 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Radar Constant False Alarm Rate Detection Algorithm Based on VAMP Deep Unfolding
Apr 14, 2025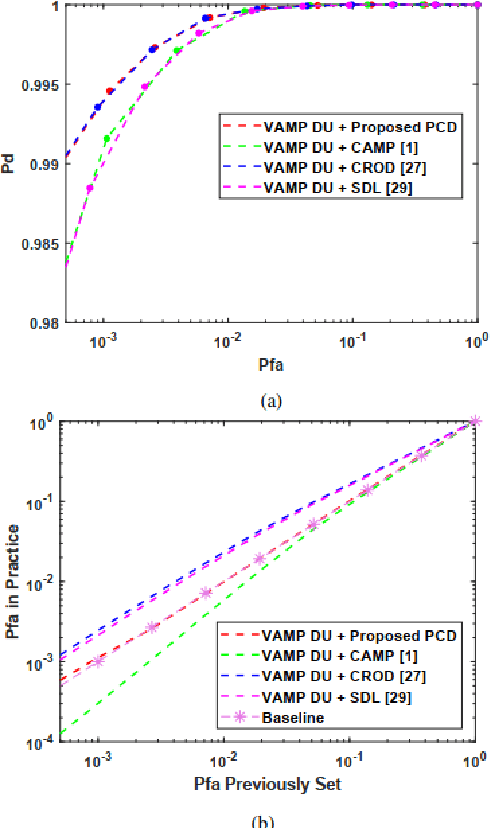

The combination of deep unfolding with vector approximate message passing (VAMP) algorithm, results in faster convergence and higher sparse recovery accuracy than traditional compressive sensing approaches. However, deep unfolding alters the parameters in traditional VAMP algorithm, resulting in the unattainable distribution parameter of the recovery error of non-sparse noisy estimation via traditional VAMP, which hinders the utilization of VAMP deep unfolding in constant false alarm rate (CFAR) detection in sub-Nyquist radar system. Based on VAMP deep unfolding, we provide a parameter convergence detector (PCD) to estimate the recovery error distribution parameter and implement CFAR detection. Compared to the state-of-the-art approaches, both the sparse solution and non-sparse noisy estimation are utilized to estimate the distribution parameter and implement CFAR detection in PCD, which leverages both the VAMP distribution property and the improved sparse recovery accuracy provided by deep unfolding. Simulation results indicate that PCD offers improved false alarm rate control performance and higher target detection rate.
PhenoProfiler: Advancing Phenotypic Learning for Image-based Drug Discovery
Feb 26, 2025In the field of image-based drug discovery, capturing the phenotypic response of cells to various drug treatments and perturbations is a crucial step. However, existing methods require computationally extensive and complex multi-step procedures, which can introduce inefficiencies, limit generalizability, and increase potential errors. To address these challenges, we present PhenoProfiler, an innovative model designed to efficiently and effectively extract morphological representations, enabling the elucidation of phenotypic changes induced by treatments. PhenoProfiler is designed as an end-to-end tool that processes whole-slide multi-channel images directly into low-dimensional quantitative representations, eliminating the extensive computational steps required by existing methods. It also includes a multi-objective learning module to enhance robustness, accuracy, and generalization in morphological representation learning. PhenoProfiler is rigorously evaluated on large-scale publicly available datasets, including over 230,000 whole-slide multi-channel images in end-to-end scenarios and more than 8.42 million single-cell images in non-end-to-end settings. Across these benchmarks, PhenoProfiler consistently outperforms state-of-the-art methods by up to 20%, demonstrating substantial improvements in both accuracy and robustness. Furthermore, PhenoProfiler uses a tailored phenotype correction strategy to emphasize relative phenotypic changes under treatments, facilitating the detection of biologically meaningful signals. UMAP visualizations of treatment profiles demonstrate PhenoProfiler ability to effectively cluster treatments with similar biological annotations, thereby enhancing interpretability. These findings establish PhenoProfiler as a scalable, generalizable, and robust tool for phenotypic learning.
Lightweight Change Detection in Heterogeneous Remote Sensing Images with Online All-Integer Pruning Training
May 03, 2024Detection of changes in heterogeneous remote sensing images is vital, especially in response to emergencies like earthquakes and floods. Current homogenous transformation-based change detection (CD) methods often suffer from high computation and memory costs, which are not friendly to edge-computation devices like onboard CD devices at satellites. To address this issue, this paper proposes a new lightweight CD method for heterogeneous remote sensing images that employs the online all-integer pruning (OAIP) training strategy to efficiently fine-tune the CD network using the current test data. The proposed CD network consists of two visual geometry group (VGG) subnetworks as the backbone architecture. In the OAIP-based training process, all the weights, gradients, and intermediate data are quantized to integers to speed up training and reduce memory usage, where the per-layer block exponentiation scaling scheme is utilized to reduce the computation errors of network parameters caused by quantization. Second, an adaptive filter-level pruning method based on the L1-norm criterion is employed to further lighten the fine-tuning process of the CD network. Experimental results show that the proposed OAIP-based method attains similar detection performance (but with significantly reduced computation complexity and memory usage) in comparison with state-of-the-art CD methods.
Few-shot Object Localization
Mar 24, 2024Existing object localization methods are tailored to locate a specific class of objects, relying on abundant labeled data for model optimization. However, in numerous real-world scenarios, acquiring large labeled data can be arduous, significantly constraining the broader application of localization models. To bridge this research gap, this paper proposes the novel task of Few-Shot Object Localization (FSOL), which seeks to achieve precise localization with limited samples available. This task achieves generalized object localization by leveraging a small number of labeled support samples to query the positional information of objects within corresponding images. To advance this research field, we propose an innovative high-performance baseline model. Our model integrates a dual-path feature augmentation module to enhance shape association and gradient differences between supports and query images, alongside a self query module designed to explore the association between feature maps and query images. Experimental results demonstrate a significant performance improvement of our approach in the FSOL task, establishing an efficient benchmark for further research. All codes and data are available at https://github.com/Ryh1218/FSOL.
BjTT: A Large-scale Multimodal Dataset for Traffic Prediction
Mar 14, 2024Traffic prediction is one of the most significant foundations in Intelligent Transportation Systems (ITS). Traditional traffic prediction methods rely only on historical traffic data to predict traffic trends and face two main challenges. 1) insensitivity to unusual events. 2) limited performance in long-term prediction. In this work, we explore how generative models combined with text describing the traffic system can be applied for traffic generation, and name the task Text-to-Traffic Generation (TTG). The key challenge of the TTG task is how to associate text with the spatial structure of the road network and traffic data for generating traffic situations. To this end, we propose ChatTraffic, the first diffusion model for text-to-traffic generation. To guarantee the consistency between synthetic and real data, we augment a diffusion model with the Graph Convolutional Network (GCN) to extract spatial correlations of traffic data. In addition, we construct a large dataset containing text-traffic pairs for the TTG task. We benchmarked our model qualitatively and quantitatively on the released dataset. The experimental results indicate that ChatTraffic can generate realistic traffic situations from the text. Our code and dataset are available at https://github.com/ChyaZhang/ChatTraffic.
ChatTraffic: Text-to-Traffic Generation via Diffusion Model
Nov 29, 2023Traffic prediction is one of the most significant foundations in Intelligent Transportation Systems (ITS). Traditional traffic prediction methods rely only on historical traffic data to predict traffic trends and face two main challenges. 1) insensitivity to unusual events. 2) poor performance in long-term prediction. In this work, we explore how generative models combined with text describing the traffic system can be applied for traffic generation and name the task Text-to-Traffic Generation (TTG). The key challenge of the TTG task is how to associate text with the spatial structure of the road network and traffic data for generating traffic situations. To this end, we propose ChatTraffic, the first diffusion model for text-to-traffic generation. To guarantee the consistency between synthetic and real data, we augment a diffusion model with the Graph Convolutional Network (GCN) to extract spatial correlations of traffic data. In addition, we construct a large dataset containing text-traffic pairs for the TTG task. We benchmarked our model qualitatively and quantitatively on the released dataset. The experimental results indicate that ChatTraffic can generate realistic traffic situations from the text. Our code and dataset are available at https://github.com/ChyaZhang/ChatTraffic.
LiDAR-Inertial 3D SLAM with Plane Constraint for Multi-story Building
Feb 17, 2022
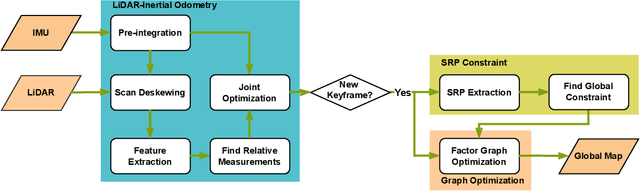
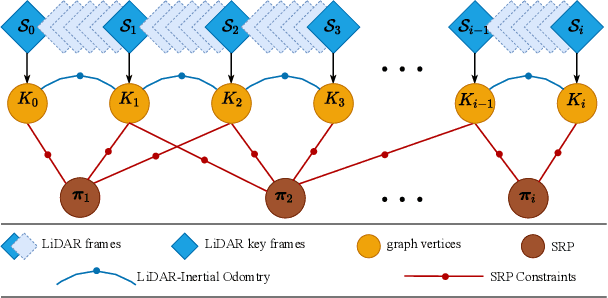

The ubiquitous planes and structural consistency are the most apparent features of indoor multi-story Buildings compared with outdoor environments. In this paper, we propose a tightly coupled LiDAR-Inertial 3D SLAM framework with plane features for the multi-story building. The framework we proposed is mainly composed of three parts: tightly coupled LiDAR-Inertial odometry, extraction of representative planes of the structure, and factor graph optimization. By building a local map and inertial measurement unit (IMU) pre-integration, we get LiDAR scan-to-local-map matching and IMU measurements, respectively. Minimize the joint cost function to obtain the LiDAR-Inertial odometry information. Once a new keyframe is added to the graph, all the planes of this keyframe that can represent structural features are extracted to find the constraint between different poses and stories. A keyframe-based factor graph is conducted with the constraint of planes, and LiDAR-Inertial odometry for keyframe poses refinement. The experimental results show that our algorithm has outstanding performance in accuracy compared with the state-of-the-art algorithms.