 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCORE: Variance-Controlled Optimization-based Reweighting for Chain-of-Thought Supervision
Oct 31, 2025



Supervised fine-tuning (SFT) on long chain-of-thought (CoT) trajectories has emerged as a crucial technique for enhancing the reasoning abilities of large language models (LLMs). However, the standard cross-entropy loss treats all tokens equally, ignoring their heterogeneous contributions across a reasoning trajectory. This uniform treatment leads to misallocated supervision and weak generalization, especially in complex, long-form reasoning tasks. To address this, we introduce \textbf{V}ariance-\textbf{C}ontrolled \textbf{O}ptimization-based \textbf{RE}weighting (VCORE), a principled framework that reformulates CoT supervision as a constrained optimization problem. By adopting an optimization-theoretic perspective, VCORE enables a principled and adaptive allocation of supervision across tokens, thereby aligning the training objective more closely with the goal of robust reasoning generalization. Empirical evaluations demonstrate that VCORE consistently outperforms existing token reweighting methods. Across both in-domain and out-of-domain settings, VCORE achieves substantial performance gains on mathematical and coding benchmarks, using models from the Qwen3 series (4B, 8B, 32B) and LLaMA-3.1-8B-Instruct. Moreover, we show that VCORE serves as a more effective initialization for subsequent reinforcement learning, establishing a stronger foundation for advancing the reasoning capabilities of LLMs. The Code will be released at https://github.com/coder-gx/VCORE.
MoFO: Momentum-Filtered Optimizer for Mitigating Forgetting in LLM Fine-Tuning
Jul 31, 2024Recently, large language models (LLMs) have demonstrated remarkable capabilities in a wide range of tasks. Typically, an LLM is pre-trained on large corpora and subsequently fine-tuned on task-specific datasets. However, during fine-tuning, LLMs may forget the knowledge acquired in the pre-training stage, leading to a decline in general capabilities. To address this issue, we propose a new fine-tuning algorithm termed Momentum-Filtered Optimizer (MoFO). The key idea of MoFO is to iteratively select and update the model parameters with the largest momentum magnitudes. Compared to full-parameter training, MoFO achieves similar fine-tuning performance while keeping parameters closer to the pre-trained model, thereby mitigating knowledge forgetting. Unlike most existing methods for forgetting mitigation, MoFO combines the following two advantages. First, MoFO does not require access to pre-training data. This makes MoFO particularly suitable for fine-tuning scenarios where pre-training data is unavailable, such as fine-tuning checkpoint-only open-source LLMs. Second, MoFO does not alter the original loss function. This could avoid impairing the model performance on the fine-tuning tasks. We validate MoFO through rigorous convergence analysis and extensive experiments, demonstrating its superiority over existing methods in mitigating forgetting and enhancing fine-tuning performance.
PDHG-Unrolled Learning-to-Optimize Method for Large-Scale Linear Programming
Jun 04, 2024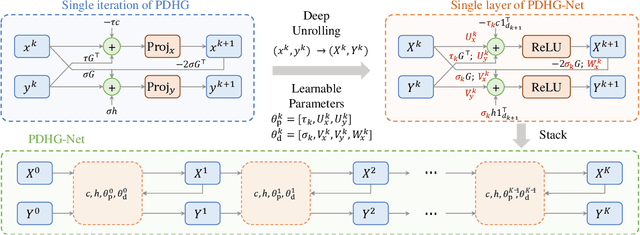
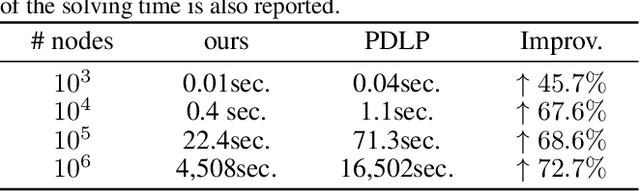
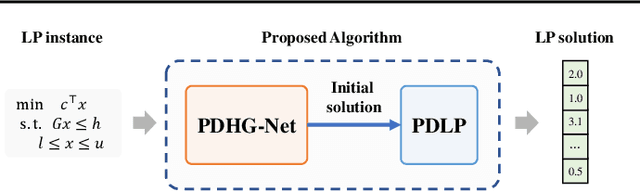
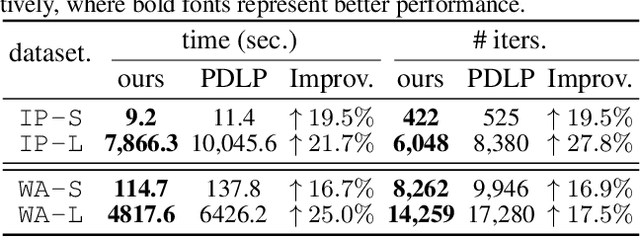
Solving large-scale linear programming (LP) problems is an important task in various areas such as communication networks, power systems, finance and logistics. Recently, two distinct approaches have emerged to expedite LP solving: (i) First-order methods (FOMs); (ii) Learning to optimize (L2O). In this work, we propose an FOM-unrolled neural network (NN) called PDHG-Net, and propose a two-stage L2O method to solve large-scale LP problems. The new architecture PDHG-Net is designed by unrolling the recently emerged PDHG method into a neural network, combined with channel-expansion techniques borrowed from graph neural networks. We prove that the proposed PDHG-Net can recover PDHG algorithm, thus can approximate optimal solutions of LP instances with a polynomial number of neurons. We propose a two-stage inference approach: first use PDHG-Net to generate an approximate solution, and then apply PDHG algorithm to further improve the solution. Experiments show that our approach can significantly accelerate LP solving, achieving up to a 3$\times$ speedup compared to FOMs for large-scale LP problems.