 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Disentangle GAN Fingerprint for Fake Image Attribution
Jun 16, 2021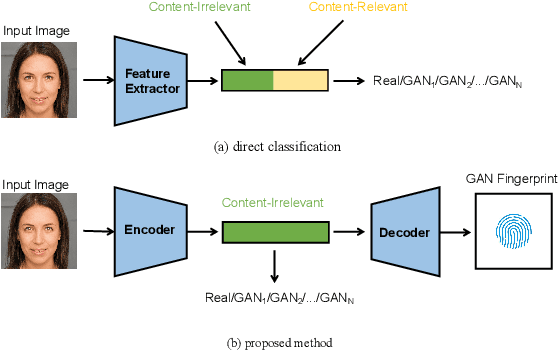
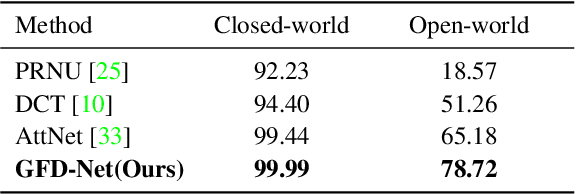
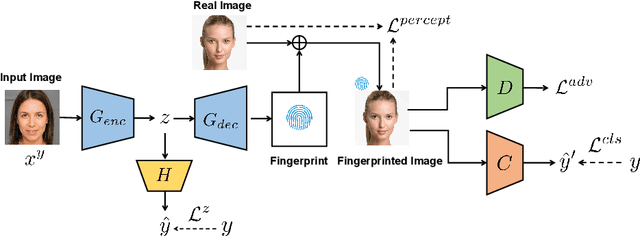

Rapid pace of generative models has brought about new threats to visual forensics such as malicious personation and digital copyright infringement, which promotes works on fake image attribution. Existing works on fake image attribution mainly rely on a direct classification framework. Without additional supervision, the extracted features could include many content-relevant components and generalize poorly. Meanwhile, how to obtain an interpretable GAN fingerprint to explain the decision remains an open question. Adopting a multi-task framework, we propose a GAN Fingerprint Disentangling Network (GFD-Net) to simultaneously disentangle the fingerprint from GAN-generated images and produce a content-irrelevant representation for fake image attribution. A series of constraints are provided to guarantee the stability and discriminability of the fingerprint, which in turn helps content-irrelevant feature extraction. Further, we perform comprehensive analysis on GAN fingerprint, providing some clues about the properties of GAN fingerprint and which factors dominate the fingerprint in GAN architecture. Experiments show that our GFD-Net achieves superior fake image attribution performance in both closed-world and open-world testing. We also apply our method in binary fake image detection and exhibit a significant generalization ability on unseen generators.
Image Manipulation Detection by Multi-View Multi-Scale Supervision
Apr 14, 2021
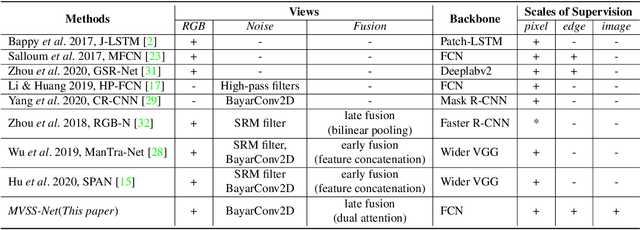
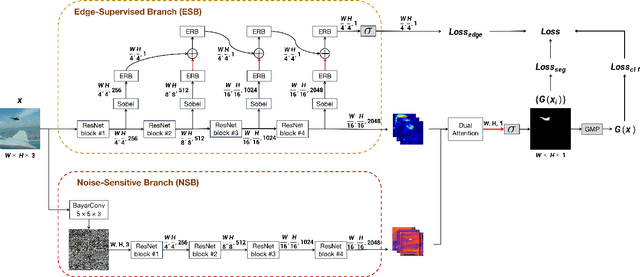
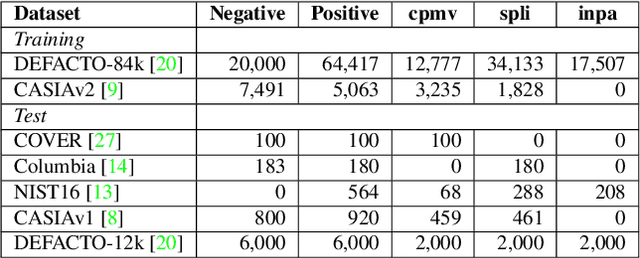
The key challenge of image manipulation detection is how to learn generalizable features that are sensitive to manipulations in novel data, whilst specific to prevent false alarms on authentic images. Current research emphasizes the sensitivity, with the specificity overlooked. In this paper we address both aspects by multi-view feature learning and multi-scale supervision. By exploiting noise distribution and boundary artifact surrounding tampered regions, the former aims to learn semantic-agnostic and thus more generalizable features. The latter allows us to learn from authentic images which are nontrivial to taken into account by current semantic segmentation network based methods. Our thoughts are realized by a new network which we term MVSS-Net. Extensive experiments on five benchmark sets justify the viability of MVSS-Net for both pixel-level and image-level manipulation detection.
SEA: Sentence Encoder Assembly for Video Retrieval by Textual Queries
Nov 24, 2020
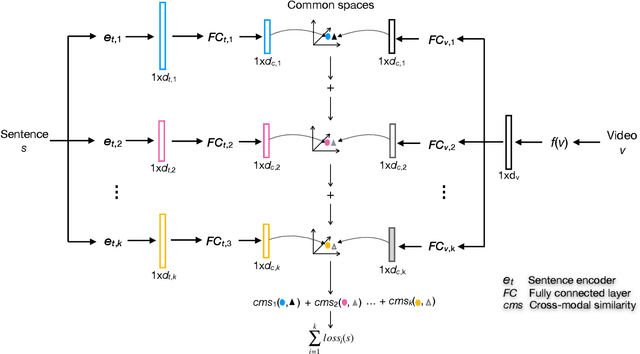

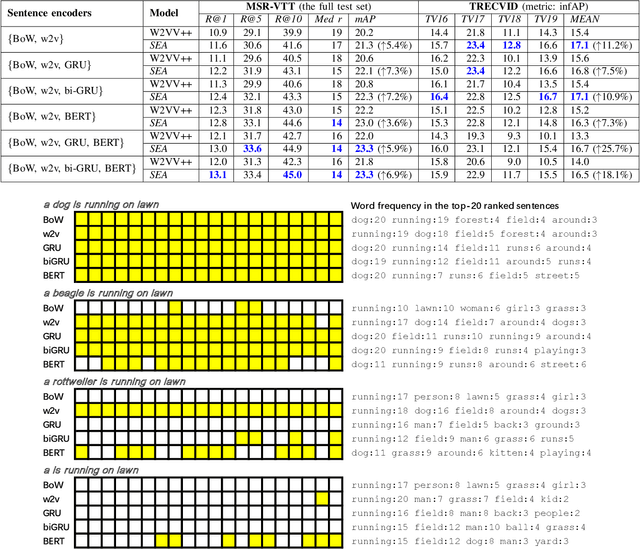
Retrieving unlabeled videos by textual queries, known as Ad-hoc Video Search (AVS), is a core theme in multimedia data management and retrieval. The success of AVS counts on cross-modal representation learning that encodes both query sentences and videos into common spaces for semantic similarity computation. Inspired by the initial success of previously few works in combining multiple sentence encoders, this paper takes a step forward by developing a new and general method for effectively exploiting diverse sentence encoders. The novelty of the proposed method, which we term Sentence Encoder Assembly (SEA), is two-fold. First, different from prior art that use only a single common space, SEA supports text-video matching in multiple encoder-specific common spaces. Such a property prevents the matching from being dominated by a specific encoder that produces an encoding vector much longer than other encoders. Second, in order to explore complementarities among the individual common spaces, we propose multi-space multi-loss learning. As extensive experiments on four benchmarks (MSR-VTT, TRECVID AVS 2016-2019, TGIF and MSVD) show, SEA surpasses the state-of-the-art. In addition, SEA is extremely ease to implement. All this makes SEA an appealing solution for AVS and promising for continuously advancing the task by harvesting new sentence encoders.