 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoKAN: Interpretable Decomposition for Forecasting Cryptocurrency Market Dynamics
Dec 23, 2025Accurate and interpretable forecasting of multivariate time series is crucial for understanding the complex dynamics of cryptocurrency markets in digital asset systems. Advanced deep learning methodologies, particularly Transformer-based and MLP-based architectures, have achieved competitive predictive performance in cryptocurrency forecasting tasks. However, cryptocurrency data is inherently composed of long-term socio-economic trends and local high-frequency speculative oscillations. Existing deep learning-based 'black-box' models fail to effectively decouple these composite dynamics or provide the interpretability needed for trustworthy financial decision-making. To overcome these limitations, we propose DecoKAN, an interpretable forecasting framework that integrates multi-level Discrete Wavelet Transform (DWT) for decoupling and hierarchical signal decomposition with Kolmogorov-Arnold Network (KAN) mixers for transparent and interpretable nonlinear modeling. The DWT component decomposes complex cryptocurrency time series into distinct frequency components, enabling frequency-specific analysis, while KAN mixers provide intrinsically interpretable spline-based mappings within each decomposed subseries. Furthermore, interpretability is enhanced through a symbolic analysis pipeline involving sparsification, pruning, and symbolization, which produces concise analytical expressions offering symbolic representations of the learned patterns. Extensive experiments demonstrate that DecoKAN achieves the lowest average Mean Squared Error on all tested real-world cryptocurrency datasets (BTC, ETH, XMR), consistently outperforming a comprehensive suite of competitive state-of-the-art baselines. These results validate DecoKAN's potential to bridge the gap between predictive accuracy and model transparency, advancing trustworthy decision support within complex cryptocurrency markets.
Contrastive Learning Meets Pseudo-label-assisted Mixup Augmentation: A Comprehensive Graph Representation Framework from Local to Global
Jan 30, 2025



Graph Neural Networks (GNNs) have demonstrated remarkable effectiveness in various graph representation learning tasks. However, most existing GNNs focus primarily on capturing local information through explicit graph convolution, often neglecting global message-passing. This limitation hinders the establishment of a collaborative interaction between global and local information, which is crucial for comprehensively understanding graph data. To address these challenges, we propose a novel framework called Comprehensive Graph Representation Learning (ComGRL). ComGRL integrates local information into global information to derive powerful representations. It achieves this by implicitly smoothing local information through flexible graph contrastive learning, ensuring reliable representations for subsequent global exploration. Then ComGRL transfers the locally derived representations to a multi-head self-attention module, enhancing their discriminative ability by uncovering diverse and rich global correlations. To further optimize local information dynamically under the self-supervision of pseudo-labels, ComGRL employs a triple sampling strategy to construct mixed node pairs and applies reliable Mixup augmentation across attributes and structure for local contrastive learning. This approach broadens the receptive field and facilitates coordination between local and global representation learning, enabling them to reinforce each other. Experimental results across six widely used graph datasets demonstrate that ComGRL achieves excellent performance in node classification tasks. The code could be available at https://github.com/JinluWang1002/ComGRL.
DDUNet: Dual Dynamic U-Net for Highly-Efficient Cloud Segmentation
Jan 26, 2025



Cloud segmentation amounts to separating cloud pixels from non-cloud pixels in an image. Current deep learning methods for cloud segmentation suffer from three issues. (a) Constrain on their receptive field due to the fixed size of the convolution kernel. (b) Lack of robustness towards different scenarios. (c) Requirement of a large number of parameters and limitations for real-time implementation. To address these issues, we propose a Dual Dynamic U-Net (DDUNet) for supervised cloud segmentation. The DDUNet adheres to a U-Net architecture and integrates two crucial modules: the dynamic multi-scale convolution (DMSC), improving merging features under different reception fields, and the dynamic weights and bias generator (DWBG) in classification layers to enhance generalization ability. More importantly, owing to the use of depth-wise convolution, the DDUNet is a lightweight network that can achieve 95.3% accuracy on the SWINySEG dataset with only 0.33M parameters, and achieve superior performance over three different configurations of the SWINySEg dataset in both accuracy and efficiency.
CP2M: Clustered-Patch-Mixed Mosaic Augmentation for Aerial Image Segmentation
Jan 26, 2025



Remote sensing image segmentation is pivotal for earth observation, underpinning applications such as environmental monitoring and urban planning. Due to the limited annotation data available in remote sensing images, numerous studies have focused on data augmentation as a means to alleviate overfitting in deep learning networks. However, some existing data augmentation strategies rely on simple transformations that may not sufficiently enhance data diversity or model generalization capabilities. This paper proposes a novel augmentation strategy, Clustered-Patch-Mixed Mosaic (CP2M), designed to address these limitations. CP2M integrates a Mosaic augmentation phase with a clustered patch mix phase. The former stage constructs a new sample from four random samples, while the latter phase uses the connected component labeling algorithm to ensure the augmented data maintains spatial coherence and avoids introducing irrelevant semantics when pasting random patches. Our experiments on the ISPRS Potsdam dataset demonstrate that CP2M substantially mitigates overfitting, setting new benchmarks for segmentation accuracy and model robustness in remote sensing tasks.
UCloudNet: A Residual U-Net with Deep Supervision for Cloud Image Segmentation
Jan 11, 2025



Recent advancements in meteorology involve the use of ground-based sky cameras for cloud observation. Analyzing images from these cameras helps in calculating cloud coverage and understanding atmospheric phenomena. Traditionally, cloud image segmentation relied on conventional computer vision techniques. However, with the advent of deep learning, convolutional neural networks (CNNs) are increasingly applied for this purpose. Despite their effectiveness, CNNs often require many epochs to converge, posing challenges for real-time processing in sky camera systems. In this paper, we introduce a residual U-Net with deep supervision for cloud segmentation which provides better accuracy than previous approaches, and with less training consumption. By utilizing residual connection in encoders of UCloudNet, the feature extraction ability is further improved.
* 6 pages, 4 figures
Dual-Frequency Filtering Self-aware Graph Neural Networks for Homophilic and Heterophilic Graphs
Nov 18, 2024
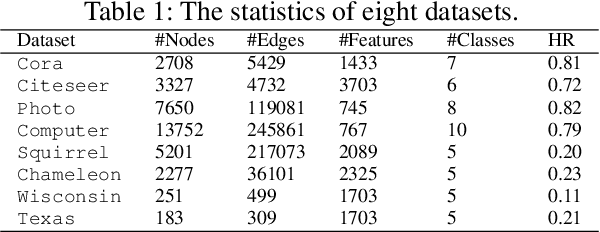

Graph Neural Networks (GNNs) have excelled in handling graph-structured data, attracting significant research interest. However, two primary challenges have emerged: interference between topology and attributes distorting node representations, and the low-pass filtering nature of most GNNs leading to the oversight of valuable high-frequency information in graph signals. These issues are particularly pronounced in heterophilic graphs. To address these challenges, we propose Dual-Frequency Filtering Self-aware Graph Neural Networks (DFGNN). DFGNN integrates low-pass and high-pass filters to extract smooth and detailed topological features, using frequency-specific constraints to minimize noise and redundancy in the respective frequency bands. The model dynamically adjusts filtering ratios to accommodate both homophilic and heterophilic graphs. Furthermore, DFGNN mitigates interference by aligning topological and attribute representations through dynamic correspondences between their respective frequency bands, enhancing overall model performance and expressiveness. Extensive experiments conducted on benchmark datasets demonstrate that DFGNN outperforms state-of-the-art methods in classification performance, highlighting its effectiveness in handling both homophilic and heterophilic graphs.
DGNN: Decoupled Graph Neural Networks with Structural Consistency between Attribute and Graph Embedding Representations
Jan 28, 2024Graph neural networks (GNNs) demonstrate a robust capability for representation learning on graphs with complex structures, showcasing superior performance in various applications. The majority of existing GNNs employ a graph convolution operation by using both attribute and structure information through coupled learning. In essence, GNNs, from an optimization perspective, seek to learn a consensus and compromise embedding representation that balances attribute and graph information, selectively exploring and retaining valid information. To obtain a more comprehensive embedding representation of nodes, a novel GNNs framework, dubbed Decoupled Graph Neural Networks (DGNN), is introduced. DGNN explores distinctive embedding representations from the attribute and graph spaces by decoupled terms. Considering that semantic graph, constructed from attribute feature space, consists of different node connection information and provides enhancement for the topological graph, both topological and semantic graphs are combined for the embedding representation learning. Further, structural consistency among attribute embedding and graph embeddings is promoted to effectively remove redundant information and establish soft connection. This involves promoting factor sharing for adjacency reconstruction matrices, facilitating the exploration of a consensus and high-level correlation. Finally, a more powerful and complete representation is achieved through the concatenation of these embeddings. Experimental results conducted on several graph benchmark datasets verify its superiority in node classification task.
Grassmannian Graph-attentional Landmark Selection for Domain Adaptation
Sep 07, 2021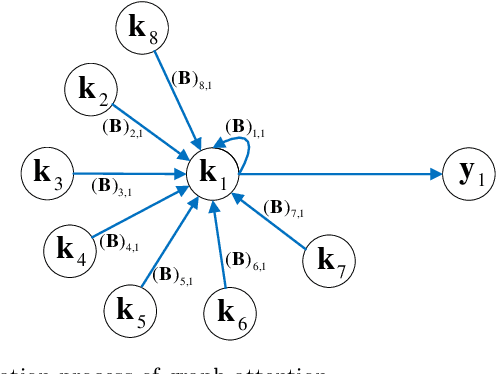


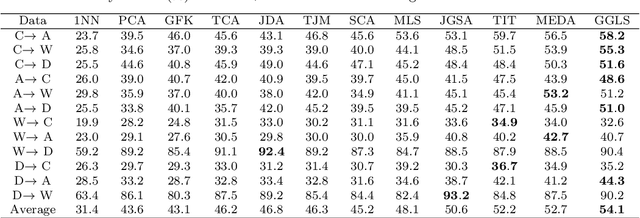
Domain adaptation aims to leverage information from the source domain to improve the classification performance in the target domain. It mainly utilizes two schemes: sample reweighting and feature matching. While the first scheme allocates different weights to individual samples, the second scheme matches the feature of two domains using global structural statistics. The two schemes are complementary with each other, which are expected to jointly work for robust domain adaptation. Several methods combine the two schemes, but the underlying relationship of samples is insufficiently analyzed due to the neglect of the hierarchy of samples and the geometric properties between samples. To better combine the advantages of the two schemes, we propose a Grassmannian graph-attentional landmark selection (GGLS) framework for domain adaptation. GGLS presents a landmark selection scheme using attention-induced neighbors of the graphical structure of samples and performs distribution adaptation and knowledge adaptation over Grassmann manifold. the former treats the landmarks of each sample differently, and the latter avoids feature distortion and achieves better geometric properties. Experimental results on different real-world cross-domain visual recognition tasks demonstrate that GGLS provides better classification accuracies compared with state-of-the-art domain adaptation methods.
GAN for Vision, KG for Relation: a Two-stage Deep Network for Zero-shot Action Recognition
May 25, 2021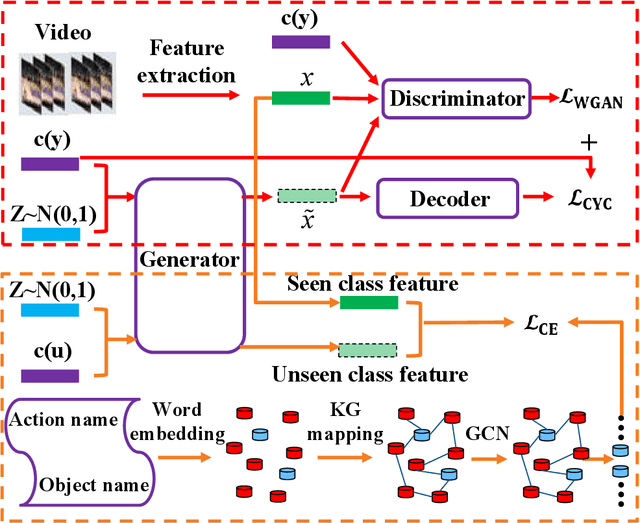
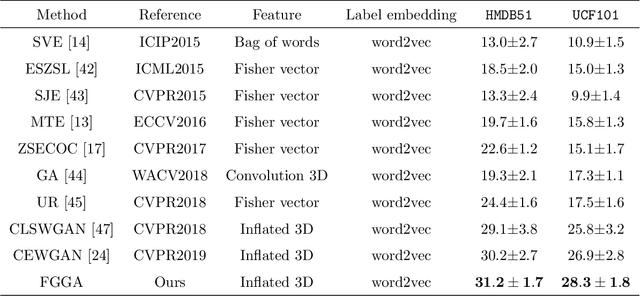

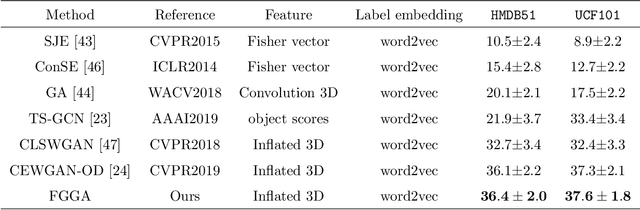
Zero-shot action recognition can recognize samples of unseen classes that are unavailable in training by exploring common latent semantic representation in samples. However, most methods neglected the connotative relation and extensional relation between the action classes, which leads to the poor generalization ability of the zero-shot learning. Furthermore, the learned classifier incline to predict the samples of seen class, which leads to poor classification performance. To solve the above problems, we propose a two-stage deep neural network for zero-shot action recognition, which consists of a feature generation sub-network serving as the sampling stage and a graph attention sub-network serving as the classification stage. In the sampling stage, we utilize a generative adversarial networks (GAN) trained by action features and word vectors of seen classes to synthesize the action features of unseen classes, which can balance the training sample data of seen classes and unseen classes. In the classification stage, we construct a knowledge graph (KG) based on the relationship between word vectors of action classes and related objects, and propose a graph convolution network (GCN) based on attention mechanism, which dynamically updates the relationship between action classes and objects, and enhances the generalization ability of zero-shot learning. In both stages, we all use word vectors as bridges for feature generation and classifier generalization from seen classes to unseen classes. We compare our method with state-of-the-art methods on UCF101 and HMDB51 datasets. Experimental results show that our proposed method improves the classification performance of the trained classifier and achieves higher accuracy.
Real-time Human Action Recognition Using Locally Aggregated Kinematic-Guided Skeletonlet and Supervised Hashing-by-Analysis Model
May 24, 2021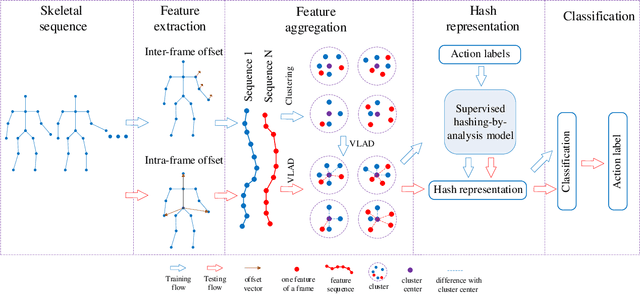
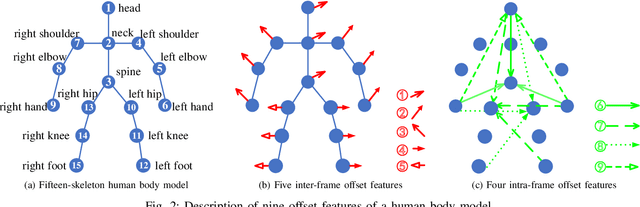
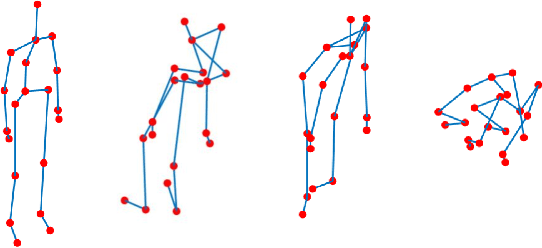
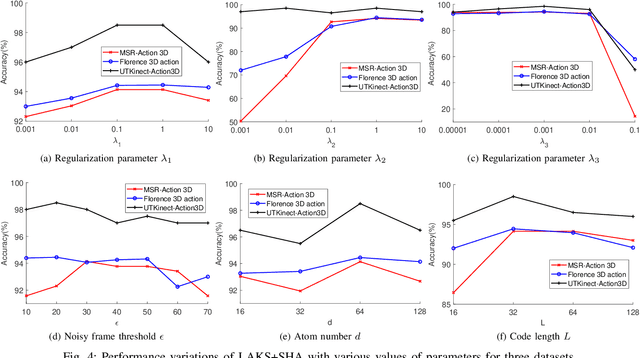
3D action recognition is referred to as the classification of action sequences which consist of 3D skeleton joints. While many research work are devoted to 3D action recognition, it mainly suffers from three problems: highly complicated articulation, a great amount of noise, and a low implementation efficiency. To tackle all these problems, we propose a real-time 3D action recognition framework by integrating the locally aggregated kinematic-guided skeletonlet (LAKS) with a supervised hashing-by-analysis (SHA) model. We first define the skeletonlet as a few combinations of joint offsets grouped in terms of kinematic principle, and then represent an action sequence using LAKS, which consists of a denoising phase and a locally aggregating phase. The denoising phase detects the noisy action data and adjust it by replacing all the features within it with the features of the corresponding previous frame, while the locally aggregating phase sums the difference between an offset feature of the skeletonlet and its cluster center together over all the offset features of the sequence. Finally, the SHA model which combines sparse representation with a hashing model, aiming at promoting the recognition accuracy while maintaining a high efficiency. Experimental results on MSRAction3D, UTKinectAction3D and Florence3DAction datasets demonstrate that the proposed method outperforms state-of-the-art methods in both recognition accuracy and implementation efficiency.