 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhantomHunter: Detecting Unseen Privately-Tuned LLM-Generated Text via Family-Aware Learning
Jun 18, 2025



With the popularity of large language models (LLMs), undesirable societal problems like misinformation production and academic misconduct have been more severe, making LLM-generated text detection now of unprecedented importance. Although existing methods have made remarkable progress, a new challenge posed by text from privately tuned LLMs remains underexplored. Users could easily possess private LLMs by fine-tuning an open-source one with private corpora, resulting in a significant performance drop of existing detectors in practice. To address this issue, we propose PhantomHunter, an LLM-generated text detector specialized for detecting text from unseen, privately-tuned LLMs. Its family-aware learning framework captures family-level traits shared across the base models and their derivatives, instead of memorizing individual characteristics. Experiments on data from LLaMA, Gemma, and Mistral families show its superiority over 7 baselines and 3 industrial services, with F1 scores of over 96%.
SEA: Sentence Encoder Assembly for Video Retrieval by Textual Queries
Nov 24, 2020
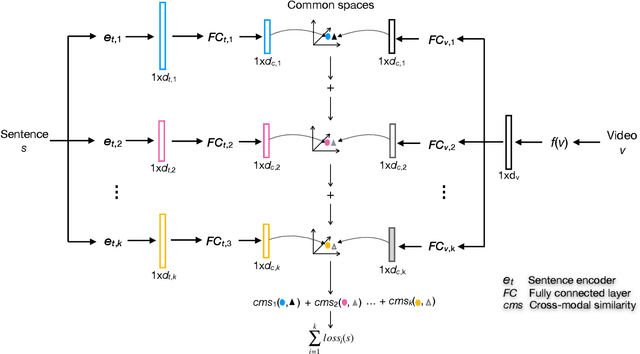

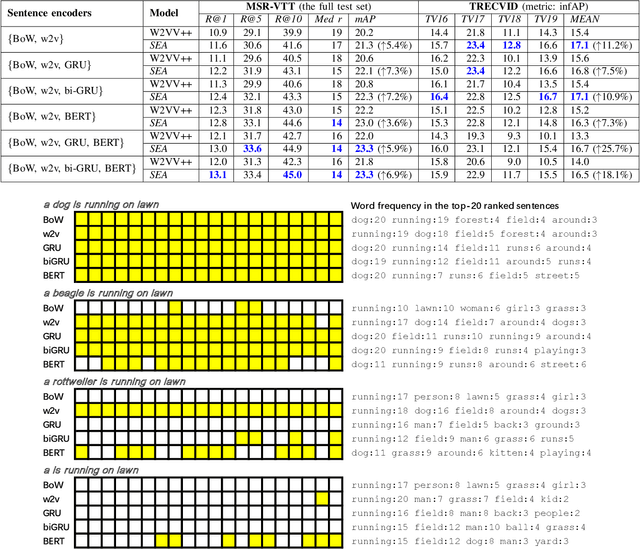
Retrieving unlabeled videos by textual queries, known as Ad-hoc Video Search (AVS), is a core theme in multimedia data management and retrieval. The success of AVS counts on cross-modal representation learning that encodes both query sentences and videos into common spaces for semantic similarity computation. Inspired by the initial success of previously few works in combining multiple sentence encoders, this paper takes a step forward by developing a new and general method for effectively exploiting diverse sentence encoders. The novelty of the proposed method, which we term Sentence Encoder Assembly (SEA), is two-fold. First, different from prior art that use only a single common space, SEA supports text-video matching in multiple encoder-specific common spaces. Such a property prevents the matching from being dominated by a specific encoder that produces an encoding vector much longer than other encoders. Second, in order to explore complementarities among the individual common spaces, we propose multi-space multi-loss learning. As extensive experiments on four benchmarks (MSR-VTT, TRECVID AVS 2016-2019, TGIF and MSVD) show, SEA surpasses the state-of-the-art. In addition, SEA is extremely ease to implement. All this makes SEA an appealing solution for AVS and promising for continuously advancing the task by harvesting new sentence encoders.
Hybrid Space Learning for Language-based Video Retrieval
Sep 10, 2020
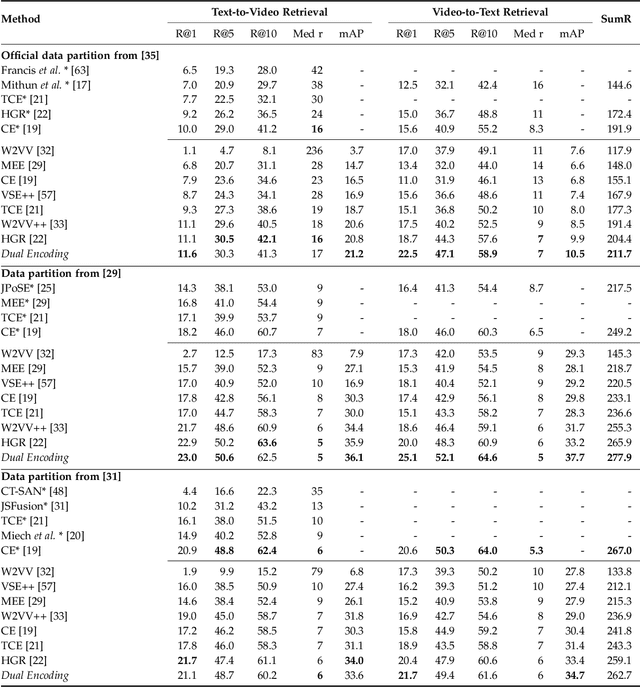
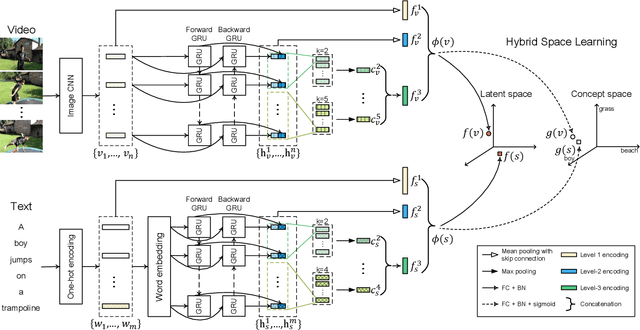
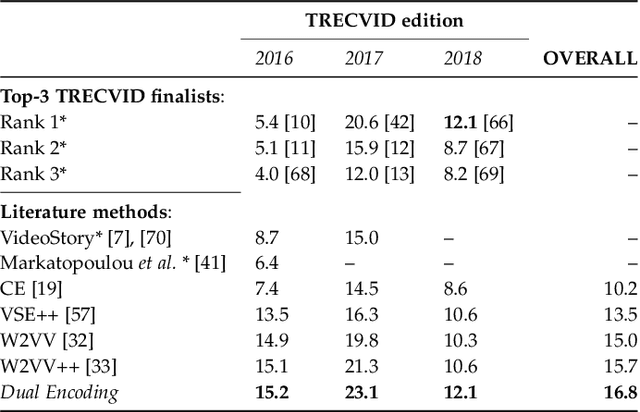
This paper attacks the challenging problem of video retrieval by text. In such a retrieval paradigm, an end user searches for unlabeled videos by ad-hoc queries described exclusively in the form of a natural-language sentence, with no visual example provided. Given videos as sequences of frames and queries as sequences of words, an effective sequence-to-sequence cross-modal matching is crucial. To that end, the two modalities need to be first encoded into real-valued vectors and then projected into a common space. In this paper we achieve this by proposing a dual deep encoding network that encodes videos and queries into powerful dense representations of their own. Our novelty is two-fold. First, different from prior art that resorts to a specific single-level encoder, the proposed network performs multi-level encoding that represents the rich content of both modalities in a coarse-to-fine fashion. Second, different from a conventional common space learning algorithm which is either concept based or latent space based, we introduce hybrid space learning which combines the high performance of the latent space and the good interpretability of the concept space. Dual encoding is conceptually simple, practically effective and end-to-end trained with hybrid space learning. Extensive experiments on four challenging video datasets show the viability of the new method.
Feature Re-Learning with Data Augmentation for Video Relevance Prediction
Apr 08, 2020

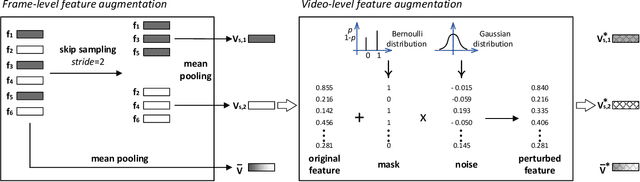
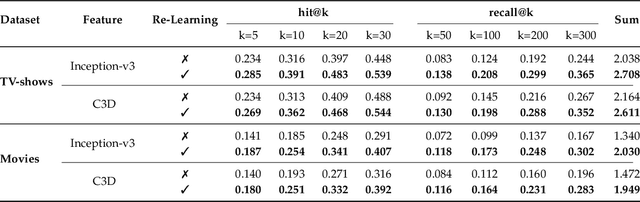
Predicting the relevance between two given videos with respect to their visual content is a key component for content-based video recommendation and retrieval. Thanks to the increasing availability of pre-trained image and video convolutional neural network models, deep visual features are widely used for video content representation. However, as how two videos are relevant is task-dependent, such off-the-shelf features are not always optimal for all tasks. Moreover, due to varied concerns including copyright, privacy and security, one might have access to only pre-computed video features rather than original videos. We propose in this paper feature re-learning for improving video relevance prediction, with no need of revisiting the original video content. In particular, re-learning is realized by projecting a given deep feature into a new space by an affine transformation. We optimize the re-learning process by a novel negative-enhanced triplet ranking loss. In order to generate more training data, we propose a new data augmentation strategy which works directly on frame-level and video-level features. Extensive experiments in the context of the Hulu Content-based Video Relevance Prediction Challenge 2018 justify the effectiveness of the proposed method and its state-of-the-art performance for content-based video relevance prediction.
Dual Dense Encoding for Zero-Example Video Retrieval
Sep 17, 2018
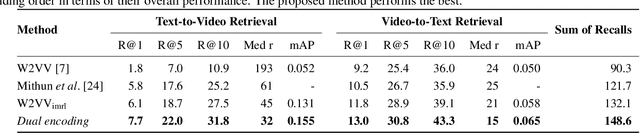
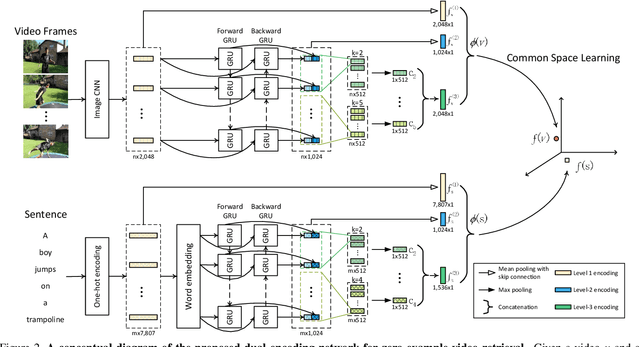
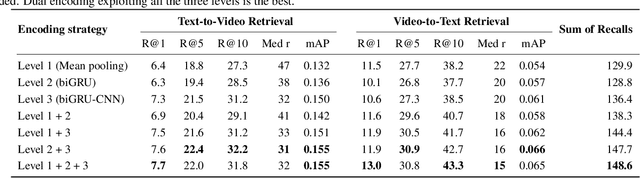
This paper attacks the challenging problem of zero-example video retrieval. In such a retrieval paradigm, an end user searches for unlabeled videos by ad-hoc queries described in natural language text with no visual example provided. The majority of existing methods are concept based, extracting relevant concepts from queries and videos and accordingly establishing associations between the two modalities. In contrast, this paper follows a novel trend of concept-free, deep learning based encoding. To that end, we propose a dual deep encoding network that works on both video and query sides. The network can be flexibly coupled with an existing common space learning module for video-text similarity computation. As experiments on three benchmarks, i.e., MSR-VTT, TRECVID 2016 and 2017 Ad-hoc Video Search show, the proposed method establishes a new state-of-the-art for zero-example video retrieval.
COCO-CN for Cross-Lingual Image Tagging, Captioning and Retrieval
May 22, 2018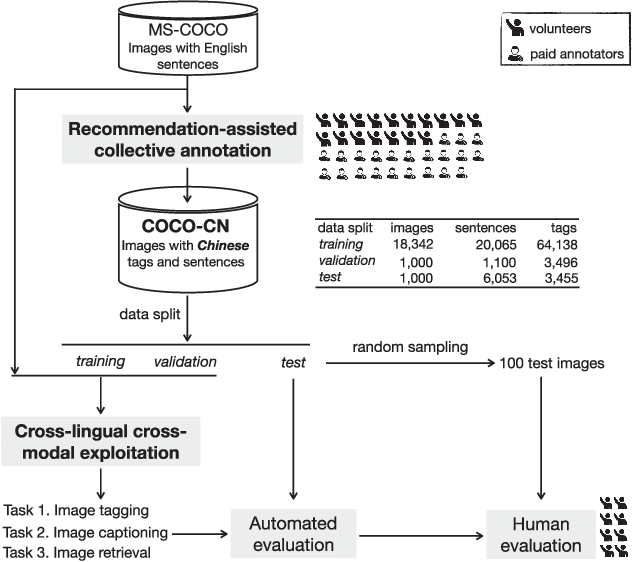
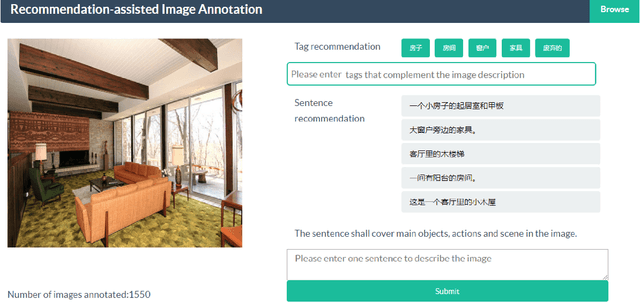
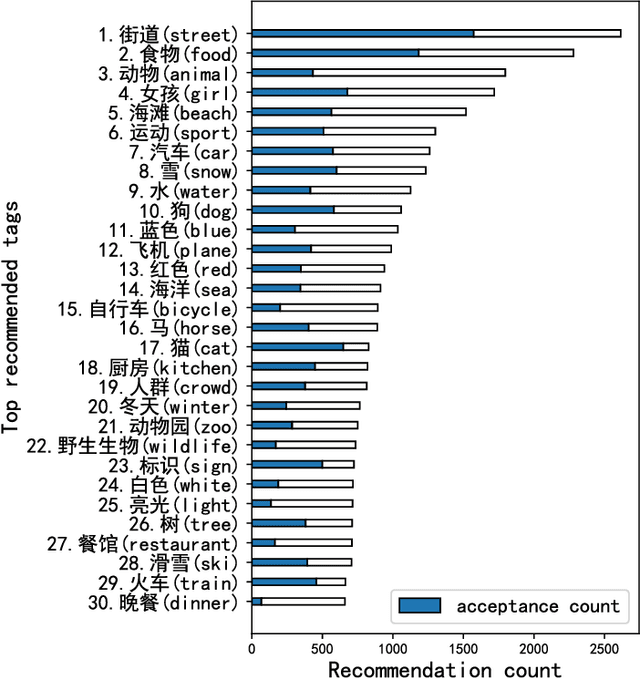
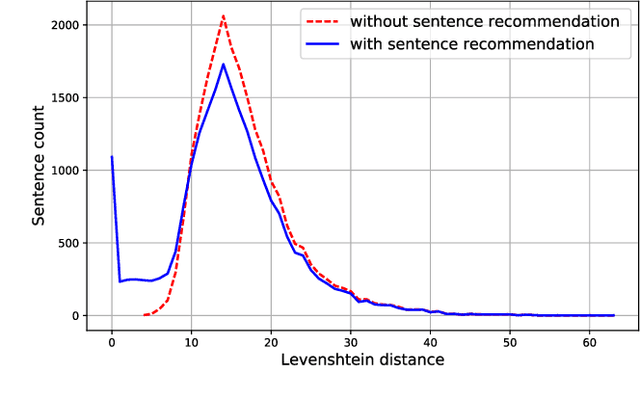
This paper contributes to cross-lingual image annotation and retrieval in terms of data and methods. We propose COCO-CN, a novel dataset enriching MS-COCO with manually written Chinese sentences and tags. For more effective annotation acquisition, we develop a recommendation-assisted collective annotation system, automatically providing an annotator with several tags and sentences deemed to be relevant with respect to the pictorial content. Having 20,342 images annotated with 27,218 Chinese sentences and 70,993 tags, COCO-CN is currently the largest Chinese-English dataset applicable for cross-lingual image tagging, captioning and retrieval. We develop methods per task for effectively learning from cross-lingual resources. Extensive experiments on the multiple tasks justify the viability of our dataset and methods.