 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEAdapter: Supply abundant guidance for controllable text-to-music generation
Aug 09, 2024
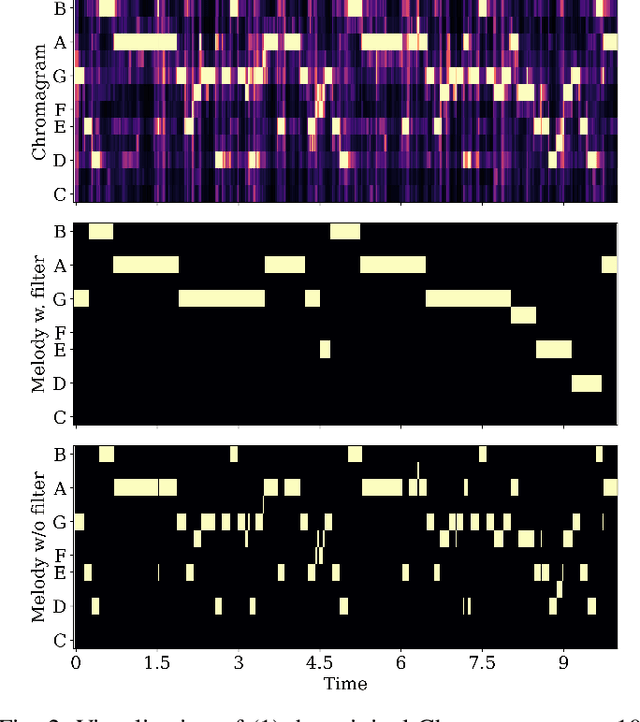

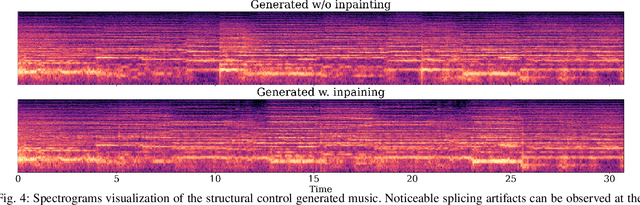
Although current text-guided music generation technology can cope with simple creative scenarios, achieving fine-grained control over individual text-modality conditions remains challenging as user demands become more intricate. Accordingly, we introduce the TEAcher Adapter (TEAdapter), a compact plugin designed to guide the generation process with diverse control information provided by users. In addition, we explore the controllable generation of extended music by leveraging TEAdapter control groups trained on data of distinct structural functionalities. In general, we consider controls over global, elemental, and structural levels. Experimental results demonstrate that the proposed TEAdapter enables multiple precise controls and ensures high-quality music generation. Our module is also lightweight and transferable to any diffusion model architecture. Available code and demos will be found soon at https://github.com/Ashley1101/TEAdapter.
* Accepted by ICME'24: IEEE International Conference on Multimedia and Expo
DQnet: Cross-Model Detail Querying for Camouflaged Object Detection
Dec 16, 2022Camouflaged objects are seamlessly blended in with their surroundings, which brings a challenging detection task in computer vision. Optimizing a convolutional neural network (CNN) for camouflaged object detection (COD) tends to activate local discriminative regions while ignoring complete object extent, causing the partial activation issue which inevitably leads to missing or redundant regions of objects. In this paper, we argue that partial activation is caused by the intrinsic characteristics of CNN, where the convolution operations produce local receptive fields and experience difficulty to capture long-range feature dependency among image regions. In order to obtain feature maps that could activate full object extent, keeping the segmental results from being overwhelmed by noisy features, a novel framework termed Cross-Model Detail Querying network (DQnet) is proposed. It reasons the relations between long-range-aware representations and multi-scale local details to make the enhanced representation fully highlight the object regions and eliminate noise on non-object regions. Specifically, a vanilla ViT pretrained with self-supervised learning (SSL) is employed to model long-range dependencies among image regions. A ResNet is employed to enable learning fine-grained spatial local details in multiple scales. Then, to effectively retrieve object-related details, a Relation-Based Querying (RBQ) module is proposed to explore window-based interactions between the global representations and the multi-scale local details. Extensive experiments are conducted on the widely used COD datasets and show that our DQnet outperforms the current state-of-the-arts.