 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Multi-Agent Collaboration for Automated Research
Mar 31, 2026As AI agents evolve, the community is rapidly shifting from single Large Language Models (LLMs) to Multi-Agent Systems (MAS) to overcome cognitive bottlenecks in automated research. However, the optimal multi-agent coordination framework for these autonomous agents remains largely unexplored. In this paper, we present a systematic empirical study investigating the comparative efficacy of distinct multi-agent structures for automated machine learning optimization. Utilizing a rigorously controlled, execution-based testbed equipped with Git worktree isolation and explicit global memory, we benchmark a single-agent baseline against two multi-agent paradigms: a subagent architecture (parallel exploration with post-hoc consolidation) and an agent team architecture (experts with pre-execution handoffs). By evaluating these systems under strictly fixed computational time budgets, our findings reveal a fundamental trade-off between operational stability and theoretical deliberation. The subagent mode functions as a highly resilient, high-throughput search engine optimal for broad, shallow optimizations under strict time constraints. Conversely, the agent team topology exhibits higher operational fragility due to multi-author code generation but achieves the deep theoretical alignment necessary for complex architectural refactoring given extended compute budgets. These empirical insights provide actionable guidelines for designing future autoresearch systems, advocating for dynamically routed architectures that adapt their collaborative structures to real-time task complexity.
A Novel Immune Algorithm for Multiparty Multiobjective Optimization
Mar 29, 2026Traditional multiobjective optimization problems (MOPs) are insufficiently equipped for scenarios involving multiple decision makers (DMs), which are prevalent in many practical applications. These scenarios are categorized as multiparty multiobjective optimization problems (MPMOPs). For MPMOPs, the goal is to find a solution set that is as close to the Pareto front of each DM as much as possible. This poses challenges for evolutionary algorithms in terms of searching and selecting. To better solve MPMOPs, this paper proposes a novel approach called the multiparty immune algorithm (MPIA). The MPIA incorporates an inter-party guided crossover strategy based on the individual's non-dominated sorting ranks from different DM perspectives and an adaptive activation strategy based on the proposed multiparty cover metric (MCM). These strategies enable MPIA to activate suitable individuals for the next operations, maintain population diversity from different DM perspectives, and enhance the algorithm's search capability. To evaluate the performance of MPIA, we compare it with ordinary multiobjective evolutionary algorithms (MOEAs) and state-of-the-art multiparty multiobjective optimization evolutionary algorithms (MPMOEAs) by solving synthetic multiparty multiobjective problems and real-world biparty multiobjective unmanned aerial vehicle path planning (BPUAV-PP) problems involving multiple DMs. Experimental results demonstrate that MPIA outperforms other algorithms.
* \c{opyright} 2026 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Ctrl&Shift: High-Quality Geometry-Aware Object Manipulation in Visual Generation
Feb 11, 2026Object-level manipulation, relocating or reorienting objects in images or videos while preserving scene realism, is central to film post-production, AR, and creative editing. Yet existing methods struggle to jointly achieve three core goals: background preservation, geometric consistency under viewpoint shifts, and user-controllable transformations. Geometry-based approaches offer precise control but require explicit 3D reconstruction and generalize poorly; diffusion-based methods generalize better but lack fine-grained geometric control. We present Ctrl&Shift, an end-to-end diffusion framework to achieve geometry-consistent object manipulation without explicit 3D representations. Our key insight is to decompose manipulation into two stages, object removal and reference-guided inpainting under explicit camera pose control, and encode both within a unified diffusion process. To enable precise, disentangled control, we design a multi-task, multi-stage training strategy that separates background, identity, and pose signals across tasks. To improve generalization, we introduce a scalable real-world dataset construction pipeline that generates paired image and video samples with estimated relative camera poses. Extensive experiments demonstrate that Ctrl&Shift achieves state-of-the-art results in fidelity, viewpoint consistency, and controllability. To our knowledge, this is the first framework to unify fine-grained geometric control and real-world generalization for object manipulation, without relying on any explicit 3D modeling.
Mirror: A Multi-Agent System for AI-Assisted Ethics Review
Feb 09, 2026Ethics review is a foundational mechanism of modern research governance, yet contemporary systems face increasing strain as ethical risks arise as structural consequences of large-scale, interdisciplinary scientific practice. The demand for consistent and defensible decisions under heterogeneous risk profiles exposes limitations in institutional review capacity rather than in the legitimacy of ethics oversight. Recent advances in large language models (LLMs) offer new opportunities to support ethics review, but their direct application remains limited by insufficient ethical reasoning capability, weak integration with regulatory structures, and strict privacy constraints on authentic review materials. In this work, we introduce Mirror, an agentic framework for AI-assisted ethical review that integrates ethical reasoning, structured rule interpretation, and multi-agent deliberation within a unified architecture. At its core is EthicsLLM, a foundational model fine-tuned on EthicsQA, a specialized dataset of 41K question-chain-of-thought-answer triples distilled from authoritative ethics and regulatory corpora. EthicsLLM provides detailed normative and regulatory understanding, enabling Mirror to operate in two complementary modes. Mirror-ER (expedited Review) automates expedited review through an executable rule base that supports efficient and transparent compliance checks for minimal-risk studies. Mirror-CR (Committee Review) simulates full-board deliberation through coordinated interactions among expert agents, an ethics secretary agent, and a principal investigator agent, producing structured, committee-level assessments across ten ethical dimensions. Empirical evaluations demonstrate that Mirror significantly improves the quality, consistency, and professionalism of ethics assessments compared with strong generalist LLMs.
Benchmarking Continuous Dynamic Multi-Objective Optimization: Survey and Generalized Test Suite
Jan 04, 2026Dynamic multi-objective optimization (DMOO) has recently attracted increasing interest from both academic researchers and engineering practitioners, as numerous real-world applications that evolve over time can be naturally formulated as dynamic multi-objective optimization problems (DMOPs). This growing trend necessitates advanced benchmarks for the rigorous evaluation of optimization algorithms under realistic conditions. This paper introduces a comprehensive and principled framework for constructing highly realistic and challenging DMOO benchmarks. The proposed framework features several novel components: a generalized formulation that allows the Pareto-optimal Set (PS) to change on hypersurfaces, a mechanism for creating controlled variable contribution imbalances to generate heterogeneous landscapes, and dynamic rotation matrices for inducing time-varying variable interactions and non-separability. Furthermore, we incorporate a temporal perturbation mechanism to simulate irregular environmental changes and propose a generalized time-linkage mechanism that systematically embeds historical solution quality into future problems, thereby capturing critical real-world phenomena such as error accumulation and time-deception. Extensive experimental results validate the effectiveness of the proposed framework, demonstrating its superiority over conventional benchmarks in terms of realism, complexity, and its capability for discriminating state-of-the-art algorithmic performance. This work establishes a new standard for dynamic multi-objective optimization benchmarking, providing a powerful tool for the development and evaluation of next-generation algorithms capable of addressing the complexities of real-world dynamic systems.
Proxy Model-Guided Reinforcement Learning for Client Selection in Federated Recommendation
Aug 14, 2025Federated recommender systems have emerged as a promising privacy-preserving paradigm, enabling personalized recommendation services without exposing users' raw data. By keeping data local and relying on a central server to coordinate training across distributed clients, FedRSs protect user privacy while collaboratively learning global models. However, most existing FedRS frameworks adopt fully random client selection strategy in each training round, overlooking the statistical heterogeneity of user data arising from diverse preferences and behavior patterns, thereby resulting in suboptimal model performance. While some client selection strategies have been proposed in the broader federated learning literature, these methods are typically designed for generic tasks and fail to address the unique challenges of recommendation scenarios, such as expensive contribution evaluation due to the large number of clients, and sparse updates resulting from long-tail item distributions. To bridge this gap, we propose ProxyRL-FRS, a proxy model-guided reinforcement learning framework tailored for client selection in federated recommendation. Specifically, we first introduce ProxyNCF, a dual-branch model deployed on each client, which augments standard Neural Collaborative Filtering with an additional proxy model branch that provides lightweight contribution estimation, thus eliminating the need for expensive per-round local training traditionally required to evaluate a client's contribution. Furthermore, we design a staleness-aware SA reinforcement learning agent that selects clients based on the proxy-estimated contribution, and is guided by a reward function balancing recommendation accuracy and embedding staleness, thereby enriching the update coverage of item embeddings. Experiments conducted on public recommendation datasets demonstrate the effectiveness of ProxyRL-FRS.
PhantomHunter: Detecting Unseen Privately-Tuned LLM-Generated Text via Family-Aware Learning
Jun 18, 2025



With the popularity of large language models (LLMs), undesirable societal problems like misinformation production and academic misconduct have been more severe, making LLM-generated text detection now of unprecedented importance. Although existing methods have made remarkable progress, a new challenge posed by text from privately tuned LLMs remains underexplored. Users could easily possess private LLMs by fine-tuning an open-source one with private corpora, resulting in a significant performance drop of existing detectors in practice. To address this issue, we propose PhantomHunter, an LLM-generated text detector specialized for detecting text from unseen, privately-tuned LLMs. Its family-aware learning framework captures family-level traits shared across the base models and their derivatives, instead of memorizing individual characteristics. Experiments on data from LLaMA, Gemma, and Mistral families show its superiority over 7 baselines and 3 industrial services, with F1 scores of over 96%.
Decomposability-Guaranteed Cooperative Coevolution for Large-Scale Itinerary Planning
Jun 06, 2025Large-scale itinerary planning is a variant of the traveling salesman problem, aiming to determine an optimal path that maximizes the collected points of interest (POIs) scores while minimizing travel time and cost, subject to travel duration constraints. This paper analyzes the decomposability of large-scale itinerary planning, proving that strict decomposability is difficult to satisfy, and introduces a weak decomposability definition based on a necessary condition, deriving the corresponding graph structures that fulfill this property. With decomposability guaranteed, we propose a novel multi-objective cooperative coevolutionary algorithm for large-scale itinerary planning, addressing the challenges of component imbalance and interactions. Specifically, we design a dynamic decomposition strategy based on the normalized fitness within each component, define optimization potential considering component scale and contribution, and develop a computational resource allocation strategy. Finally, we evaluate the proposed algorithm on a set of real-world datasets. Comparative experiments with state-of-the-art multi-objective itinerary planning algorithms demonstrate the superiority of our approach, with performance advantages increasing as the problem scale grows.
Multi-Agent Coordination across Diverse Applications: A Survey
Feb 21, 2025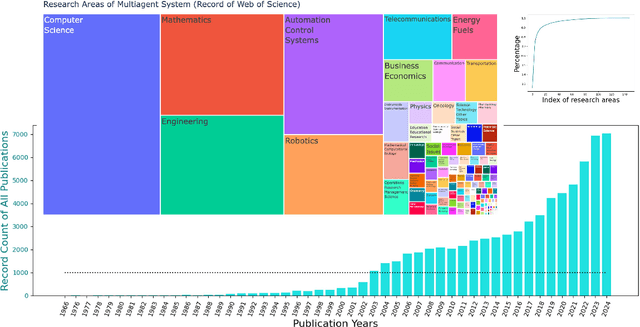
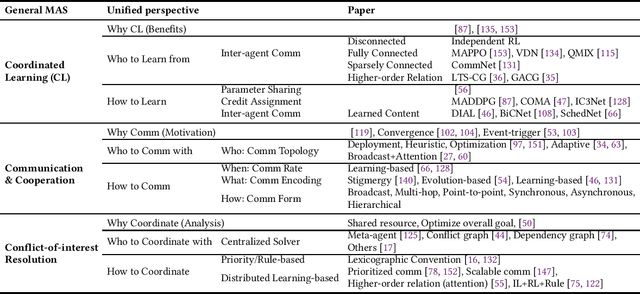
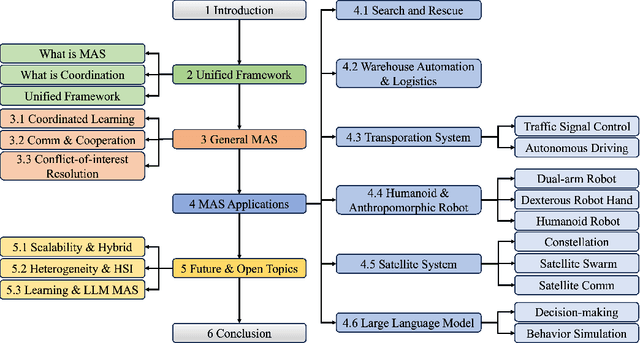
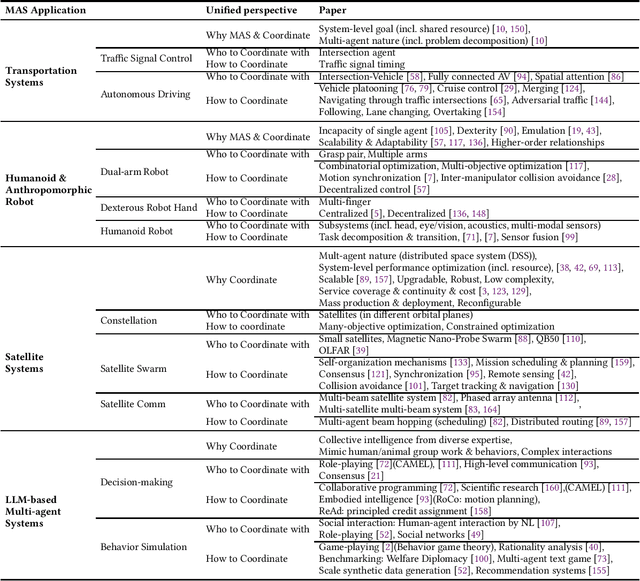
Multi-agent coordination studies the underlying mechanism enabling the trending spread of diverse multi-agent systems (MAS) and has received increasing attention, driven by the expansion of emerging applications and rapid AI advances. This survey outlines the current state of coordination research across applications through a unified understanding that answers four fundamental coordination questions: (1) what is coordination; (2) why coordination; (3) who to coordinate with; and (4) how to coordinate. Our purpose is to explore existing ideas and expertise in coordination and their connections across diverse applications, while identifying and highlighting emerging and promising research directions. First, general coordination problems that are essential to varied applications are identified and analyzed. Second, a number of MAS applications are surveyed, ranging from widely studied domains, e.g., search and rescue, warehouse automation and logistics, and transportation systems, to emerging fields including humanoid and anthropomorphic robots, satellite systems, and large language models (LLMs). Finally, open challenges about the scalability, heterogeneity, and learning mechanisms of MAS are analyzed and discussed. In particular, we identify the hybridization of hierarchical and decentralized coordination, human-MAS coordination, and LLM-based MAS as promising future directions.
Exploring Accuracy-Fairness Trade-off in Large Language Models
Nov 21, 2024



Large Language Models (LLMs) have made significant strides in the field of artificial intelligence, showcasing their ability to interact with humans and influence human cognition through information dissemination. However, recent studies have brought to light instances of bias inherent within these LLMs, presenting a critical issue that demands attention. In our research, we delve deeper into the intricate challenge of harmonising accuracy and fairness in the enhancement of LLMs. While improving accuracy can indeed enhance overall LLM performance, it often occurs at the expense of fairness. Overemphasising optimisation of one metric invariably leads to a significant degradation of the other. This underscores the necessity of taking into account multiple considerations during the design and optimisation phases of LLMs. Therefore, we advocate for reformulating the LLM training process as a multi-objective learning task. Our investigation reveals that multi-objective evolutionary learning (MOEL) methodologies offer promising avenues for tackling this challenge. Our MOEL framework enables the simultaneous optimisation of both accuracy and fairness metrics, resulting in a Pareto-optimal set of LLMs. In summary, our study sheds valuable lights on the delicate equilibrium between accuracy and fairness within LLMs, which is increasingly significant for their real-world applications. By harnessing MOEL, we present a promising pathway towards fairer and more efficacious AI technologies.