 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREE-TTT: Highly Adaptive Radar Echo Extrapolation Based on Test-Time Training
Jan 04, 2026Precipitation nowcasting is critically important for meteorological forecasting. Deep learning-based Radar Echo Extrapolation (REE) has become a predominant nowcasting approach, yet it suffers from poor generalization due to its reliance on high-quality local training data and static model parameters, limiting its applicability across diverse regions and extreme events. To overcome this, we propose REE-TTT, a novel model that incorporates an adaptive Test-Time Training (TTT) mechanism. The core of our model lies in the newly designed Spatio-temporal Test-Time Training (ST-TTT) block, which replaces the standard linear projections in TTT layers with task-specific attention mechanisms, enabling robust adaptation to non-stationary meteorological distributions and thereby significantly enhancing the feature representation of precipitation. Experiments under cross-regional extreme precipitation scenarios demonstrate that REE-TTT substantially outperforms state-of-the-art baseline models in prediction accuracy and generalization, exhibiting remarkable adaptability to data distribution shifts.
Text-guided Zero-Shot Object Localization
Nov 18, 2024



Object localization is a hot issue in computer vision area, which aims to identify and determine the precise location of specific objects from image or video. Most existing object localization methods heavily rely on extensive labeled data, which are costly to annotate and constrain their applicability. Therefore, we propose a new Zero-Shot Object Localization (ZSOL) framework for addressing the aforementioned challenges. In the proposed framework, we introduce the Contrastive Language Image Pre-training (CLIP) module which could integrate visual and linguistic information effectively. Furthermore, we design a Text Self-Similarity Matching (TSSM) module, which could improve the localization accuracy by enhancing the representation of text features extracted by CLIP module. Hence, the proposed framework can be guided by prompt words to identify and locate specific objects in an image in the absence of labeled samples. The results of extensive experiments demonstrate that the proposed method could improve the localization performance significantly and establishes an effective benchmark for further research.
BjTT: A Large-scale Multimodal Dataset for Traffic Prediction
Mar 14, 2024Traffic prediction is one of the most significant foundations in Intelligent Transportation Systems (ITS). Traditional traffic prediction methods rely only on historical traffic data to predict traffic trends and face two main challenges. 1) insensitivity to unusual events. 2) limited performance in long-term prediction. In this work, we explore how generative models combined with text describing the traffic system can be applied for traffic generation, and name the task Text-to-Traffic Generation (TTG). The key challenge of the TTG task is how to associate text with the spatial structure of the road network and traffic data for generating traffic situations. To this end, we propose ChatTraffic, the first diffusion model for text-to-traffic generation. To guarantee the consistency between synthetic and real data, we augment a diffusion model with the Graph Convolutional Network (GCN) to extract spatial correlations of traffic data. In addition, we construct a large dataset containing text-traffic pairs for the TTG task. We benchmarked our model qualitatively and quantitatively on the released dataset. The experimental results indicate that ChatTraffic can generate realistic traffic situations from the text. Our code and dataset are available at https://github.com/ChyaZhang/ChatTraffic.
ChatTraffic: Text-to-Traffic Generation via Diffusion Model
Nov 29, 2023Traffic prediction is one of the most significant foundations in Intelligent Transportation Systems (ITS). Traditional traffic prediction methods rely only on historical traffic data to predict traffic trends and face two main challenges. 1) insensitivity to unusual events. 2) poor performance in long-term prediction. In this work, we explore how generative models combined with text describing the traffic system can be applied for traffic generation and name the task Text-to-Traffic Generation (TTG). The key challenge of the TTG task is how to associate text with the spatial structure of the road network and traffic data for generating traffic situations. To this end, we propose ChatTraffic, the first diffusion model for text-to-traffic generation. To guarantee the consistency between synthetic and real data, we augment a diffusion model with the Graph Convolutional Network (GCN) to extract spatial correlations of traffic data. In addition, we construct a large dataset containing text-traffic pairs for the TTG task. We benchmarked our model qualitatively and quantitatively on the released dataset. The experimental results indicate that ChatTraffic can generate realistic traffic situations from the text. Our code and dataset are available at https://github.com/ChyaZhang/ChatTraffic.
Block-Diagonal Sparse Representation by Learning a Linear Combination Dictionary for Recognition
Nov 28, 2016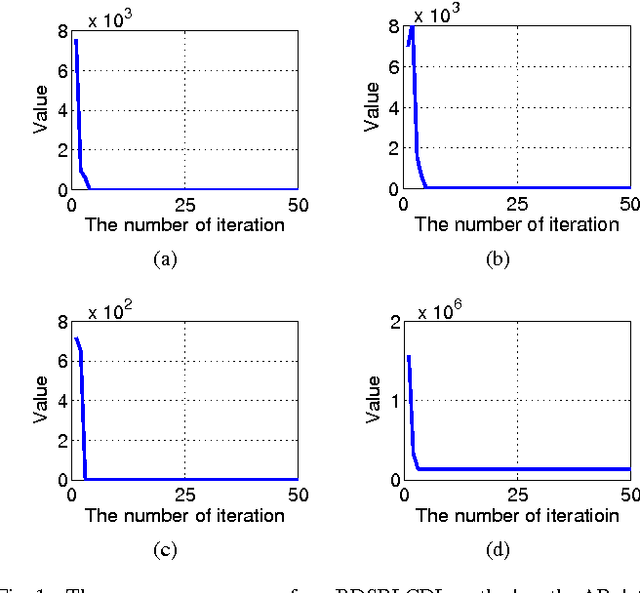

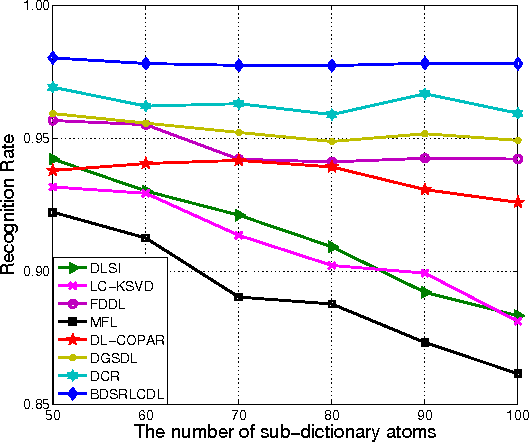

In a sparse representation based recognition scheme, it is critical to learn a desired dictionary, aiming both good representational power and discriminative performance. In this paper, we propose a new dictionary learning model for recognition applications, in which three strategies are adopted to achieve these two objectives simultaneously. First, a block-diagonal constraint is introduced into the model to eliminate the correlation between classes and enhance the discriminative performance. Second, a low-rank term is adopted to model the coherence within classes for refining the sparse representation of each class. Finally, instead of using the conventional over-complete dictionary, a specific dictionary constructed from the linear combination of the training samples is proposed to enhance the representational power of the dictionary and to improve the robustness of the sparse representation model. The proposed method is tested on several public datasets. The experimental results show the method outperforms most state-of-the-art methods.
Tensor Sparse and Low-Rank based Submodule Clustering Method for Multi-way Data
Sep 28, 2016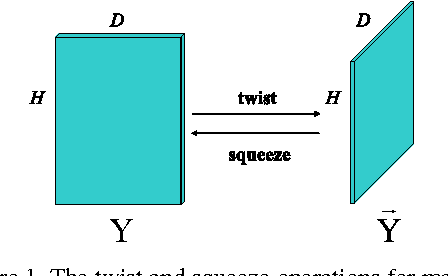

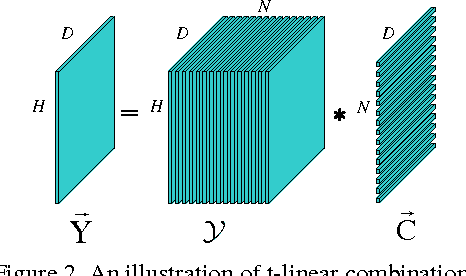
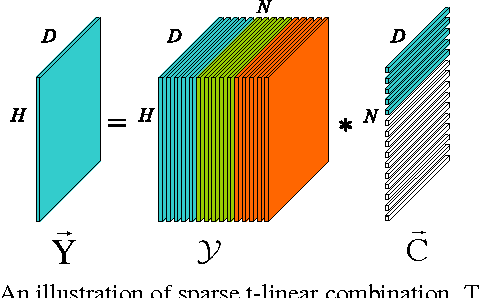
A new submodule clustering method via sparse and low-rank representation for multi-way data is proposed in this paper. Instead of reshaping multi-way data into vectors, this method maintains their natural orders to preserve data intrinsic structures, e.g., image data kept as matrices. To implement clustering, the multi-way data, viewed as tensors, are represented by the proposed tensor sparse and low-rank model to obtain its submodule representation, called a free module, which is finally used for spectral clustering. The proposed method extends the conventional subspace clustering method based on sparse and low-rank representation to multi-way data submodule clustering by combining t-product operator. The new method is tested on several public datasets, including synthetical data, video sequences and toy images. The experiments show that the new method outperforms the state-of-the-art methods, such as Sparse Subspace Clustering (SSC), Low-Rank Representation (LRR), Ordered Subspace Clustering (OSC), Robust Latent Low Rank Representation (RobustLatLRR) and Sparse Submodule Clustering method (SSmC).