 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Enhanced Hierarchical Planning Framework for Multi-Robot Autonomous Exploration
Oct 25, 2024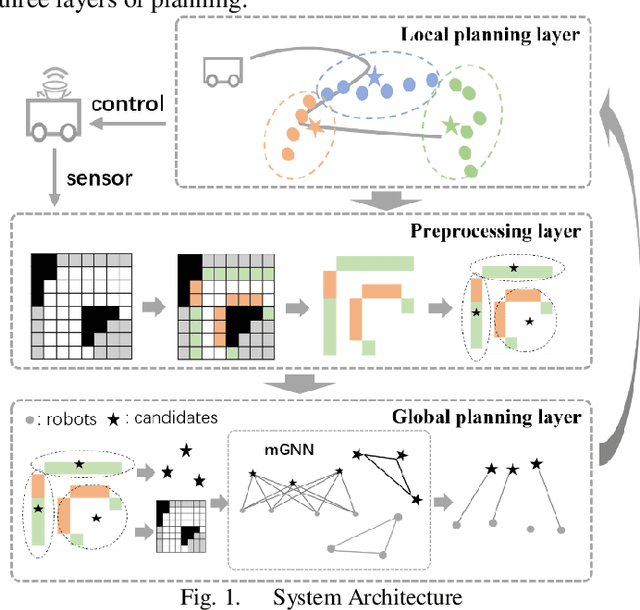
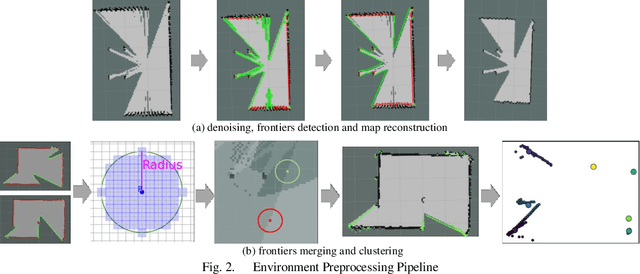
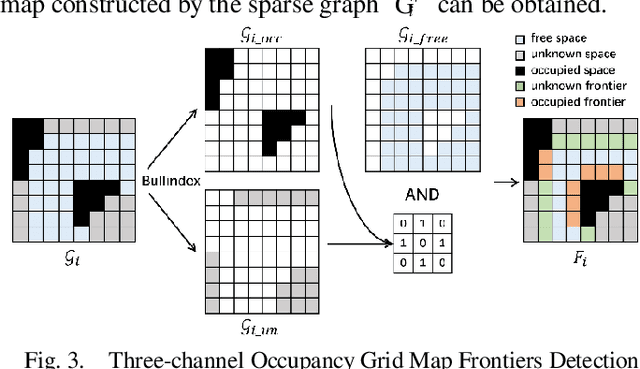
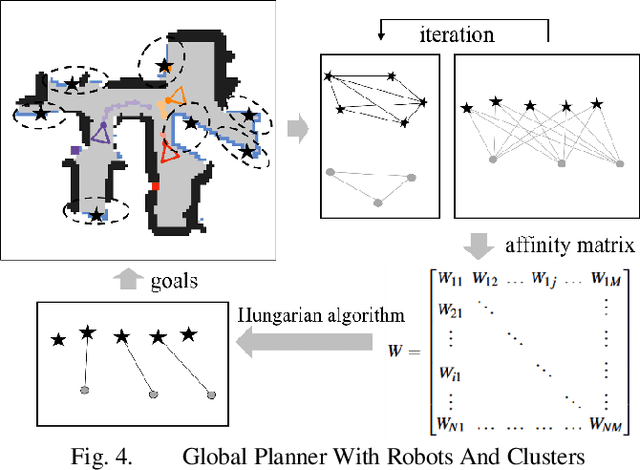
The autonomous exploration of environments by multi-robot systems is a critical task with broad applications in rescue missions, exploration endeavors, and beyond. Current approaches often rely on either greedy frontier selection or end-to-end deep reinforcement learning (DRL) methods, yet these methods are frequently hampered by limitations such as short-sightedness, overlooking long-term implications, and convergence difficulties stemming from the intricate high-dimensional learning space. To address these challenges, this paper introduces an innovative integration strategy that combines the low-dimensional action space efficiency of frontier-based methods with the far-sightedness and optimality of DRL-based approaches. We propose a three-tiered planning framework that first identifies frontiers in free space, creating a sparse map representation that lightens data transmission burdens and reduces the DRL action space's dimensionality. Subsequently, we develop a multi-graph neural network (mGNN) that incorporates states of potential targets and robots, leveraging policy-based reinforcement learning to compute affinities, thereby superseding traditional heuristic utility values. Lastly, we implement local routing planning through subsequence search, which avoids exhaustive sequence traversal. Extensive validation across diverse scenarios and comprehensive simulation results demonstrate the effectiveness of our proposed method. Compared to baseline approaches, our framework achieves environmental exploration with fewer time steps and a notable reduction of over 30% in data transmission, showcasing its superiority in terms of efficiency and performance.
Punctuation Matters! Stealthy Backdoor Attack for Language Models
Dec 26, 2023Recent studies have pointed out that natural language processing (NLP) models are vulnerable to backdoor attacks. A backdoored model produces normal outputs on the clean samples while performing improperly on the texts with triggers that the adversary injects. However, previous studies on textual backdoor attack pay little attention to stealthiness. Moreover, some attack methods even cause grammatical issues or change the semantic meaning of the original texts. Therefore, they can easily be detected by humans or defense systems. In this paper, we propose a novel stealthy backdoor attack method against textual models, which is called \textbf{PuncAttack}. It leverages combinations of punctuation marks as the trigger and chooses proper locations strategically to replace them. Through extensive experiments, we demonstrate that the proposed method can effectively compromise multiple models in various tasks. Meanwhile, we conduct automatic evaluation and human inspection, which indicate the proposed method possesses good performance of stealthiness without bringing grammatical issues and altering the meaning of sentences.
A Survey on Backdoor Attack and Defense in Natural Language Processing
Nov 22, 2022



Deep learning is becoming increasingly popular in real-life applications, especially in natural language processing (NLP). Users often choose training outsourcing or adopt third-party data and models due to data and computation resources being limited. In such a situation, training data and models are exposed to the public. As a result, attackers can manipulate the training process to inject some triggers into the model, which is called backdoor attack. Backdoor attack is quite stealthy and difficult to be detected because it has little inferior influence on the model's performance for the clean samples. To get a precise grasp and understanding of this problem, in this paper, we conduct a comprehensive review of backdoor attacks and defenses in the field of NLP. Besides, we summarize benchmark datasets and point out the open issues to design credible systems to defend against backdoor attacks.