 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Intelligence Agent
Apr 07, 2026Deep research agents (DRAs) integrate LLM reasoning with external tools. Memory systems enable DRAs to leverage historical experiences, which are essential for efficient reasoning and autonomous evolution. Existing methods rely on retrieving similar trajectories from memory to aid reasoning, while suffering from key limitations of ineffective memory evolution and increasing storage and retrieval costs. To address these problems, we propose a novel Memory Intelligence Agent (MIA) framework, consisting of a Manager-Planner-Executor architecture. Memory Manager is a non-parametric memory system that can store compressed historical search trajectories. Planner is a parametric memory agent that can produce search plans for questions. Executor is another agent that can search and analyze information guided by the search plan. To build the MIA framework, we first adopt an alternating reinforcement learning paradigm to enhance cooperation between the Planner and the Executor. Furthermore, we enable the Planner to continuously evolve during test-time learning, with updates performed on-the-fly alongside inference without interrupting the reasoning process. Additionally, we establish a bidirectional conversion loop between parametric and non-parametric memories to achieve efficient memory evolution. Finally, we incorporate a reflection and an unsupervised judgment mechanisms to boost reasoning and self-evolution in the open world. Extensive experiments across eleven benchmarks demonstrate the superiority of MIA.
Efficiently Aligning Draft Models via Parameter- and Data-Efficient Adaptation
Mar 10, 2026Speculative decoding accelerates LLM inference but suffers from performance degradation when target models are fine-tuned for specific domains. A naive solution is to retrain draft models for every target model, which is costly and inefficient. To address this, we introduce a parameter- and data-efficient framework named Efficient Draft Adaptation, abbreviated as EDA, for efficiently adapting draft models. EDA introduces three innovations: (1) a decoupled architecture that utilizes shared and private components to model the shared and target-specific output distributions separately, enabling parameter-efficient adaptation by updating only the lightweight private component;(2) a data regeneration strategy that utilizes the fine-tuned target model to regenerate training data, thereby improving the alignment between training and speculative decoding, leading to higher average acceptance length;(3) a sample selection mechanism that prioritizes high-value data for efficient adaptation. Our experiments show that EDA effectively restores speculative performance on fine-tuned models, achieving superior average acceptance lengths with significantly reduced training costs compared to full retraining. Code is available at https://github.com/Lyn-Lucy/Efficient-Draft-Adaptation.
ORGEval: Graph-Theoretic Evaluation of LLMs in Optimization Modeling
Oct 31, 2025Formulating optimization problems for industrial applications demands significant manual effort and domain expertise. While Large Language Models (LLMs) show promise in automating this process, evaluating their performance remains difficult due to the absence of robust metrics. Existing solver-based approaches often face inconsistency, infeasibility issues, and high computational costs. To address these issues, we propose ORGEval, a graph-theoretic evaluation framework for assessing LLMs' capabilities in formulating linear and mixed-integer linear programs. ORGEval represents optimization models as graphs, reducing equivalence detection to graph isomorphism testing. We identify and prove a sufficient condition, when the tested graphs are symmetric decomposable (SD), under which the Weisfeiler-Lehman (WL) test is guaranteed to correctly detect isomorphism. Building on this, ORGEval integrates a tailored variant of the WL-test with an SD detection algorithm to evaluate model equivalence. By focusing on structural equivalence rather than instance-level configurations, ORGEval is robust to numerical variations. Experimental results show that our method can successfully detect model equivalence and produce 100\% consistent results across random parameter configurations, while significantly outperforming solver-based methods in runtime, especially on difficult problems. Leveraging ORGEval, we construct the Bench4Opt dataset and benchmark state-of-the-art LLMs on optimization modeling. Our results reveal that although optimization modeling remains challenging for all LLMs, DeepSeek-V3 and Claude-Opus-4 achieve the highest accuracies under direct prompting, outperforming even leading reasoning models.
Bridging Formal Language with Chain-of-Thought Reasoning to Geometry Problem Solving
Aug 12, 2025
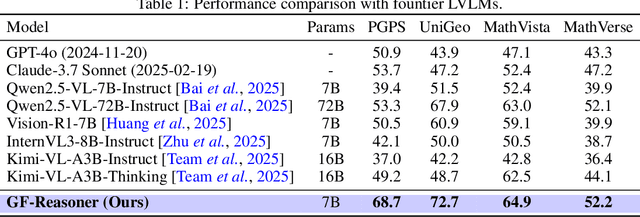
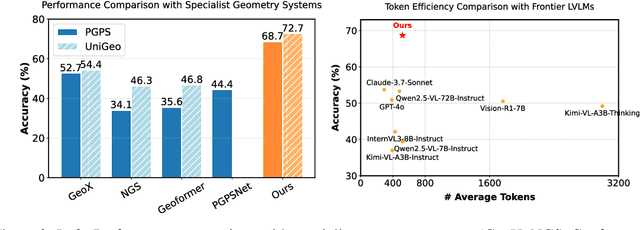
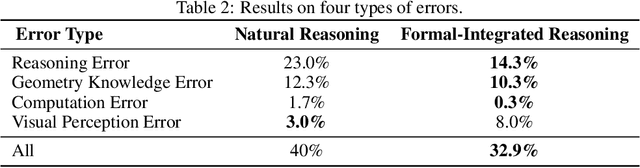
Large vision language models exhibit notable limitations on Geometry Problem Solving (GPS) because of their unreliable diagram interpretation and pure natural-language reasoning. A recent line of work mitigates this by using symbolic solvers: the model directly generates a formal program that a geometry solver can execute. However, this direct program generation lacks intermediate reasoning, making the decision process opaque and prone to errors. In this work, we explore a new approach that integrates Chain-of-Thought (CoT) with formal language. The model interleaves natural language reasoning with incremental emission of solver-executable code, producing a hybrid reasoning trace in which critical derivations are expressed in formal language. To teach this behavior at scale, we combine (1) supervised fine-tuning on an 11K newly developed synthetic dataset with interleaved natural language reasoning and automatic formalization, and (2) solver-in-the-loop reinforcement learning that jointly optimizes both the CoT narrative and the resulting program through outcome-based rewards. Built on Qwen2.5-VL-7B, our new model, named GF-Reasoner, achieves up to 15% accuracy improvements on standard GPS benchmarks, surpassing both 7B-scale peers and the much larger model Qwen2.5-VL-72B. By exploiting high-order geometric knowledge and offloading symbolic computation to the solver, the generated reasoning traces are noticeably shorter and cleaner. Furthermore, we present a comprehensive analysis of method design choices (e.g., reasoning paradigms, data synthesis, training epochs, etc.), providing actionable insights for future research.
Speculative Decoding Reimagined for Multimodal Large Language Models
May 20, 2025This paper introduces Multimodal Speculative Decoding (MSD) to accelerate Multimodal Large Language Models (MLLMs) inference. Speculative decoding has been shown to accelerate Large Language Models (LLMs) without sacrificing accuracy. However, current speculative decoding methods for MLLMs fail to achieve the same speedup as they do for LLMs. To address this, we reimagine speculative decoding specifically for MLLMs. Our analysis of MLLM characteristics reveals two key design principles for MSD: (1) Text and visual tokens have fundamentally different characteristics and need to be processed separately during drafting. (2) Both language modeling ability and visual perception capability are crucial for the draft model. For the first principle, MSD decouples text and visual tokens in the draft model, allowing each to be handled based on its own characteristics. For the second principle, MSD uses a two-stage training strategy: In stage one, the draft model is trained on text-only instruction-tuning datasets to improve its language modeling ability. In stage two, MSD gradually introduces multimodal data to enhance the visual perception capability of the draft model. Experiments show that MSD boosts inference speed by up to $2.29\times$ for LLaVA-1.5-7B and up to $2.46\times$ for LLaVA-1.5-13B on multimodal benchmarks, demonstrating its effectiveness. Our code is available at https://github.com/Lyn-Lucy/MSD.
CPPO: Accelerating the Training of Group Relative Policy Optimization-Based Reasoning Models
Mar 28, 2025This paper introduces Completion Pruning Policy Optimization (CPPO) to accelerate the training of reasoning models based on Group Relative Policy Optimization (GRPO). GRPO, while effective, incurs high training costs due to the need for sampling multiple completions for each question. Our experiment and theoretical analysis reveals that the number of completions impacts model accuracy yet increases training time multiplicatively, and not all completions contribute equally to policy training -- their contribution depends on their relative advantage. To address these issues, we propose CPPO, which prunes completions with low absolute advantages, significantly reducing the number needed for gradient calculation and updates. Additionally, we introduce a dynamic completion allocation strategy to maximize GPU utilization by incorporating additional questions, further enhancing training efficiency. Experimental results demonstrate that CPPO achieves up to $8.32\times$ speedup on GSM8K and $3.51\times$ on Math while preserving or even enhancing the accuracy compared to the original GRPO. We release our code at https://github.com/lzhxmu/CPPO.
LightMotion: A Light and Tuning-free Method for Simulating Camera Motion in Video Generation
Mar 11, 2025Existing camera motion-controlled video generation methods face computational bottlenecks in fine-tuning and inference. This paper proposes LightMotion, a light and tuning-free method for simulating camera motion in video generation. Operating in the latent space, it eliminates additional fine-tuning, inpainting, and depth estimation, making it more streamlined than existing methods. The endeavors of this paper comprise: (i) The latent space permutation operation effectively simulates various camera motions like panning, zooming, and rotation. (ii) The latent space resampling strategy combines background-aware sampling and cross-frame alignment to accurately fill new perspectives while maintaining coherence across frames. (iii) Our in-depth analysis shows that the permutation and resampling cause an SNR shift in latent space, leading to poor-quality generation. To address this, we propose latent space correction, which reintroduces noise during denoising to mitigate SNR shift and enhance video generation quality. Exhaustive experiments show that our LightMotion outperforms existing methods, both quantitatively and qualitatively.
Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion
Dec 16, 2024



This paper addresses the critical need for democratizing large language models (LLM) in the Arab world, a region that has seen slower progress in developing models comparable to state-of-the-art offerings like GPT-4 or ChatGPT 3.5, due to a predominant focus on mainstream languages (e.g., English and Chinese). One practical objective for an Arabic LLM is to utilize an Arabic-specific vocabulary for the tokenizer that could speed up decoding. However, using a different vocabulary often leads to a degradation of learned knowledge since many words are initially out-of-vocabulary (OOV) when training starts. Inspired by the vocabulary learning during Second Language (Arabic) Acquisition for humans, the released AraLLaMA employs progressive vocabulary expansion, which is implemented by a modified BPE algorithm that progressively extends the Arabic subwords in its dynamic vocabulary during training, thereby balancing the OOV ratio at every stage. The ablation study demonstrated the effectiveness of Progressive Vocabulary Expansion. Moreover, AraLLaMA achieves decent performance comparable to the best Arabic LLMs across a variety of Arabic benchmarks. Models, training data, benchmarks, and codes will be all open-sourced.
AccDiffusion v2: Towards More Accurate Higher-Resolution Diffusion Extrapolation
Dec 03, 2024



Diffusion models suffer severe object repetition and local distortion when the inference resolution differs from its pre-trained resolution. We propose AccDiffusion v2, an accurate method for patch-wise higher-resolution diffusion extrapolation without training. Our in-depth analysis in this paper shows that using an identical text prompt for different patches leads to repetitive generation, while the absence of a prompt undermines image details. In response, our AccDiffusion v2 novelly decouples the vanilla image-content-aware prompt into a set of patch-content-aware prompts, each of which serves as a more precise description of a patch. Further analysis reveals that local distortion arises from inaccurate descriptions in prompts about the local structure of higher-resolution images. To address this issue, AccDiffusion v2, for the first time, introduces an auxiliary local structural information through ControlNet during higher-resolution diffusion extrapolation aiming to mitigate the local distortions. Finally, our analysis indicates that global semantic information is conducive to suppressing both repetitive generation and local distortion. Hence, our AccDiffusion v2 further proposes dilated sampling with window interaction for better global semantic information during higher-resolution diffusion extrapolation. We conduct extensive experiments, including both quantitative and qualitative comparisons, to demonstrate the efficacy of our AccDiffusion v2. The quantitative comparison shows that AccDiffusion v2 achieves state-of-the-art performance in image generation extrapolation without training. The qualitative comparison intuitively illustrates that AccDiffusion v2 effectively suppresses the issues of repetitive generation and local distortion in image generation extrapolation. Our code is available at \url{https://github.com/lzhxmu/AccDiffusion_v2}.
MoFO: Momentum-Filtered Optimizer for Mitigating Forgetting in LLM Fine-Tuning
Jul 31, 2024Recently, large language models (LLMs) have demonstrated remarkable capabilities in a wide range of tasks. Typically, an LLM is pre-trained on large corpora and subsequently fine-tuned on task-specific datasets. However, during fine-tuning, LLMs may forget the knowledge acquired in the pre-training stage, leading to a decline in general capabilities. To address this issue, we propose a new fine-tuning algorithm termed Momentum-Filtered Optimizer (MoFO). The key idea of MoFO is to iteratively select and update the model parameters with the largest momentum magnitudes. Compared to full-parameter training, MoFO achieves similar fine-tuning performance while keeping parameters closer to the pre-trained model, thereby mitigating knowledge forgetting. Unlike most existing methods for forgetting mitigation, MoFO combines the following two advantages. First, MoFO does not require access to pre-training data. This makes MoFO particularly suitable for fine-tuning scenarios where pre-training data is unavailable, such as fine-tuning checkpoint-only open-source LLMs. Second, MoFO does not alter the original loss function. This could avoid impairing the model performance on the fine-tuning tasks. We validate MoFO through rigorous convergence analysis and extensive experiments, demonstrating its superiority over existing methods in mitigating forgetting and enhancing fine-tuning performance.