 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Space Learning for Language-based Video Retrieval
Paper and Code

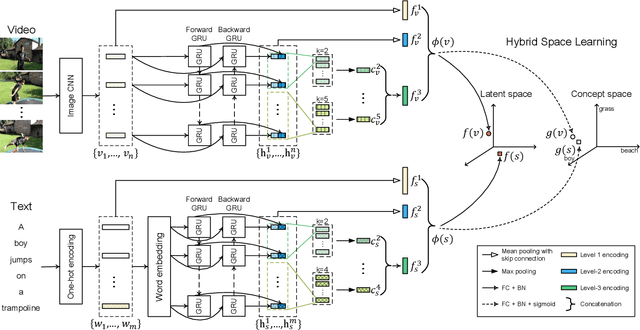
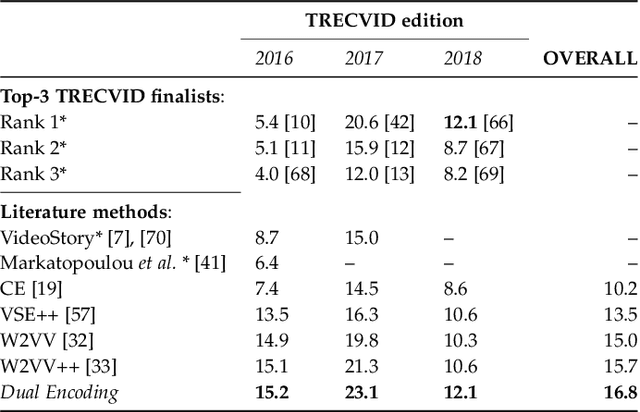
This paper attacks the challenging problem of video retrieval by text. In such a retrieval paradigm, an end user searches for unlabeled videos by ad-hoc queries described exclusively in the form of a natural-language sentence, with no visual example provided. Given videos as sequences of frames and queries as sequences of words, an effective sequence-to-sequence cross-modal matching is crucial. To that end, the two modalities need to be first encoded into real-valued vectors and then projected into a common space. In this paper we achieve this by proposing a dual deep encoding network that encodes videos and queries into powerful dense representations of their own. Our novelty is two-fold. First, different from prior art that resorts to a specific single-level encoder, the proposed network performs multi-level encoding that represents the rich content of both modalities in a coarse-to-fine fashion. Second, different from a conventional common space learning algorithm which is either concept based or latent space based, we introduce hybrid space learning which combines the high performance of the latent space and the good interpretability of the concept space. Dual encoding is conceptually simple, practically effective and end-to-end trained with hybrid space learning. Extensive experiments on four challenging video datasets show the viability of the new method.