summarizes cross-frame shadow semantics into learnable temporal tokens, enabling efficient sequence encoding with minimal computation overhead. Comprehensive Experiments on multiple benchmark datasets demonstrate state-of-the-art accuracy and real-time inference efficiency. Codes are available at https://github.com/city-cheng/DTTNet.
NeRF-based CBCT Reconstruction needs Normalization and Initialization
Jun 24, 2025Cone Beam Computed Tomography (CBCT) is widely used in medical imaging. However, the limited number and intensity of X-ray projections make reconstruction an ill-posed problem with severe artifacts. NeRF-based methods have achieved great success in this task. However, they suffer from a local-global training mismatch between their two key components: the hash encoder and the neural network. Specifically, in each training step, only a subset of the hash encoder's parameters is used (local sparse), whereas all parameters in the neural network participate (global dense). Consequently, hash features generated in each step are highly misaligned, as they come from different subsets of the hash encoder. These misalignments from different training steps are then fed into the neural network, causing repeated inconsistent global updates in training, which leads to unstable training, slower convergence, and degraded reconstruction quality. Aiming to alleviate the impact of this local-global optimization mismatch, we introduce a Normalized Hash Encoder, which enhances feature consistency and mitigates the mismatch. Additionally, we propose a Mapping Consistency Initialization(MCI) strategy that initializes the neural network before training by leveraging the global mapping property from a well-trained model. The initialized neural network exhibits improved stability during early training, enabling faster convergence and enhanced reconstruction performance. Our method is simple yet effective, requiring only a few lines of code while substantially improving training efficiency on 128 CT cases collected from 4 different datasets, covering 7 distinct anatomical regions.
AtomR: Atomic Operator-Empowered Large Language Models for Heterogeneous Knowledge Reasoning
Nov 25, 2024



Recent advancements in large language models (LLMs) have led to significant improvements in various natural language processing tasks, but it is still challenging for LLMs to perform knowledge-intensive complex question answering due to LLMs' inefficacy in reasoning planning and the hallucination problem. A typical solution is to employ retrieval-augmented generation (RAG) coupled with chain-of-thought (CoT) reasoning, which decomposes complex questions into chain-like sub-questions and applies iterative RAG at each sub-question. However, prior works exhibit sub-optimal reasoning planning and overlook dynamic knowledge retrieval from heterogeneous sources. In this paper, we propose AtomR, a novel heterogeneous knowledge reasoning framework that conducts multi-source reasoning at the atomic level. Drawing inspiration from the graph modeling of knowledge, AtomR leverages large language models (LLMs) to decompose complex questions into combinations of three atomic knowledge operators, significantly enhancing the reasoning process at both the planning and execution stages. We also introduce BlendQA, a novel evaluation benchmark tailored to assess complex heterogeneous knowledge reasoning. Experiments show that AtomR significantly outperforms state-of-the-art baselines across three single-source and two multi-source reasoning benchmarks, with notable performance gains of 9.4% on 2WikiMultihop and 9.5% on BlendQA.
Urban Region Pre-training and Prompting: A Graph-based Approach
Aug 12, 2024



Urban region representation is crucial for various urban downstream tasks. However, despite the proliferation of methods and their success, acquiring general urban region knowledge and adapting to different tasks remains challenging. Previous work often neglects the spatial structures and functional layouts between entities, limiting their ability to capture transferable knowledge across regions. Further, these methods struggle to adapt effectively to specific downstream tasks, as they do not adequately address the unique features and relationships required for different downstream tasks. In this paper, we propose a $\textbf{G}$raph-based $\textbf{U}$rban $\textbf{R}$egion $\textbf{P}$re-training and $\textbf{P}$rompting framework ($\textbf{GURPP}$) for region representation learning. Specifically, we first construct an urban region graph that integrates detailed spatial entity data for more effective urban region representation. Then, we develop a subgraph-centric urban region pre-training model to capture the heterogeneous and transferable patterns of interactions among entities. To further enhance the adaptability of these embeddings to different tasks, we design two graph-based prompting methods to incorporate explicit/hidden task knowledge. Extensive experiments on various urban region prediction tasks and different cities demonstrate the superior performance of our GURPP framework. The implementation is available at this repository: https://anonymous.4open.science/r/GURPP.
Punctuation Matters! Stealthy Backdoor Attack for Language Models
Dec 26, 2023Recent studies have pointed out that natural language processing (NLP) models are vulnerable to backdoor attacks. A backdoored model produces normal outputs on the clean samples while performing improperly on the texts with triggers that the adversary injects. However, previous studies on textual backdoor attack pay little attention to stealthiness. Moreover, some attack methods even cause grammatical issues or change the semantic meaning of the original texts. Therefore, they can easily be detected by humans or defense systems. In this paper, we propose a novel stealthy backdoor attack method against textual models, which is called \textbf{PuncAttack}. It leverages combinations of punctuation marks as the trigger and chooses proper locations strategically to replace them. Through extensive experiments, we demonstrate that the proposed method can effectively compromise multiple models in various tasks. Meanwhile, we conduct automatic evaluation and human inspection, which indicate the proposed method possesses good performance of stealthiness without bringing grammatical issues and altering the meaning of sentences.
Deep Reinforcement Learning-Based Battery Conditioning Hierarchical V2G Coordination for Multi-Stakeholder Benefits
Aug 01, 2023


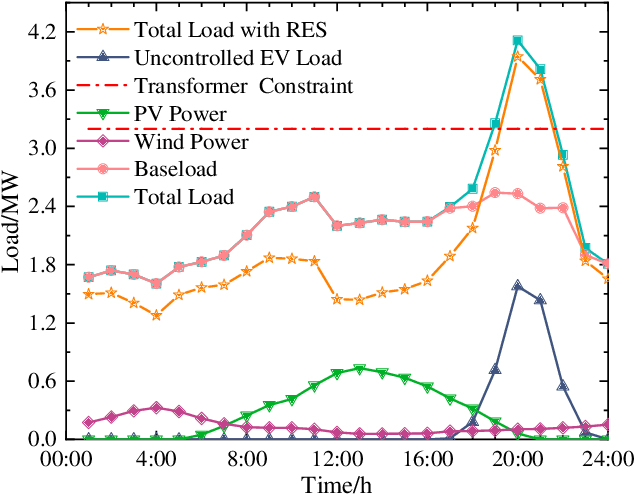
With the growing prevalence of electric vehicles (EVs) and advancements in EV electronics, vehicle-to-grid (V2G) techniques and large-scale scheduling strategies have emerged to promote renewable energy utilization and power grid stability. This study proposes a multi-stakeholder hierarchical V2G coordination based on deep reinforcement learning (DRL) and the Proof of Stake algorithm. Furthermore, the multi-stakeholders include the power grid, EV aggregators (EVAs), and users, and the proposed strategy can achieve multi-stakeholder benefits. On the grid side, load fluctuations and renewable energy consumption are considered, while on the EVA side, energy constraints and charging costs are considered. The three critical battery conditioning parameters of battery SOX are considered on the user side, including state of charge, state of power, and state of health. Compared with four typical baselines, the multi-stakeholder hierarchical coordination strategy can enhance renewable energy consumption, mitigate load fluctuations, meet the energy demands of EVA, and reduce charging costs and battery degradation under realistic operating conditions.
Automatic Recognition and Classification of Future Work Sentences from Academic Articles in a Specific Domain
Dec 28, 2022Future work sentences (FWS) are the particular sentences in academic papers that contain the author's description of their proposed follow-up research direction. This paper presents methods to automatically extract FWS from academic papers and classify them according to the different future directions embodied in the paper's content. FWS recognition methods will enable subsequent researchers to locate future work sentences more accurately and quickly and reduce the time and cost of acquiring the corpus. The current work on automatic identification of future work sentences is relatively small, and the existing research cannot accurately identify FWS from academic papers, and thus cannot conduct data mining on a large scale. Furthermore, there are many aspects to the content of future work, and the subdivision of the content is conducive to the analysis of specific development directions. In this paper, Nature Language Processing (NLP) is used as a case study, and FWS are extracted from academic papers and classified into different types. We manually build an annotated corpus with six different types of FWS. Then, automatic recognition and classification of FWS are implemented using machine learning models, and the performance of these models is compared based on the evaluation metrics. The results show that the Bernoulli Bayesian model has the best performance in the automatic recognition task, with the Macro F1 reaching 90.73%, and the SCIBERT model has the best performance in the automatic classification task, with the weighted average F1 reaching 72.63%. Finally, we extract keywords from FWS and gain a deep understanding of the key content described in FWS, and we also demonstrate that content determination in FWS will be reflected in the subsequent research work by measuring the similarity between future work sentences and the abstracts.