 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongAV-Compass: Towards Unified Evaluation of Minute-Scale Audio-Visual Generation Across T2AV, I2AV, and V2AV
May 25, 2026Audio-visual generation is rapidly advancing from short clips to minute-long content, while existing evaluation protocols remain largely confined to short-form settings. Existing benchmarks primarily focus on 5--10 second text-conditioned generation and rarely support unified evaluation across text, image, and video conditioning modalities. Moreover, they provide limited insight into how identity consistency, narrative coherence, and audio-visual alignment degrade over extended temporal horizons. To bridge this gap, we introduce LongAV-Compass, a systematic benchmark for minute-long audio-visual generation. LongAV-Compass contains 284 curated test cases spanning text-to-audio-video (T2AV), image-to-audio-video (I2AV), and video-to-audio-video (V2AV), organized by application scenario and generation complexity. The benchmark combines taxonomy-guided benchmark construction with a unified evaluation framework that integrates MLLM-assisted assessment with complementary perceptual and multimodal metrics, including DINO-v2, ArcFace, CLIP, and ImageBind. The framework evaluates more than 20 fine-grained dimensions covering within-segment quality, cross-segment consistency, global narrative coherence, semantic alignment, and audio-visual synchronization. Through experiments on 11 representative models together with human-alignment validation, LongAV-Compass provides a diagnostic testbed for analyzing the limitations of current systems in sustaining coherent, semantically aligned, and temporally consistent minute-scale audio-visual generation across diverse input modalities.
GenMRP: A Generative Multi-Route Planning Framework for Efficient and Personalized Real-Time Industrial Navigation
Feb 04, 2026Existing industrial-scale navigation applications contend with massive road networks, typically employing two main categories of approaches for route planning. The first relies on precomputed road costs for optimal routing and heuristic algorithms for generating alternatives, while the second, generative methods, has recently gained significant attention. However, the former struggles with personalization and route diversity, while the latter fails to meet the efficiency requirements of large-scale real-time scenarios. To address these limitations, we propose GenMRP, a generative framework for multi-route planning. To ensure generation efficiency, GenMRP first introduces a skeleton-to-capillary approach that dynamically constructs a relevant sub-network significantly smaller than the full road network. Within this sub-network, routes are generated iteratively. The first iteration identifies the optimal route, while the subsequent ones generate alternatives that balance quality and diversity using the newly proposed correctional boosting approach. Each iteration incorporates road features, user historical sequences, and previously generated routes into a Link Cost Model to update road costs, followed by route generation using the Dijkstra algorithm. Extensive experiments show that GenMRP achieves state-of-the-art performance with high efficiency in both offline and online environments. To facilitate further research, we have publicly released the training and evaluation dataset. GenMRP has been fully deployed in a real-world navigation app, demonstrating its effectiveness and benefits.
SCASRec: A Self-Correcting and Auto-Stopping Model for Generative Route List Recommendation
Feb 03, 2026Route recommendation systems commonly adopt a multi-stage pipeline involving fine-ranking and re-ranking to produce high-quality ordered recommendations. However, this paradigm faces three critical limitations. First, there is a misalignment between offline training objectives and online metrics. Offline gains do not necessarily translate to online improvements. Actual performance must be validated through A/B testing, which may potentially compromise the user experience. Second, redundancy elimination relies on rigid, handcrafted rules that lack adaptability to the high variance in user intent and the unstructured complexity of real-world scenarios. Third, the strict separation between fine-ranking and re-ranking stages leads to sub-optimal performance. Since each module is optimized in isolation, the fine-ranking stage remains oblivious to the list-level objectives (e.g., diversity) targeted by the re-ranker, thereby preventing the system from achieving a jointly optimized global optimum. To overcome these intertwined challenges, we propose \textbf{SCASRec} (\textbf{S}elf-\textbf{C}orrecting and \textbf{A}uto-\textbf{S}topping \textbf{Rec}ommendation), a unified generative framework that integrates ranking and redundancy elimination into a single end-to-end process. SCASRec introduces a stepwise corrective reward (SCR) to guide list-wise refinement by focusing on hard samples, and employs a learnable End-of-Recommendation (EOR) token to terminate generation adaptively when no further improvement is expected. Experiments on two large-scale, open-sourced route recommendation datasets demonstrate that SCASRec establishes an SOTA in offline and online settings. SCASRec has been fully deployed in a real-world navigation app, demonstrating its effectiveness.
Proto-EVFL: Enhanced Vertical Federated Learning via Dual Prototype with Extremely Unaligned Data
Jul 30, 2025In vertical federated learning (VFL), multiple enterprises address aligned sample scarcity by leveraging massive locally unaligned samples to facilitate collaborative learning. However, unaligned samples across different parties in VFL can be extremely class-imbalanced, leading to insufficient feature representation and limited model prediction space. Specifically, class-imbalanced problems consist of intra-party class imbalance and inter-party class imbalance, which can further cause local model bias and feature contribution inconsistency issues, respectively. To address the above challenges, we propose Proto-EVFL, an enhanced VFL framework via dual prototypes. We first introduce class prototypes for each party to learn relationships between classes in the latent space, allowing the active party to predict unseen classes. We further design a probabilistic dual prototype learning scheme to dynamically select unaligned samples by conditional optimal transport cost with class prior probability. Moreover, a mixed prior guided module guides this selection process by combining local and global class prior probabilities. Finally, we adopt an \textit{adaptive gated feature aggregation strategy} to mitigate feature contribution inconsistency by dynamically weighting and aggregating local features across different parties. We proved that Proto-EVFL, as the first bi-level optimization framework in VFL, has a convergence rate of 1/\sqrt T. Extensive experiments on various datasets validate the superiority of our Proto-EVFL. Even in a zero-shot scenario with one unseen class, it outperforms baselines by at least 6.97%
SafeMove-RL: A Certifiable Reinforcement Learning Framework for Dynamic Motion Constraints in Trajectory Planning
May 19, 2025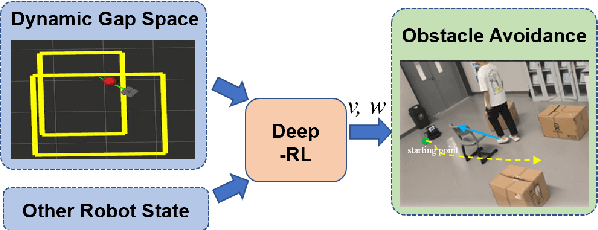

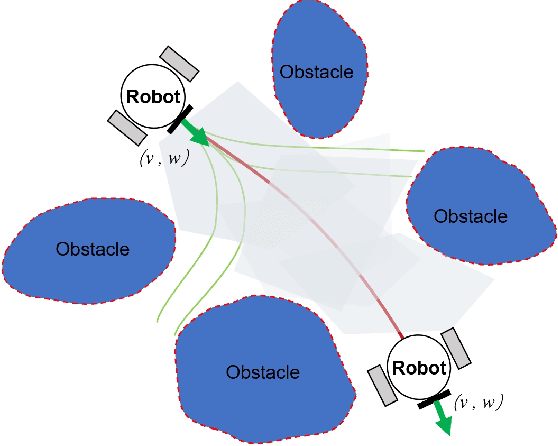
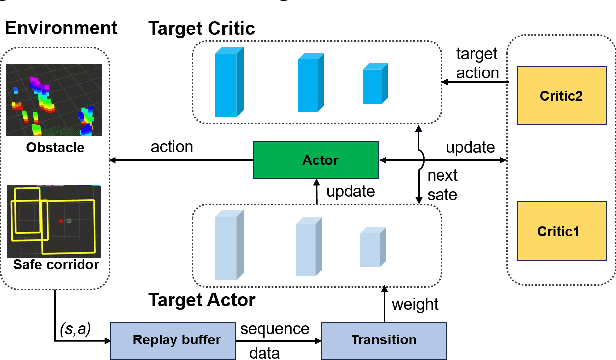
This study presents a dynamic safety margin-based reinforcement learning framework for local motion planning in dynamic and uncertain environments. The proposed planner integrates real-time trajectory optimization with adaptive gap analysis, enabling effective feasibility assessment under partial observability constraints. To address safety-critical computations in unknown scenarios, an enhanced online learning mechanism is introduced, which dynamically corrects spatial trajectories by forming dynamic safety margins while maintaining control invariance. Extensive evaluations, including ablation studies and comparisons with state-of-the-art algorithms, demonstrate superior success rates and computational efficiency. The framework's effectiveness is further validated on both simulated and physical robotic platforms.
STContext: A Multifaceted Dataset for Developing Context-aware Spatio-temporal Crowd Mobility Prediction Models
Jan 07, 2025In smart cities, context-aware spatio-temporal crowd flow prediction (STCFP) models leverage contextual features (e.g., weather) to identify unusual crowd mobility patterns and enhance prediction accuracy. However, the best practice for incorporating contextual features remains unclear due to inconsistent usage of contextual features in different papers. Developing a multifaceted dataset with rich types of contextual features and STCFP scenarios is crucial for establishing a principled context modeling paradigm. Existing open crowd flow datasets lack an adequate range of contextual features, which poses an urgent requirement to build a multifaceted dataset to fill these research gaps. To this end, we create STContext, a multifaceted dataset for developing context-aware STCFP models. Specifically, STContext provides nine spatio-temporal datasets across five STCFP scenarios and includes ten contextual features, including weather, air quality index, holidays, points of interest, road networks, etc. Besides, we propose a unified workflow for incorporating contextual features into deep STCFP methods, with steps including feature transformation, dependency modeling, representation fusion, and training strategies. Through extensive experiments, we have obtained several useful guidelines for effective context modeling and insights for future research. The STContext is open-sourced at https://github.com/Liyue-Chen/STContext.
HC-LLM: Historical-Constrained Large Language Models for Radiology Report Generation
Dec 15, 2024



Radiology report generation (RRG) models typically focus on individual exams, often overlooking the integration of historical visual or textual data, which is crucial for patient follow-ups. Traditional methods usually struggle with long sequence dependencies when incorporating historical information, but large language models (LLMs) excel at in-context learning, making them well-suited for analyzing longitudinal medical data. In light of this, we propose a novel Historical-Constrained Large Language Models (HC-LLM) framework for RRG, empowering LLMs with longitudinal report generation capabilities by constraining the consistency and differences between longitudinal images and their corresponding reports. Specifically, our approach extracts both time-shared and time-specific features from longitudinal chest X-rays and diagnostic reports to capture disease progression. Then, we ensure consistent representation by applying intra-modality similarity constraints and aligning various features across modalities with multimodal contrastive and structural constraints. These combined constraints effectively guide the LLMs in generating diagnostic reports that accurately reflect the progression of the disease, achieving state-of-the-art results on the Longitudinal-MIMIC dataset. Notably, our approach performs well even without historical data during testing and can be easily adapted to other multimodal large models, enhancing its versatility.
DTFormer: A Transformer-Based Method for Discrete-Time Dynamic Graph Representation Learning
Jul 26, 2024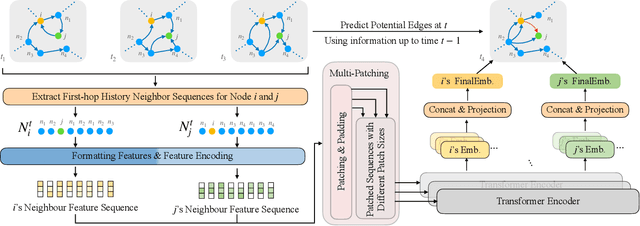
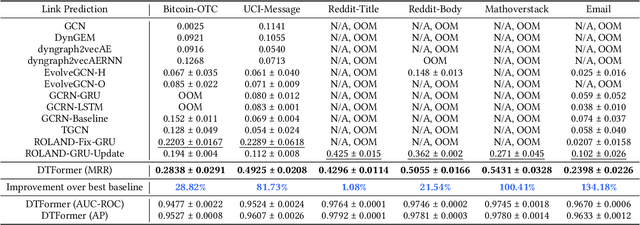
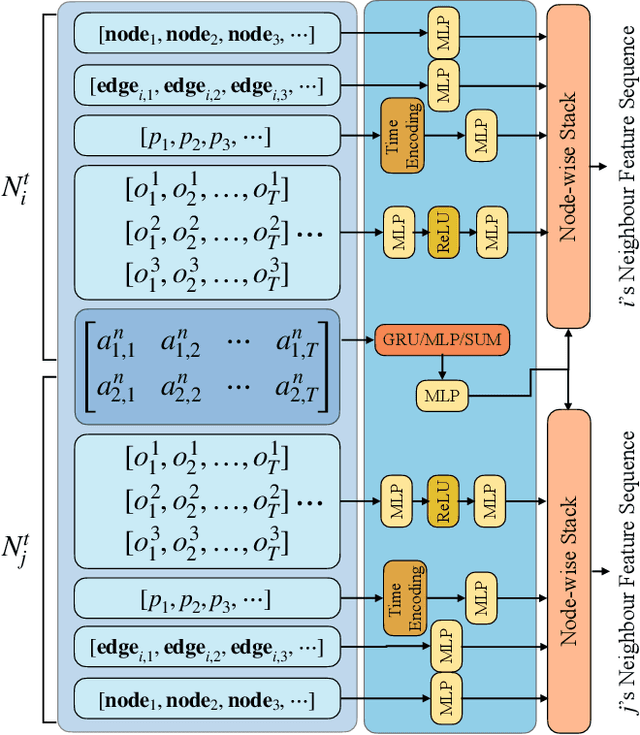
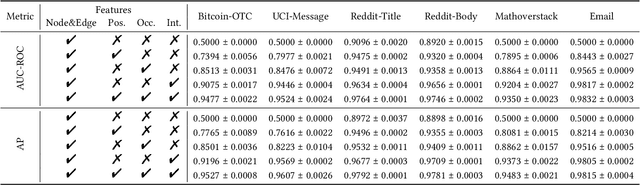
Discrete-Time Dynamic Graphs (DTDGs), which are prevalent in real-world implementations and notable for their ease of data acquisition, have garnered considerable attention from both academic researchers and industry practitioners. The representation learning of DTDGs has been extensively applied to model the dynamics of temporally changing entities and their evolving connections. Currently, DTDG representation learning predominantly relies on GNN+RNN architectures, which manifest the inherent limitations of both Graph Neural Networks (GNNs) and Recurrent Neural Networks (RNNs). GNNs suffer from the over-smoothing issue as the models architecture goes deeper, while RNNs struggle to capture long-term dependencies effectively. GNN+RNN architectures also grapple with scaling to large graph sizes and long sequences. Additionally, these methods often compute node representations separately and focus solely on individual node characteristics, thereby overlooking the behavior intersections between the two nodes whose link is being predicted, such as instances where the two nodes appear together in the same context or share common neighbors. This paper introduces a novel representation learning method DTFormer for DTDGs, pivoting from the traditional GNN+RNN framework to a Transformer-based architecture. Our approach exploits the attention mechanism to concurrently process topological information within the graph at each timestamp and temporal dynamics of graphs along the timestamps, circumventing the aforementioned fundamental weakness of both GNNs and RNNs. Moreover, we enhance the model's expressive capability by incorporating the intersection relationships among nodes and integrating a multi-patching module. Extensive experiments conducted on six public dynamic graph benchmark datasets confirm our model's efficacy, achieving the SOTA performance.
Hierarchical Multi-modal Transformer for Cross-modal Long Document Classification
Jul 14, 2024
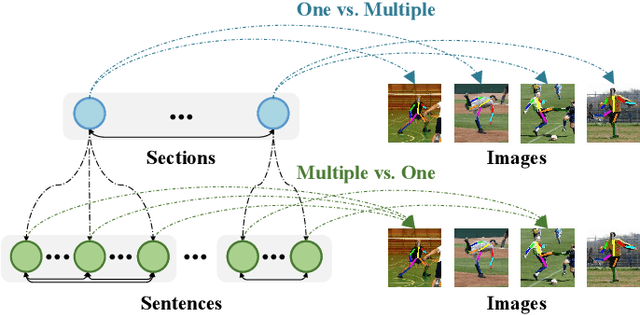
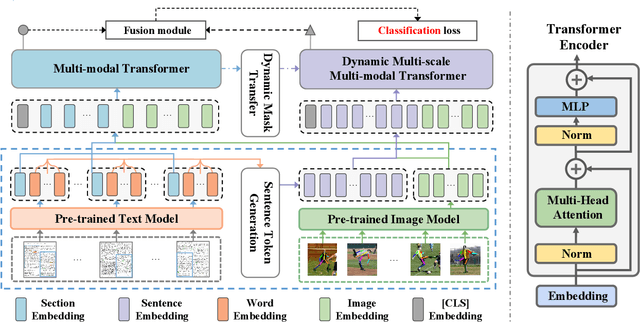
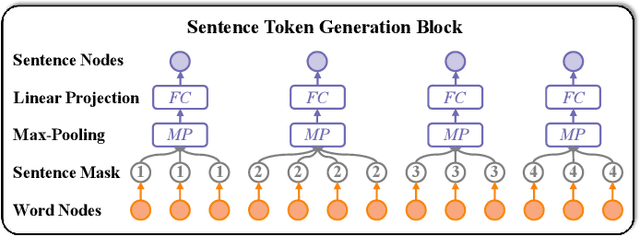
Long Document Classification (LDC) has gained significant attention recently. However, multi-modal data in long documents such as texts and images are not being effectively utilized. Prior studies in this area have attempted to integrate texts and images in document-related tasks, but they have only focused on short text sequences and images of pages. How to classify long documents with hierarchical structure texts and embedding images is a new problem and faces multi-modal representation difficulties. In this paper, we propose a novel approach called Hierarchical Multi-modal Transformer (HMT) for cross-modal long document classification. The HMT conducts multi-modal feature interaction and fusion between images and texts in a hierarchical manner. Our approach uses a multi-modal transformer and a dynamic multi-scale multi-modal transformer to model the complex relationships between image features, and the section and sentence features. Furthermore, we introduce a new interaction strategy called the dynamic mask transfer module to integrate these two transformers by propagating features between them. To validate our approach, we conduct cross-modal LDC experiments on two newly created and two publicly available multi-modal long document datasets, and the results show that the proposed HMT outperforms state-of-the-art single-modality and multi-modality methods.
Teaching with Uncertainty: Unleashing the Potential of Knowledge Distillation in Object Detection
Jun 11, 2024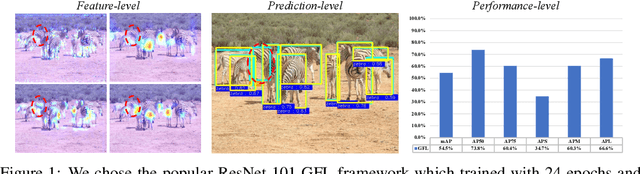
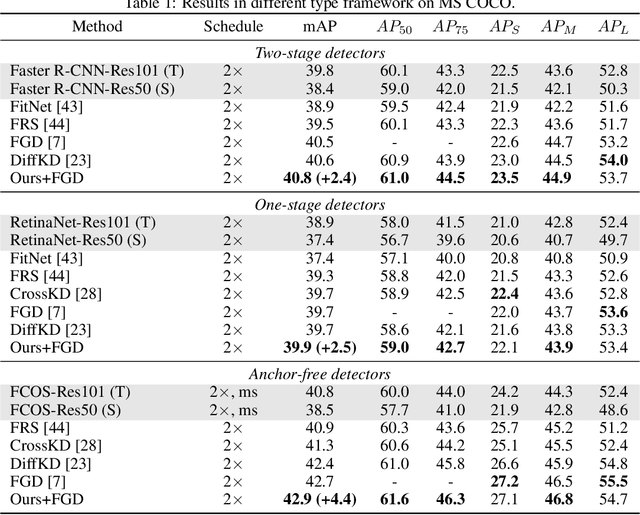
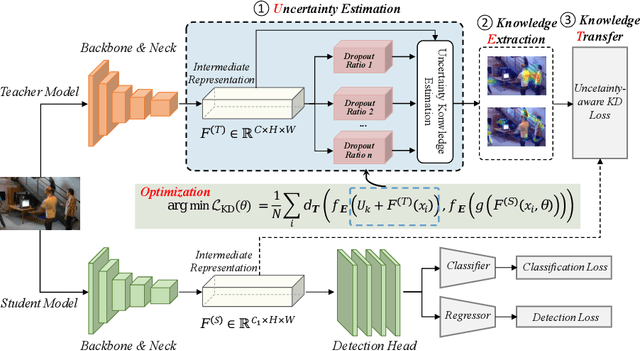
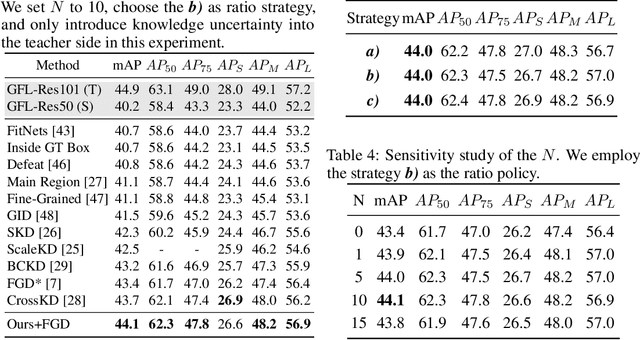
Knowledge distillation (KD) is a widely adopted and effective method for compressing models in object detection tasks. Particularly, feature-based distillation methods have shown remarkable performance. Existing approaches often ignore the uncertainty in the teacher model's knowledge, which stems from data noise and imperfect training. This limits the student model's ability to learn latent knowledge, as it may overly rely on the teacher's imperfect guidance. In this paper, we propose a novel feature-based distillation paradigm with knowledge uncertainty for object detection, termed "Uncertainty Estimation-Discriminative Knowledge Extraction-Knowledge Transfer (UET)", which can seamlessly integrate with existing distillation methods. By leveraging the Monte Carlo dropout technique, we introduce knowledge uncertainty into the training process of the student model, facilitating deeper exploration of latent knowledge. Our method performs effectively during the KD process without requiring intricate structures or extensive computational resources. Extensive experiments validate the effectiveness of our proposed approach across various distillation strategies, detectors, and backbone architectures. Specifically, following our proposed paradigm, the existing FGD method achieves state-of-the-art (SoTA) performance, with ResNet50-based GFL achieving 44.1% mAP on the COCO dataset, surpassing the baselines by 3.9%.