 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Value-Based Reinforcement Learning for Large Language Models
Mar 24, 2026Improving data utilization efficiency is critical for scaling reinforcement learning (RL) for long-horizon tasks where generating trajectories is expensive. However, the dominant RL methods for LLMs are largely on-policy: they update each batch of data only once, discard it, and then collect fresh samples, resulting in poor sample efficiency. In this work, we explore an alternative value-based RL framework for LLMs that naturally enables off-policy learning. We propose ReVal, a Bellman-update-based method that combines stepwise signals capturing internal consistency with trajectory-level signals derived from outcome verification. ReVal naturally supports replay-buffer-based training, allowing efficient reuse of past trajectories. Experiments on standard mathematical reasoning benchmarks show that ReVal not only converges faster but also outperforms GRPO in final performance. On DeepSeek-R1-Distill-1.5B, ReVal improves training efficiency and achieves improvement of 2.7% in AIME24 and 4.5% in out-of-domain benchmark GPQA over GRPO. These results suggest that value-based RL is a practical alternative to policy-based methods for LLM training.
Bridging Formal Language with Chain-of-Thought Reasoning to Geometry Problem Solving
Aug 12, 2025
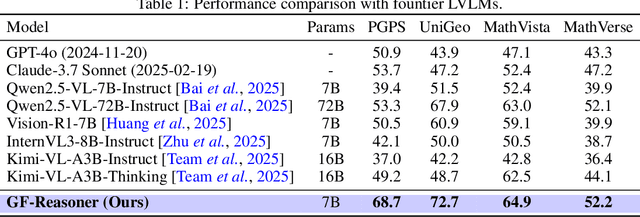
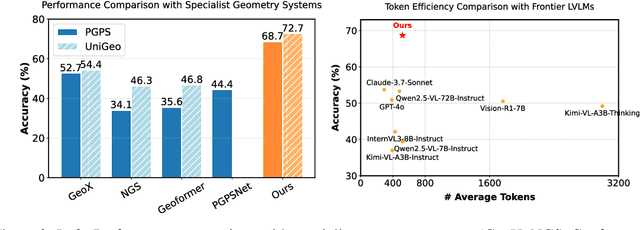
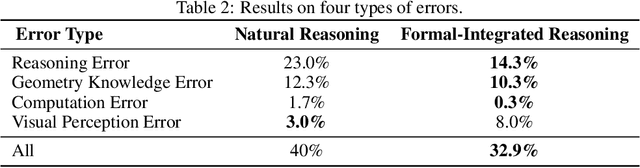
Large vision language models exhibit notable limitations on Geometry Problem Solving (GPS) because of their unreliable diagram interpretation and pure natural-language reasoning. A recent line of work mitigates this by using symbolic solvers: the model directly generates a formal program that a geometry solver can execute. However, this direct program generation lacks intermediate reasoning, making the decision process opaque and prone to errors. In this work, we explore a new approach that integrates Chain-of-Thought (CoT) with formal language. The model interleaves natural language reasoning with incremental emission of solver-executable code, producing a hybrid reasoning trace in which critical derivations are expressed in formal language. To teach this behavior at scale, we combine (1) supervised fine-tuning on an 11K newly developed synthetic dataset with interleaved natural language reasoning and automatic formalization, and (2) solver-in-the-loop reinforcement learning that jointly optimizes both the CoT narrative and the resulting program through outcome-based rewards. Built on Qwen2.5-VL-7B, our new model, named GF-Reasoner, achieves up to 15% accuracy improvements on standard GPS benchmarks, surpassing both 7B-scale peers and the much larger model Qwen2.5-VL-72B. By exploiting high-order geometric knowledge and offloading symbolic computation to the solver, the generated reasoning traces are noticeably shorter and cleaner. Furthermore, we present a comprehensive analysis of method design choices (e.g., reasoning paradigms, data synthesis, training epochs, etc.), providing actionable insights for future research.
Pruning for Robust Concept Erasing in Diffusion Models
May 26, 2024


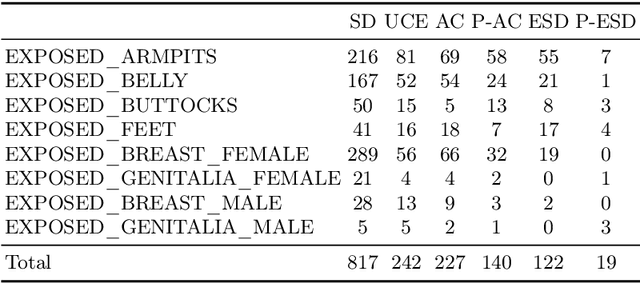
Despite the impressive capabilities of generating images, text-to-image diffusion models are susceptible to producing undesirable outputs such as NSFW content and copyrighted artworks. To address this issue, recent studies have focused on fine-tuning model parameters to erase problematic concepts. However, existing methods exhibit a major flaw in robustness, as fine-tuned models often reproduce the undesirable outputs when faced with cleverly crafted prompts. This reveals a fundamental limitation in the current approaches and may raise risks for the deployment of diffusion models in the open world. To address this gap, we locate the concept-correlated neurons and find that these neurons show high sensitivity to adversarial prompts, thus could be deactivated when erasing and reactivated again under attacks. To improve the robustness, we introduce a new pruning-based strategy for concept erasing. Our method selectively prunes critical parameters associated with the concepts targeted for removal, thereby reducing the sensitivity of concept-related neurons. Our method can be easily integrated with existing concept-erasing techniques, offering a robust improvement against adversarial inputs. Experimental results show a significant enhancement in our model's ability to resist adversarial inputs, achieving nearly a 40% improvement in erasing the NSFW content and a 30% improvement in erasing artwork style.
Fingerprints of Generative Models in the Frequency Domain
Jul 29, 2023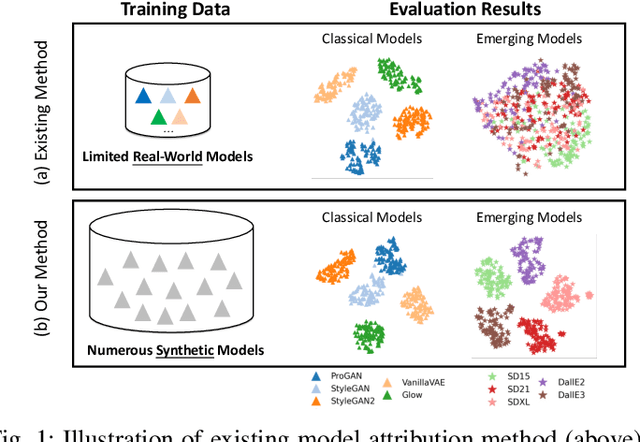



It is verified in existing works that CNN-based generative models leave unique fingerprints on generated images. There is a lack of analysis about how they are formed in generative models. Interpreting network components in the frequency domain, we derive sources for frequency distribution and grid-like pattern discrepancies exhibited on the spectrum. These insights are leveraged to develop low-cost synthetic models, which generate images emulating the frequency patterns observed in real generative models. The resulting fingerprint extractor pre-trained on synthetic data shows superior transferability in verifying, identifying, and analyzing the relationship of real CNN-based generative models such as GAN, VAE, Flow, and diffusion.
Progressive Open Space Expansion for Open-Set Model Attribution
Mar 13, 2023Despite the remarkable progress in generative technology, the Janus-faced issues of intellectual property protection and malicious content supervision have arisen. Efforts have been paid to manage synthetic images by attributing them to a set of potential source models. However, the closed-set classification setting limits the application in real-world scenarios for handling contents generated by arbitrary models. In this study, we focus on a challenging task, namely Open-Set Model Attribution (OSMA), to simultaneously attribute images to known models and identify those from unknown ones. Compared to existing open-set recognition (OSR) tasks focusing on semantic novelty, OSMA is more challenging as the distinction between images from known and unknown models may only lie in visually imperceptible traces. To this end, we propose a Progressive Open Space Expansion (POSE) solution, which simulates open-set samples that maintain the same semantics as closed-set samples but embedded with different imperceptible traces. Guided by a diversity constraint, the open space is simulated progressively by a set of lightweight augmentation models. We consider three real-world scenarios and construct an OSMA benchmark dataset, including unknown models trained with different random seeds, architectures, and datasets from known ones. Extensive experiments on the dataset demonstrate POSE is superior to both existing model attribution methods and off-the-shelf OSR methods.
Deepfake Network Architecture Attribution
Mar 14, 2022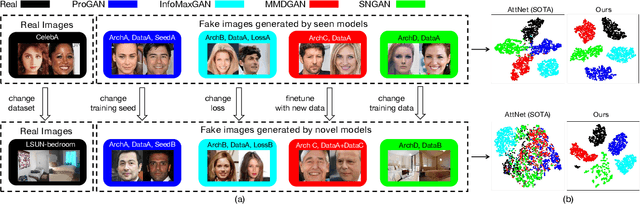
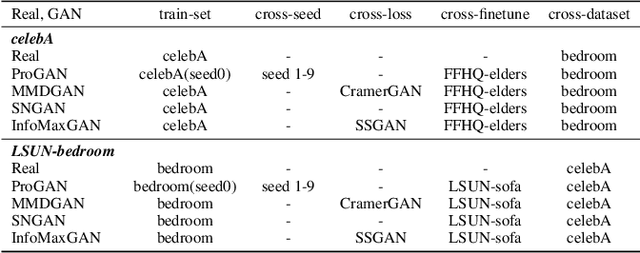

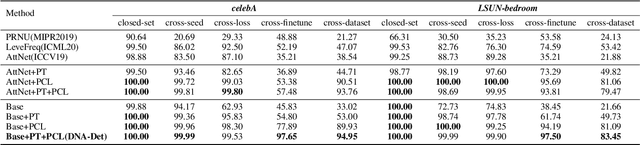
With the rapid progress of generation technology, it has become necessary to attribute the origin of fake images. Existing works on fake image attribution perform multi-class classification on several Generative Adversarial Network (GAN) models and obtain high accuracies. While encouraging, these works are restricted to model-level attribution, only capable of handling images generated by seen models with a specific seed, loss and dataset, which is limited in real-world scenarios when fake images may be generated by privately trained models. This motivates us to ask whether it is possible to attribute fake images to the source models' architectures even if they are finetuned or retrained under different configurations. In this work, we present the first study on Deepfake Network Architecture Attribution to attribute fake images on architecture-level. Based on an observation that GAN architecture is likely to leave globally consistent fingerprints while traces left by model weights vary in different regions, we provide a simple yet effective solution named DNA-Det for this problem. Extensive experiments on multiple cross-test setups and a large-scale dataset demonstrate the effectiveness of DNA-Det.
Learning to Disentangle GAN Fingerprint for Fake Image Attribution
Jun 16, 2021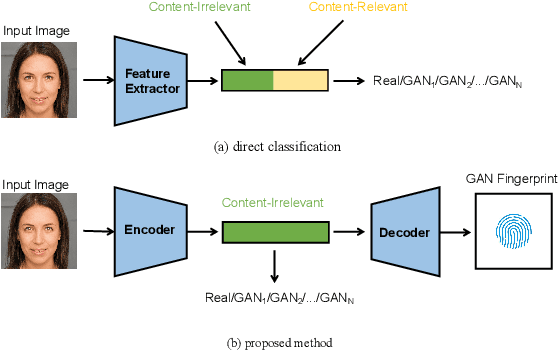
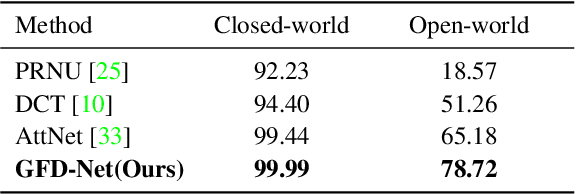
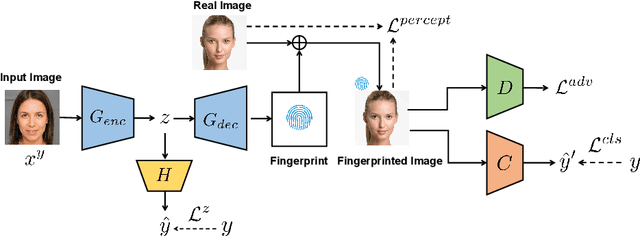

Rapid pace of generative models has brought about new threats to visual forensics such as malicious personation and digital copyright infringement, which promotes works on fake image attribution. Existing works on fake image attribution mainly rely on a direct classification framework. Without additional supervision, the extracted features could include many content-relevant components and generalize poorly. Meanwhile, how to obtain an interpretable GAN fingerprint to explain the decision remains an open question. Adopting a multi-task framework, we propose a GAN Fingerprint Disentangling Network (GFD-Net) to simultaneously disentangle the fingerprint from GAN-generated images and produce a content-irrelevant representation for fake image attribution. A series of constraints are provided to guarantee the stability and discriminability of the fingerprint, which in turn helps content-irrelevant feature extraction. Further, we perform comprehensive analysis on GAN fingerprint, providing some clues about the properties of GAN fingerprint and which factors dominate the fingerprint in GAN architecture. Experiments show that our GFD-Net achieves superior fake image attribution performance in both closed-world and open-world testing. We also apply our method in binary fake image detection and exhibit a significant generalization ability on unseen generators.