 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOCO-CN for Cross-Lingual Image Tagging, Captioning and Retrieval
Paper and Code
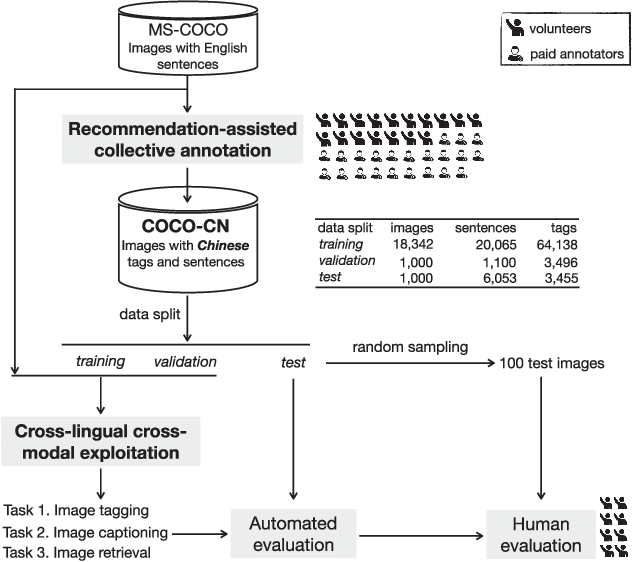
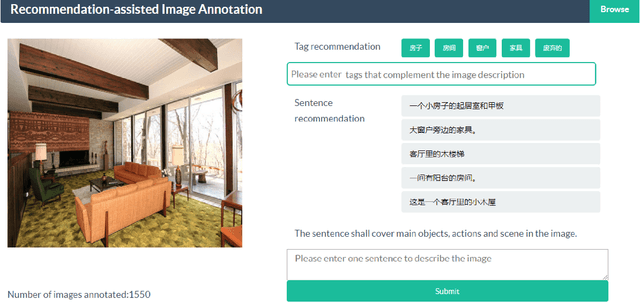
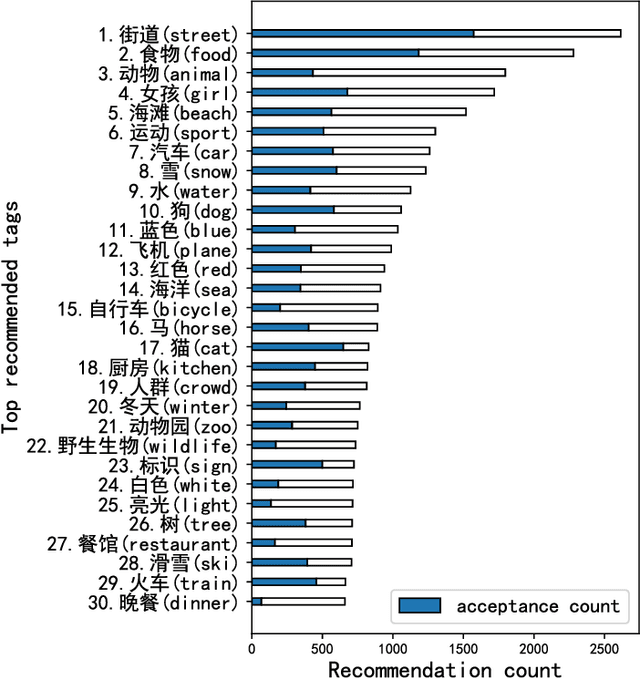
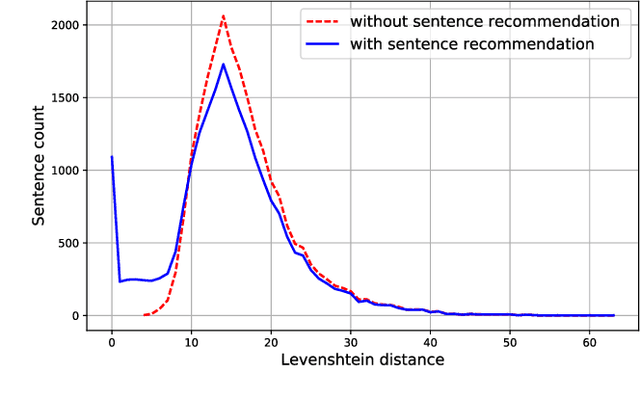
This paper contributes to cross-lingual image annotation and retrieval in terms of data and methods. We propose COCO-CN, a novel dataset enriching MS-COCO with manually written Chinese sentences and tags. For more effective annotation acquisition, we develop a recommendation-assisted collective annotation system, automatically providing an annotator with several tags and sentences deemed to be relevant with respect to the pictorial content. Having 20,342 images annotated with 27,218 Chinese sentences and 70,993 tags, COCO-CN is currently the largest Chinese-English dataset applicable for cross-lingual image tagging, captioning and retrieval. We develop methods per task for effectively learning from cross-lingual resources. Extensive experiments on the multiple tasks justify the viability of our dataset and methods.