 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompEvent: Complex-valued Event-RGB Fusion for Low-light Video Enhancement and Deblurring
Nov 18, 2025Low-light video deblurring poses significant challenges in applications like nighttime surveillance and autonomous driving due to dim lighting and long exposures. While event cameras offer potential solutions with superior low-light sensitivity and high temporal resolution, existing fusion methods typically employ staged strategies, limiting their effectiveness against combined low-light and motion blur degradations. To overcome this, we propose CompEvent, a complex neural network framework enabling holistic full-process fusion of event data and RGB frames for enhanced joint restoration. CompEvent features two core components: 1) Complex Temporal Alignment GRU, which utilizes complex-valued convolutions and processes video and event streams iteratively via GRU to achieve temporal alignment and continuous fusion; and 2) Complex Space-Frequency Learning module, which performs unified complex-valued signal processing in both spatial and frequency domains, facilitating deep fusion through spatial structures and system-level characteristics. By leveraging the holistic representation capability of complex-valued neural networks, CompEvent achieves full-process spatiotemporal fusion, maximizes complementary learning between modalities, and significantly strengthens low-light video deblurring capability. Extensive experiments demonstrate that CompEvent outperforms SOTA methods in addressing this challenging task. The code is available at https://github.com/YuXie1/CompEvent.
Visual and Semantic Prompt Collaboration for Generalized Zero-Shot Learning
Mar 29, 2025Generalized zero-shot learning aims to recognize both seen and unseen classes with the help of semantic information that is shared among different classes. It inevitably requires consistent visual-semantic alignment. Existing approaches fine-tune the visual backbone by seen-class data to obtain semantic-related visual features, which may cause overfitting on seen classes with a limited number of training images. This paper proposes a novel visual and semantic prompt collaboration framework, which utilizes prompt tuning techniques for efficient feature adaptation. Specifically, we design a visual prompt to integrate the visual information for discriminative feature learning and a semantic prompt to integrate the semantic formation for visualsemantic alignment. To achieve effective prompt information integration, we further design a weak prompt fusion mechanism for the shallow layers and a strong prompt fusion mechanism for the deep layers in the network. Through the collaboration of visual and semantic prompts, we can obtain discriminative semantic-related features for generalized zero-shot image recognition. Extensive experiments demonstrate that our framework consistently achieves favorable performance in both conventional zero-shot learning and generalized zero-shot learning benchmarks compared to other state-of-the-art methods.
Col-OLHTR: A Novel Framework for Multimodal Online Handwritten Text Recognition
Feb 10, 2025



Online Handwritten Text Recognition (OLHTR) has gained considerable attention for its diverse range of applications. Current approaches usually treat OLHTR as a sequence recognition task, employing either a single trajectory or image encoder, or multi-stream encoders, combined with a CTC or attention-based recognition decoder. However, these approaches face several drawbacks: 1) single encoders typically focus on either local trajectories or visual regions, lacking the ability to dynamically capture relevant global features in challenging cases; 2) multi-stream encoders, while more comprehensive, suffer from complex structures and increased inference costs. To tackle this, we propose a Collaborative learning-based OLHTR framework, called Col-OLHTR, that learns multimodal features during training while maintaining a single-stream inference process. Col-OLHTR consists of a trajectory encoder, a Point-to-Spatial Alignment (P2SA) module, and an attention-based decoder. The P2SA module is designed to learn image-level spatial features through trajectory-encoded features and 2D rotary position embeddings. During training, an additional image-stream encoder-decoder is collaboratively trained to provide supervision for P2SA features. At inference, the extra streams are discarded, and only the P2SA module is used and merged before the decoder, simplifying the process while preserving high performance. Extensive experimental results on several OLHTR benchmarks demonstrate the state-of-the-art (SOTA) performance, proving the effectiveness and robustness of our design.
AdvAnchor: Enhancing Diffusion Model Unlearning with Adversarial Anchors
Dec 28, 2024Security concerns surrounding text-to-image diffusion models have driven researchers to unlearn inappropriate concepts through fine-tuning. Recent fine-tuning methods typically align the prediction distributions of unsafe prompts with those of predefined text anchors. However, these techniques exhibit a considerable performance trade-off between eliminating undesirable concepts and preserving other concepts. In this paper, we systematically analyze the impact of diverse text anchors on unlearning performance. Guided by this analysis, we propose AdvAnchor, a novel approach that generates adversarial anchors to alleviate the trade-off issue. These adversarial anchors are crafted to closely resemble the embeddings of undesirable concepts to maintain overall model performance, while selectively excluding defining attributes of these concepts for effective erasure. Extensive experiments demonstrate that AdvAnchor outperforms state-of-the-art methods. Our code is publicly available at https://anonymous.4open.science/r/AdvAnchor.
Adapter-Enhanced Semantic Prompting for Continual Learning
Dec 15, 2024



Continual learning (CL) enables models to adapt to evolving data streams. A major challenge of CL is catastrophic forgetting, where new knowledge will overwrite previously acquired knowledge. Traditional methods usually retain the past data for replay or add additional branches in the model to learn new knowledge, which has high memory requirements. In this paper, we propose a novel lightweight CL framework, Adapter-Enhanced Semantic Prompting (AESP), which integrates prompt tuning and adapter techniques. Specifically, we design semantic-guided prompts to enhance the generalization ability of visual features and utilize adapters to efficiently fuse the semantic information, aiming to learn more adaptive features for the continual learning task. Furthermore, to choose the right task prompt for feature adaptation, we have developed a novel matching mechanism for prompt selection. Extensive experiments on three CL datasets demonstrate that our approach achieves favorable performance across multiple metrics, showing its potential for advancing CL.
HC-LLM: Historical-Constrained Large Language Models for Radiology Report Generation
Dec 15, 2024



Radiology report generation (RRG) models typically focus on individual exams, often overlooking the integration of historical visual or textual data, which is crucial for patient follow-ups. Traditional methods usually struggle with long sequence dependencies when incorporating historical information, but large language models (LLMs) excel at in-context learning, making them well-suited for analyzing longitudinal medical data. In light of this, we propose a novel Historical-Constrained Large Language Models (HC-LLM) framework for RRG, empowering LLMs with longitudinal report generation capabilities by constraining the consistency and differences between longitudinal images and their corresponding reports. Specifically, our approach extracts both time-shared and time-specific features from longitudinal chest X-rays and diagnostic reports to capture disease progression. Then, we ensure consistent representation by applying intra-modality similarity constraints and aligning various features across modalities with multimodal contrastive and structural constraints. These combined constraints effectively guide the LLMs in generating diagnostic reports that accurately reflect the progression of the disease, achieving state-of-the-art results on the Longitudinal-MIMIC dataset. Notably, our approach performs well even without historical data during testing and can be easily adapted to other multimodal large models, enhancing its versatility.
RFL: Simplifying Chemical Structure Recognition with Ring-Free Language
Dec 10, 2024



The primary objective of Optical Chemical Structure Recognition is to identify chemical structure images into corresponding markup sequences. However, the complex two-dimensional structures of molecules, particularly those with rings and multiple branches, present significant challenges for current end-to-end methods to learn one-dimensional markup directly. To overcome this limitation, we propose a novel Ring-Free Language (RFL), which utilizes a divide-and-conquer strategy to describe chemical structures in a hierarchical form. RFL allows complex molecular structures to be decomposed into multiple parts, ensuring both uniqueness and conciseness while enhancing readability. This approach significantly reduces the learning difficulty for recognition models. Leveraging RFL, we propose a universal Molecular Skeleton Decoder (MSD), which comprises a skeleton generation module that progressively predicts the molecular skeleton and individual rings, along with a branch classification module for predicting branch information. Experimental results demonstrate that the proposed RFL and MSD can be applied to various mainstream methods, achieving superior performance compared to state-of-the-art approaches in both printed and handwritten scenarios. The code is available at https://github.com/JingMog/RFL-MSD.
WTDUN: Wavelet Tree-Structured Sampling and Deep Unfolding Network for Image Compressed Sensing
Nov 25, 2024



Deep unfolding networks have gained increasing attention in the field of compressed sensing (CS) owing to their theoretical interpretability and superior reconstruction performance. However, most existing deep unfolding methods often face the following issues: 1) they learn directly from single-channel images, leading to a simple feature representation that does not fully capture complex features; and 2) they treat various image components uniformly, ignoring the characteristics of different components. To address these issues, we propose a novel wavelet-domain deep unfolding framework named WTDUN, which operates directly on the multi-scale wavelet subbands. Our method utilizes the intrinsic sparsity and multi-scale structure of wavelet coefficients to achieve a tree-structured sampling and reconstruction, effectively capturing and highlighting the most important features within images. Specifically, the design of tree-structured reconstruction aims to capture the inter-dependencies among the multi-scale subbands, enabling the identification of both fine and coarse features, which can lead to a marked improvement in reconstruction quality. Furthermore, a wavelet domain adaptive sampling method is proposed to greatly improve the sampling capability, which is realized by assigning measurements to each wavelet subband based on its importance. Unlike pure deep learning methods that treat all components uniformly, our method introduces a targeted focus on important subbands, considering their energy and sparsity. This targeted strategy lets us capture key information more efficiently while discarding less important information, resulting in a more effective and detailed reconstruction. Extensive experimental results on various datasets validate the superior performance of our proposed method.
Text-guided Zero-Shot Object Localization
Nov 18, 2024



Object localization is a hot issue in computer vision area, which aims to identify and determine the precise location of specific objects from image or video. Most existing object localization methods heavily rely on extensive labeled data, which are costly to annotate and constrain their applicability. Therefore, we propose a new Zero-Shot Object Localization (ZSOL) framework for addressing the aforementioned challenges. In the proposed framework, we introduce the Contrastive Language Image Pre-training (CLIP) module which could integrate visual and linguistic information effectively. Furthermore, we design a Text Self-Similarity Matching (TSSM) module, which could improve the localization accuracy by enhancing the representation of text features extracted by CLIP module. Hence, the proposed framework can be guided by prompt words to identify and locate specific objects in an image in the absence of labeled samples. The results of extensive experiments demonstrate that the proposed method could improve the localization performance significantly and establishes an effective benchmark for further research.
Dual-Frequency Filtering Self-aware Graph Neural Networks for Homophilic and Heterophilic Graphs
Nov 18, 2024
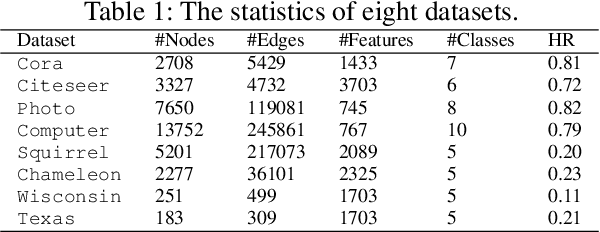
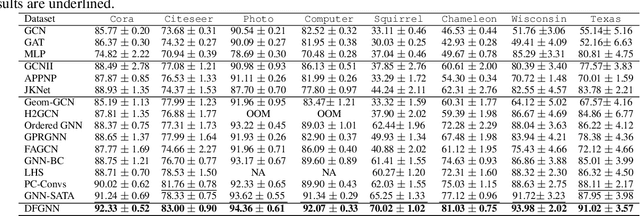

Graph Neural Networks (GNNs) have excelled in handling graph-structured data, attracting significant research interest. However, two primary challenges have emerged: interference between topology and attributes distorting node representations, and the low-pass filtering nature of most GNNs leading to the oversight of valuable high-frequency information in graph signals. These issues are particularly pronounced in heterophilic graphs. To address these challenges, we propose Dual-Frequency Filtering Self-aware Graph Neural Networks (DFGNN). DFGNN integrates low-pass and high-pass filters to extract smooth and detailed topological features, using frequency-specific constraints to minimize noise and redundancy in the respective frequency bands. The model dynamically adjusts filtering ratios to accommodate both homophilic and heterophilic graphs. Furthermore, DFGNN mitigates interference by aligning topological and attribute representations through dynamic correspondences between their respective frequency bands, enhancing overall model performance and expressiveness. Extensive experiments conducted on benchmark datasets demonstrate that DFGNN outperforms state-of-the-art methods in classification performance, highlighting its effectiveness in handling both homophilic and heterophilic graphs.