 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE: Agentic 3D Scene Authoring via Memory-Grounded Incremental Requirement Satisfaction
Jun 12, 2026Text-driven 3D scene generation is a promising technique for digital content creation, embodied AI simulation, and interactive design, yet practical workflows often require refining, extending, or correcting existing scenes while preserving non-target content. Existing methods can produce realistic and structurally plausible scenes, but they generally lack editability with requirement-level state tracking, so part-level failures often lead to full-scene regeneration or manual intervention. To tackle this challenge, we formulate controllable 3D scene authoring as incremental requirement satisfaction, unifying construction and editing. In this paper, we present MUSE, a memory-grounded multi-agent framework in which an Architect compiles instructions into structured requirements, a Sculptor executes local scene operations, and an Inspector verifies each step while updating Working, Scene, and Skill Memory. To evaluate requirement-level controllability and preservation-aware editing, we introduce AuthorBench, offering 145 constrained construction cases and a 1,584-case preservation-aware editing pool paired with external structured checks. On full construction cases, MUSE improves All-Goal success from 37.9 to 80.7 and surface-constraint fulfillment from 35.0 to 92.6 over the strongest baseline. On a stratified 240-case editing test split, MUSE achieves 49.6 All-Goal success, 99.9 preservation rate, and only 0.6 unintended change rate. Beyond automated metrics, human evaluations on compared local-editing baselines support stronger alignment with user intent, and downstream navigation-proxy tests indicate stronger spatial stability. Combined with ablations validating our memory designs, these results establish MUSE as an effective framework for controllable 3D scene authoring.
JointEdit3D: Feed-Forward 3D Scene Editing in a Unified Latent Space
Jun 11, 2026Existing 3D scene editing methods typically rely on per-scene optimization over explicit 3D representations or cascaded edit-and-reconstruct pipelines, resulting in high test-time cost, limited 3D awareness, and structural inconsistencies. To couple appearance synthesis and geometry prediction during editing, we build on a unified RGB-geometry reconstruction-generation latent space and adapt it to feed-forward 3D scene editing. The resulting framework, \textbf{JointEdit3D}, performs asymmetric latent inpainting by observing only a single edited RGB reference latent and generating the remaining RGB views and edited geometry latent under source-scene anchoring. JointEdit3D introduces a dedicated SceneAnchor Branch to inject source-scene structure without forcing direct copying, and adopts edit/background-aware losses to balance edited-region fidelity with unedited-content preservation. To address the lack of paired resources for standardized 3D scene editing evaluation, we introduce SceneEdit3D-15K, a dataset with 15K paired editing samples and renderer-provided 3D annotations, together with SceneEdit3D-Bench, a curated 100-sample benchmark. Experiments show that JointEdit3D improves edited-region quality and 3D structural completeness over prior baselines while maintaining competitive background preservation.
Teach Multimodal Recommendation Model to See via Personalized Visual Extraction and Adaptive Learning
Jun 08, 2026Multimodal sequential recommendation (MSR) incorporates textual and visual information to improve recommendation quality. However, recent studies and our empirical analysis show that visual features are often underutilized, thereby contributing far less than textual signals. We attribute this issue to two factors: insufficient visual representation learning (pretrained encoders fail to capture preference-relevant cues) and unbalanced visual-text optimization (textual features dominate the learning process). To address these issues, we propose Teach Multimodal Recommendation Model to See via Personalized Visual Extraction and Adaptive Learning (REVEAL), a plug-and-play framework that enhances visual representation learning and cross-modal optimization without modifying the original recommendation backbone. REVEAL consists of Feedback-Guided Visual Extraction (FVE), which refines prompt-guided visual extraction through task-level feedback, and Adaptive Visual Learning (AVL), which dynamically reweights visual learning to alleviate modality imbalance. Experiments on multiple real-world datasets and MSR backbones demonstrate that REVEAL consistently improves recommendation performance. Further analysis shows that these gains arise from more effective attention to preference-relevant visual regions and better visual utilization during training. The code is available at https://github.com/YutongLi2024/REVEAL.
DailyArt: Discovering Articulation from Single Static Images via Latent Dynamics
Apr 09, 2026Articulated objects are essential for embodied AI and world models, yet inferring their kinematics from a single closed-state image remains challenging because crucial motion cues are often occluded. Existing methods either require multi-state observations or rely on explicit part priors, retrieval, or other auxiliary inputs that partially expose the structure to be inferred. In this work, we present DailyArt, which formulates articulated joint estimation from a single static image as a synthesis-mediated reasoning problem. Instead of directly regressing joints from a heavily occluded observation, DailyArt first synthesizes a maximally articulated opened state under the same camera view to expose articulation cues, and then estimates the full set of joint parameters from the discrepancy between the observed and synthesized states. Using a set-prediction formulation, DailyArt recovers all joints simultaneously without requiring object-specific templates, multi-view inputs, or explicit part annotations at test time. Taking estimated joints as conditions, the framework further supports part-level novel state synthesis as a downstream capability. Extensive experiments show that DailyArt achieves strong performance in articulated joint estimation and supports part-level novel state synthesis conditioned on joints. Project page is available at https://rangooo123.github.io/DaliyArt.github.io/.
FlashMotion: Few-Step Controllable Video Generation with Trajectory Guidance
Mar 12, 2026Recent advances in trajectory-controllable video generation have achieved remarkable progress. Previous methods mainly use adapter-based architectures for precise motion control along predefined trajectories. However, all these methods rely on a multi-step denoising process, leading to substantial time redundancy and computational overhead. While existing video distillation methods successfully distill multi-step generators into few-step, directly applying these approaches to trajectory-controllable video generation results in noticeable degradation in both video quality and trajectory accuracy. To bridge this gap, we introduce FlashMotion, a novel training framework designed for few-step trajectory-controllable video generation. We first train a trajectory adapter on a multi-step video generator for precise trajectory control. Then, we distill the generator into a few-step version to accelerate video generation. Finally, we finetune the adapter using a hybrid strategy that combines diffusion and adversarial objectives, aligning it with the few-step generator to produce high-quality, trajectory-accurate videos. For evaluation, we introduce FlashBench, a benchmark for long-sequence trajectory-controllable video generation that measures both video quality and trajectory accuracy across varying numbers of foreground objects. Experiments on two adapter architectures show that FlashMotion surpasses existing video distillation methods and previous multi-step models in both visual quality and trajectory consistency.
Preference Score Distillation: Leveraging 2D Rewards to Align Text-to-3D Generation with Human Preference
Mar 02, 2026Human preference alignment presents a critical yet underexplored challenge for diffusion models in text-to-3D generation. Existing solutions typically require task-specific fine-tuning, posing significant hurdles in data-scarce 3D domains. To address this, we propose Preference Score Distillation (PSD), an optimization-based framework that leverages pretrained 2D reward models for human-aligned text-to-3D synthesis without 3D training data. Our key insight stems from the incompatibility of pixel-level gradients: due to the absence of noisy samples during reward model training, direct application of 2D reward gradients disturbs the denoising process. Noticing that similar issue occurs in the naive classifier guidance in conditioned diffusion models, we fundamentally rethink preference alignment as a classifier-free guidance (CFG)-style mechanism through our implicit reward model. Furthermore, recognizing that frozen pretrained diffusion models constrain performance, we introduce an adaptive strategy to co-optimize preference scores and negative text embeddings. By incorporating CFG during optimization, online refinement of negative text embeddings dynamically enhances alignment. To our knowledge, we are the first to bridge human preference alignment with CFG theory under score distillation framework. Experiments demonstrate the superiority of PSD in aesthetic metrics, seamless integration with diverse pipelines, and strong extensibility.
UniHand: A Unified Model for Diverse Controlled 4D Hand Motion Modeling
Feb 25, 2026Hand motion plays a central role in human interaction, yet modeling realistic 4D hand motion (i.e., 3D hand pose sequences over time) remains challenging. Research in this area is typically divided into two tasks: (1) Estimation approaches reconstruct precise motion from visual observations, but often fail under hand occlusion or absence; (2) Generation approaches focus on synthesizing hand poses by exploiting generative priors under multi-modal structured inputs and infilling motion from incomplete sequences. However, this separation not only limits the effective use of heterogeneous condition signals that frequently arise in practice, but also prevents knowledge transfer between the two tasks. We present UniHand, a unified diffusion-based framework that formulates both estimation and generation as conditional motion synthesis. UniHand integrates heterogeneous inputs by embedding structured signals into a shared latent space through a joint variational autoencoder, which aligns conditions such as MANO parameters and 2D skeletons. Visual observations are encoded with a frozen vision backbone, while a dedicated hand perceptron extracts hand-specific cues directly from image features, removing the need for complex detection and cropping pipelines. A latent diffusion model then synthesizes consistent motion sequences from these diverse conditions. Extensive experiments across multiple benchmarks demonstrate that UniHand delivers robust and accurate hand motion modeling, maintaining performance under severe occlusions and temporally incomplete inputs.
Preserving Cross-Modal Consistency for CLIP-based Class-Incremental Learning
Nov 14, 2025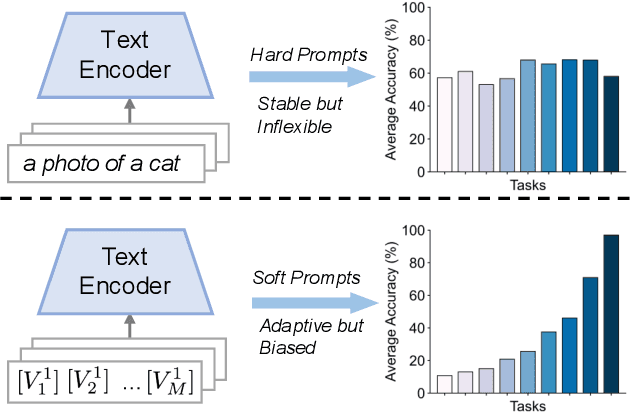
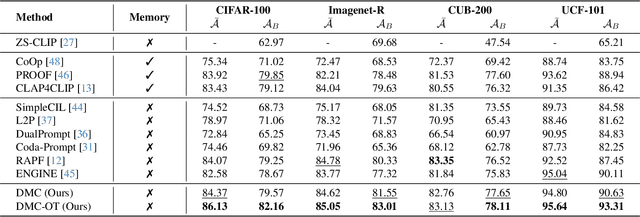
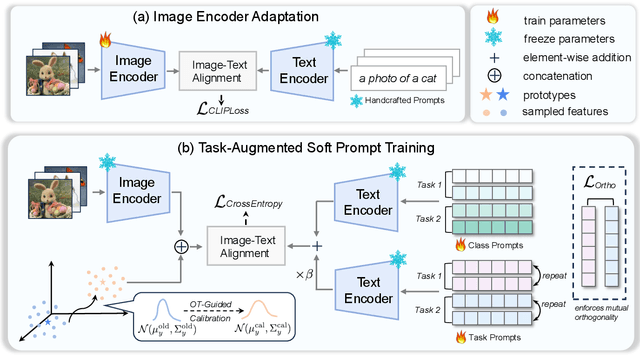
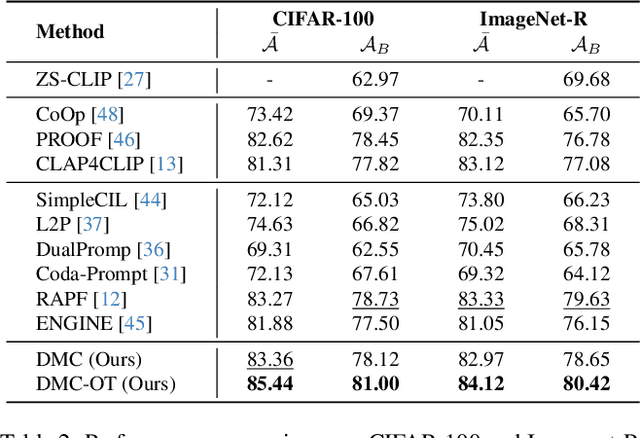
Class-incremental learning (CIL) enables models to continuously learn new categories from sequential tasks without forgetting previously acquired knowledge. While recent advances in vision-language models such as CLIP have demonstrated strong generalization across domains, extending them to continual settings remains challenging. In particular, learning task-specific soft prompts for newly introduced classes often leads to severe classifier bias, as the text prototypes overfit to recent categories when prior data are unavailable. In this paper, we propose DMC, a simple yet effective two-stage framework for CLIP-based CIL that decouples the adaptation of the vision encoder and the optimization of textual soft prompts. Each stage is trained with the other frozen, allowing one modality to act as a stable semantic anchor for the other to preserve cross-modal alignment. Furthermore, current CLIP-based CIL approaches typically store class-wise Gaussian statistics for generative replay, yet they overlook the distributional drift that arises when the vision encoder is updated over time. To address this issue, we introduce DMC-OT, an enhanced version of DMC that incorporates an optimal-transport guided calibration strategy to align memory statistics across evolving encoders, along with a task-specific prompting design that enhances inter-task separability. Extensive experiments on CIFAR-100, Imagenet-R, CUB-200, and UCF-101 demonstrate that both DMC and DMC-OT achieve state-of-the-art performance, with DMC-OT further improving accuracy by an average of 1.80%.
Moyun: A Diffusion-Based Model for Style-Specific Chinese Calligraphy Generation
Oct 10, 2024



Although Chinese calligraphy generation has achieved style transfer, generating calligraphy by specifying the calligrapher, font, and character style remains challenging. To address this, we propose a new Chinese calligraphy generation model 'Moyun' , which replaces the Unet in the Diffusion model with Vision Mamba and introduces the TripleLabel control mechanism to achieve controllable calligraphy generation. The model was tested on our large-scale dataset 'Mobao' of over 1.9 million images, and the results demonstrate that 'Moyun' can effectively control the generation process and produce calligraphy in the specified style. Even for calligraphy the calligrapher has not written, 'Moyun' can generate calligraphy that matches the style of the calligrapher.
TEAdapter: Supply abundant guidance for controllable text-to-music generation
Aug 09, 2024
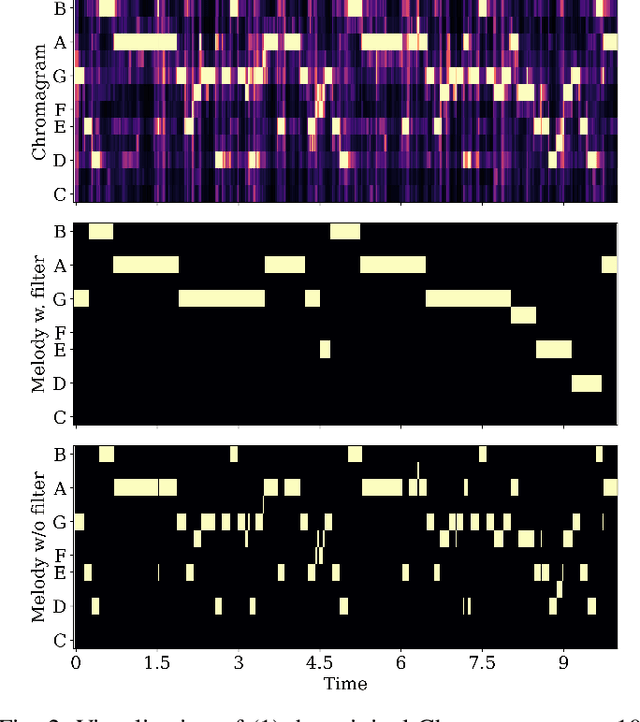

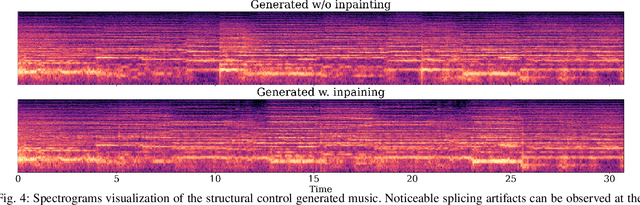
Although current text-guided music generation technology can cope with simple creative scenarios, achieving fine-grained control over individual text-modality conditions remains challenging as user demands become more intricate. Accordingly, we introduce the TEAcher Adapter (TEAdapter), a compact plugin designed to guide the generation process with diverse control information provided by users. In addition, we explore the controllable generation of extended music by leveraging TEAdapter control groups trained on data of distinct structural functionalities. In general, we consider controls over global, elemental, and structural levels. Experimental results demonstrate that the proposed TEAdapter enables multiple precise controls and ensures high-quality music generation. Our module is also lightweight and transferable to any diffusion model architecture. Available code and demos will be found soon at https://github.com/Ashley1101/TEAdapter.
* Accepted by ICME'24: IEEE International Conference on Multimedia and Expo