 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEAdapter: Supply abundant guidance for controllable text-to-music generation
Aug 09, 2024
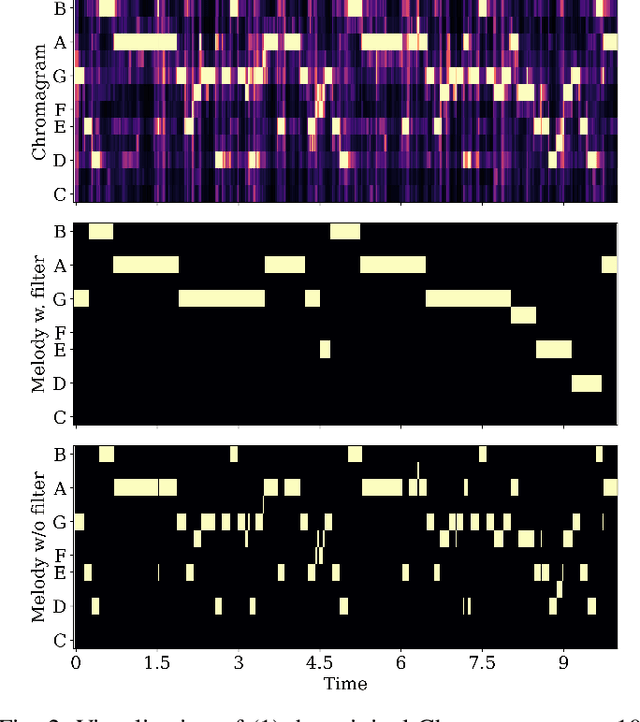

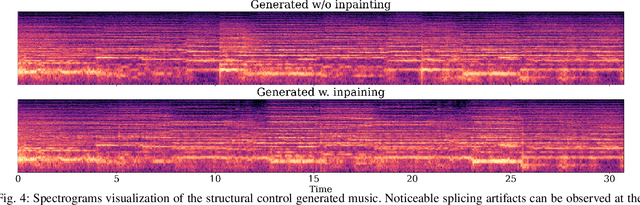
Although current text-guided music generation technology can cope with simple creative scenarios, achieving fine-grained control over individual text-modality conditions remains challenging as user demands become more intricate. Accordingly, we introduce the TEAcher Adapter (TEAdapter), a compact plugin designed to guide the generation process with diverse control information provided by users. In addition, we explore the controllable generation of extended music by leveraging TEAdapter control groups trained on data of distinct structural functionalities. In general, we consider controls over global, elemental, and structural levels. Experimental results demonstrate that the proposed TEAdapter enables multiple precise controls and ensures high-quality music generation. Our module is also lightweight and transferable to any diffusion model architecture. Available code and demos will be found soon at https://github.com/Ashley1101/TEAdapter.
* Accepted by ICME'24: IEEE International Conference on Multimedia and Expo
Grassmannian Graph-attentional Landmark Selection for Domain Adaptation
Sep 07, 2021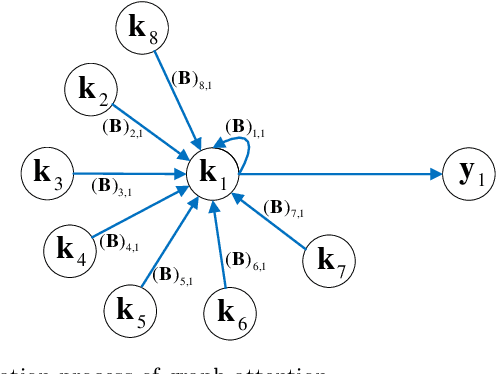


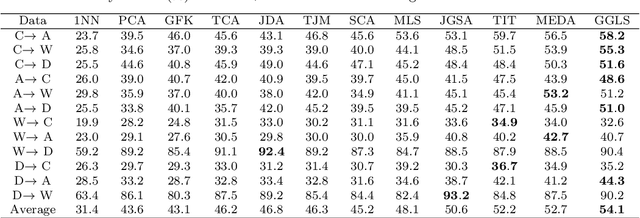
Domain adaptation aims to leverage information from the source domain to improve the classification performance in the target domain. It mainly utilizes two schemes: sample reweighting and feature matching. While the first scheme allocates different weights to individual samples, the second scheme matches the feature of two domains using global structural statistics. The two schemes are complementary with each other, which are expected to jointly work for robust domain adaptation. Several methods combine the two schemes, but the underlying relationship of samples is insufficiently analyzed due to the neglect of the hierarchy of samples and the geometric properties between samples. To better combine the advantages of the two schemes, we propose a Grassmannian graph-attentional landmark selection (GGLS) framework for domain adaptation. GGLS presents a landmark selection scheme using attention-induced neighbors of the graphical structure of samples and performs distribution adaptation and knowledge adaptation over Grassmann manifold. the former treats the landmarks of each sample differently, and the latter avoids feature distortion and achieves better geometric properties. Experimental results on different real-world cross-domain visual recognition tasks demonstrate that GGLS provides better classification accuracies compared with state-of-the-art domain adaptation methods.
GAN for Vision, KG for Relation: a Two-stage Deep Network for Zero-shot Action Recognition
May 25, 2021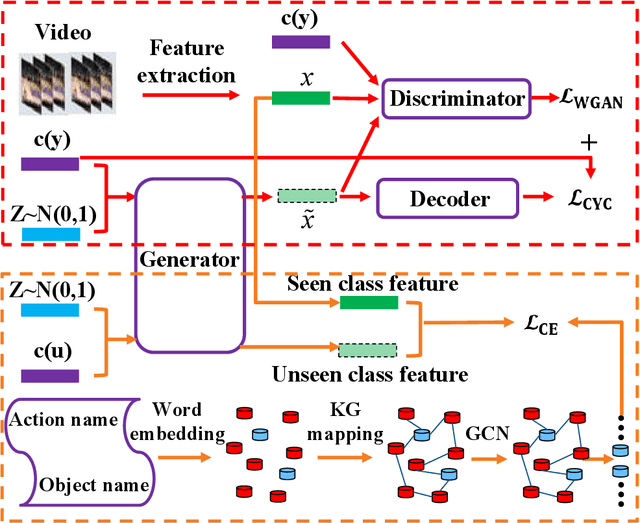
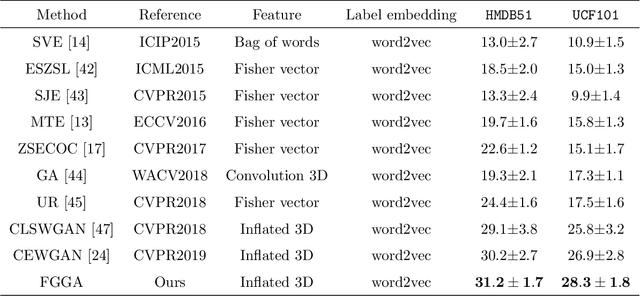

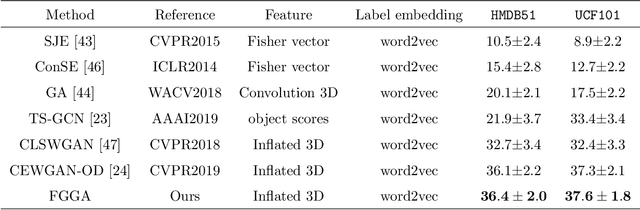
Zero-shot action recognition can recognize samples of unseen classes that are unavailable in training by exploring common latent semantic representation in samples. However, most methods neglected the connotative relation and extensional relation between the action classes, which leads to the poor generalization ability of the zero-shot learning. Furthermore, the learned classifier incline to predict the samples of seen class, which leads to poor classification performance. To solve the above problems, we propose a two-stage deep neural network for zero-shot action recognition, which consists of a feature generation sub-network serving as the sampling stage and a graph attention sub-network serving as the classification stage. In the sampling stage, we utilize a generative adversarial networks (GAN) trained by action features and word vectors of seen classes to synthesize the action features of unseen classes, which can balance the training sample data of seen classes and unseen classes. In the classification stage, we construct a knowledge graph (KG) based on the relationship between word vectors of action classes and related objects, and propose a graph convolution network (GCN) based on attention mechanism, which dynamically updates the relationship between action classes and objects, and enhances the generalization ability of zero-shot learning. In both stages, we all use word vectors as bridges for feature generation and classifier generalization from seen classes to unseen classes. We compare our method with state-of-the-art methods on UCF101 and HMDB51 datasets. Experimental results show that our proposed method improves the classification performance of the trained classifier and achieves higher accuracy.
Matrix Variate RBM and Its Applications
Jan 05, 2016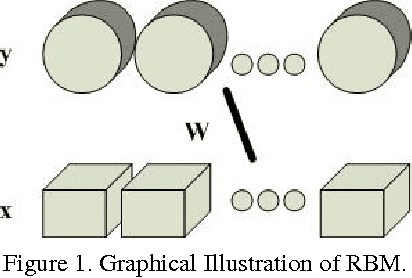
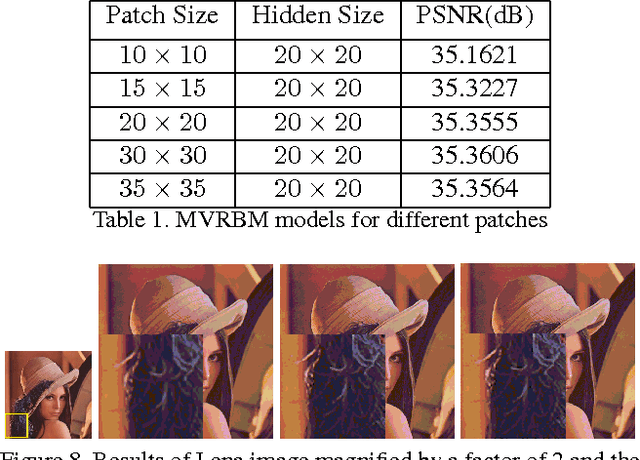
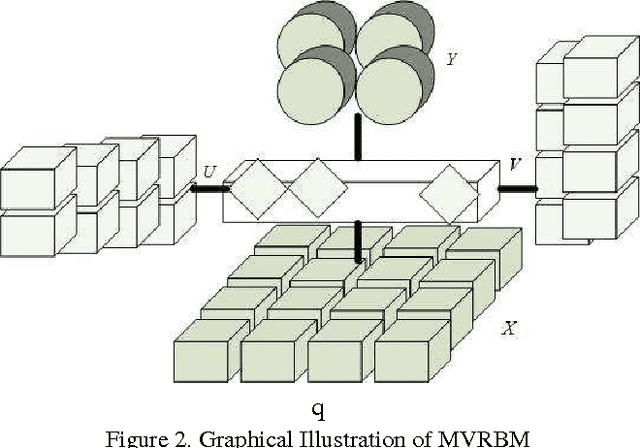

Restricted Boltzmann Machine (RBM) is an importan- t generative model modeling vectorial data. While applying an RBM in practice to images, the data have to be vec- torized. This results in high-dimensional data and valu- able spatial information has got lost in vectorization. In this paper, a Matrix-Variate Restricted Boltzmann Machine (MVRBM) model is proposed by generalizing the classic RBM to explicitly model matrix data. In the new RBM model, both input and hidden variables are in matrix forms which are connected by bilinear transforms. The MVRBM has much less model parameters, resulting in a faster train- ing algorithm while retaining comparable performance as the classic RBM. The advantages of the MVRBM have been demonstrated on two real-world applications: Image super- resolution and handwritten digit recognition.