 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarS-Net: A Large-Scale Framework for Network-Level Spectrum Sensing
Jan 16, 2026As the demand of wireless communication continues to rise, the radio spectrum (a finite resource) requires increasingly efficient utilization. This trend is driving the evolution from static, stand-alone spectrum allocation toward spectrum sharing and dynamic spectrum sharing. A critical element of this transition is spectrum sensing, which facilitates informed decision-making in shared environments. Previous studies on spectrum sensing and cognitive radio have been largely limited to individual sensors or small sensor groups. In this work, a large-scale spectrum sensing network (LarS-Net) is designed in a cost-effective manner. Spectrum sensors are either co-located with base stations (BSs) to share the tower, backhaul, and power infrastructure, or integrated directly into BSs as a new feature leveraging active BS antenna systems. As an example incumbent system, fixed service microwave link operating in the lower-7 GHz band is investigated. This band is a primary candidate for 6G, being considered by the WRC-23, ITU, and FCC. Based on Monte Carlo simulations, we determine the minimum subset of BSs equipped with sensing capability to guarantee a target incumbent detection probability. The simulations account for various sensor antenna configurations, propagation channel models, and duty cycles for both incumbent transmissions and sensing operations. Building on this framework, we introduce three network-level sensing performance metrics: Emission Detection Probability (EDP), Temporal Detection Probability (TDP), and Temporal Mis-detection Probability (TMP), which jointly capture spatial coverage, temporal detectability, and multi-node diversity effects. Using these metrics, we analyze the impact of LarS-Net inter-site distance, noise uncertainty, and sensing duty-cycle on large-scale sensing performance.
Automated Spectrum Sensing and Analysis Framework
Jan 16, 2026Spectrum sensing and analysis is crucial for a variety of reasons, including regulatory compliance, interference detection and mitigation, and spectrum resource planning and optimization. Effective, real-time spectrum analysis remains a challenge, stemming from the need to analyse an increasingly complex and dynamic environment with limited resources. The vast amount of data generated from sensing the spectrum at multiple sites requires sophisticated data analysis and processing techniques, which can be technically demanding and expensive. This paper presents a novel, holistic framework developed and deployed at multiple locations across the USA for spectrum analysis and describes the different parts of the end-to-end pipeline. The details of each of the modules of the pipeline, data collection and pre-processing at remote locations, transfer to a centralized location, post-processing analysis, visualization, and long-term storage, are reported. The motivation behind this work is to develop a robust spectrum analysis framework that can help gain greater insights into the spectrum usage across the country and augment additional use cases such as dynamic spectrum sharing.
AI-Driven Spectrum Occupancy Prediction Using Real-World Spectrum Measurements
Jan 16, 2026Spectrum occupancy prediction is a critical enabler for real-time and proactive dynamic spectrum sharing (DSS), as it can provide short-term channel availability information to support more efficient spectrum access decisions in wireless communication systems. Instead of relying on open-source datasets or simulated data, commonly used in the literature, this paper investigates short-horizon spectrum occupancy prediction using mid-band, 24X7 real-world spectrum measurement data collected in the United States. We construct a multi-band channel occupancy dataset through analyzing 61 days of empirical data and formulate a next-minute channel occupancy prediction task across all frequency channels. This study focuses on AI-driven prediction methods, including Random Forest, Extreme Gradient Boosting (XGBoost), and a Long Short-Term Memory (LSTM) network, and compares their performance against a conventional Markov chain-based statistical baseline. Numerical results show that learning-based methods outperform the statistical baseline on dynamic channels, particularly under fixed false-alarm constraints. These results demonstrate the effectiveness of AI-driven spectrum occupancy prediction, indicating that lightweight learning models can effectively support future deployment-oriented DSS systems.
ORGEval: Graph-Theoretic Evaluation of LLMs in Optimization Modeling
Oct 31, 2025Formulating optimization problems for industrial applications demands significant manual effort and domain expertise. While Large Language Models (LLMs) show promise in automating this process, evaluating their performance remains difficult due to the absence of robust metrics. Existing solver-based approaches often face inconsistency, infeasibility issues, and high computational costs. To address these issues, we propose ORGEval, a graph-theoretic evaluation framework for assessing LLMs' capabilities in formulating linear and mixed-integer linear programs. ORGEval represents optimization models as graphs, reducing equivalence detection to graph isomorphism testing. We identify and prove a sufficient condition, when the tested graphs are symmetric decomposable (SD), under which the Weisfeiler-Lehman (WL) test is guaranteed to correctly detect isomorphism. Building on this, ORGEval integrates a tailored variant of the WL-test with an SD detection algorithm to evaluate model equivalence. By focusing on structural equivalence rather than instance-level configurations, ORGEval is robust to numerical variations. Experimental results show that our method can successfully detect model equivalence and produce 100\% consistent results across random parameter configurations, while significantly outperforming solver-based methods in runtime, especially on difficult problems. Leveraging ORGEval, we construct the Bench4Opt dataset and benchmark state-of-the-art LLMs on optimization modeling. Our results reveal that although optimization modeling remains challenging for all LLMs, DeepSeek-V3 and Claude-Opus-4 achieve the highest accuracies under direct prompting, outperforming even leading reasoning models.
VCORE: Variance-Controlled Optimization-based Reweighting for Chain-of-Thought Supervision
Oct 31, 2025



Supervised fine-tuning (SFT) on long chain-of-thought (CoT) trajectories has emerged as a crucial technique for enhancing the reasoning abilities of large language models (LLMs). However, the standard cross-entropy loss treats all tokens equally, ignoring their heterogeneous contributions across a reasoning trajectory. This uniform treatment leads to misallocated supervision and weak generalization, especially in complex, long-form reasoning tasks. To address this, we introduce \textbf{V}ariance-\textbf{C}ontrolled \textbf{O}ptimization-based \textbf{RE}weighting (VCORE), a principled framework that reformulates CoT supervision as a constrained optimization problem. By adopting an optimization-theoretic perspective, VCORE enables a principled and adaptive allocation of supervision across tokens, thereby aligning the training objective more closely with the goal of robust reasoning generalization. Empirical evaluations demonstrate that VCORE consistently outperforms existing token reweighting methods. Across both in-domain and out-of-domain settings, VCORE achieves substantial performance gains on mathematical and coding benchmarks, using models from the Qwen3 series (4B, 8B, 32B) and LLaMA-3.1-8B-Instruct. Moreover, we show that VCORE serves as a more effective initialization for subsequent reinforcement learning, establishing a stronger foundation for advancing the reasoning capabilities of LLMs. The Code will be released at https://github.com/coder-gx/VCORE.
Online SFT for LLM Reasoning: Surprising Effectiveness of Self-Tuning without Rewards
Oct 21, 2025We present a simple, self-help online supervised finetuning (OSFT) paradigm for LLM reasoning. In this paradigm, the model generates its own responses and is immediately finetuned on this self-generated data. OSFT is a highly efficient training strategy for LLM reasoning, as it is reward-free and uses just one rollout by default. Experiment results show that OSFT achieves downstream performance on challenging mathematical reasoning tasks comparable to strong reinforcement learning with verifiable rewards (RLVR) methods such as GRPO. Our ablation study further demonstrates the efficiency and robustness of OSFT. The major mechanism of OSFT lies in facilitating the model's own existing preference (latent knowledge) learned from pretraining, which leads to reasoning ability improvement. We believe that OSFT offers an efficient and promising alternative to more complex, reward-based training paradigms. Our code is available at https://github.com/ElementQi/OnlineSFT.
Bridging Formal Language with Chain-of-Thought Reasoning to Geometry Problem Solving
Aug 12, 2025
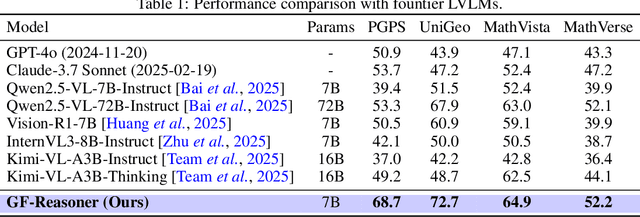
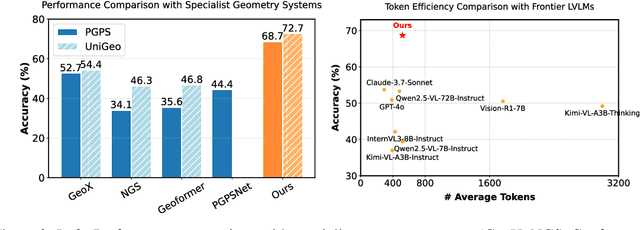
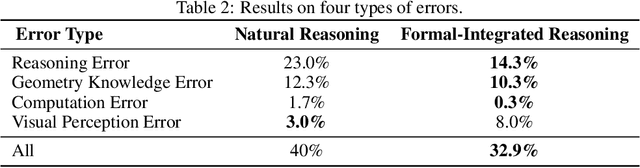
Large vision language models exhibit notable limitations on Geometry Problem Solving (GPS) because of their unreliable diagram interpretation and pure natural-language reasoning. A recent line of work mitigates this by using symbolic solvers: the model directly generates a formal program that a geometry solver can execute. However, this direct program generation lacks intermediate reasoning, making the decision process opaque and prone to errors. In this work, we explore a new approach that integrates Chain-of-Thought (CoT) with formal language. The model interleaves natural language reasoning with incremental emission of solver-executable code, producing a hybrid reasoning trace in which critical derivations are expressed in formal language. To teach this behavior at scale, we combine (1) supervised fine-tuning on an 11K newly developed synthetic dataset with interleaved natural language reasoning and automatic formalization, and (2) solver-in-the-loop reinforcement learning that jointly optimizes both the CoT narrative and the resulting program through outcome-based rewards. Built on Qwen2.5-VL-7B, our new model, named GF-Reasoner, achieves up to 15% accuracy improvements on standard GPS benchmarks, surpassing both 7B-scale peers and the much larger model Qwen2.5-VL-72B. By exploiting high-order geometric knowledge and offloading symbolic computation to the solver, the generated reasoning traces are noticeably shorter and cleaner. Furthermore, we present a comprehensive analysis of method design choices (e.g., reasoning paradigms, data synthesis, training epochs, etc.), providing actionable insights for future research.
CoRT: Code-integrated Reasoning within Thinking
Jun 12, 2025Large Reasoning Models (LRMs) like o1 and DeepSeek-R1 have shown remarkable progress in natural language reasoning with long chain-of-thought (CoT), yet they remain inefficient or inaccurate when handling complex mathematical operations. Addressing these limitations through computational tools (e.g., computation libraries and symbolic solvers) is promising, but it introduces a technical challenge: Code Interpreter (CI) brings external knowledge beyond the model's internal text representations, thus the direct combination is not efficient. This paper introduces CoRT, a post-training framework for teaching LRMs to leverage CI effectively and efficiently. As a first step, we address the data scarcity issue by synthesizing code-integrated reasoning data through Hint-Engineering, which strategically inserts different hints at appropriate positions to optimize LRM-CI interaction. We manually create 30 high-quality samples, upon which we post-train models ranging from 1.5B to 32B parameters, with supervised fine-tuning, rejection fine-tuning and reinforcement learning. Our experimental results demonstrate that Hint-Engineering models achieve 4\% and 8\% absolute improvements on DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Qwen-1.5B respectively, across five challenging mathematical reasoning datasets. Furthermore, Hint-Engineering models use about 30\% fewer tokens for the 32B model and 50\% fewer tokens for the 1.5B model compared with the natural language models. The models and code are available at https://github.com/ChengpengLi1003/CoRT.
Rethinking Data Mixture for Large Language Models: A Comprehensive Survey and New Perspectives
May 27, 2025Training large language models with data collected from various domains can improve their performance on downstream tasks. However, given a fixed training budget, the sampling proportions of these different domains significantly impact the model's performance. How can we determine the domain weights across different data domains to train the best-performing model within constrained computational resources? In this paper, we provide a comprehensive overview of existing data mixture methods. First, we propose a fine-grained categorization of existing methods, extending beyond the previous offline and online classification. Offline methods are further grouped into heuristic-based, algorithm-based, and function fitting-based methods. For online methods, we categorize them into three groups: online min-max optimization, online mixing law, and other approaches by drawing connections with the optimization frameworks underlying offline methods. Second, we summarize the problem formulations, representative algorithms for each subtype of offline and online methods, and clarify the relationships and distinctions among them. Finally, we discuss the advantages and disadvantages of each method and highlight key challenges in the field of data mixture.
Towards Quantifying the Hessian Structure of Neural Networks
May 05, 2025Empirical studies reported that the Hessian matrix of neural networks (NNs) exhibits a near-block-diagonal structure, yet its theoretical foundation remains unclear. In this work, we reveal two forces that shape the Hessian structure: a ``static force'' rooted in the architecture design, and a ``dynamic force'' arisen from training. We then provide a rigorous theoretical analysis of ``static force'' at random initialization. We study linear models and 1-hidden-layer networks with the mean-square (MSE) loss and the Cross-Entropy (CE) loss for classification tasks. By leveraging random matrix theory, we compare the limit distributions of the diagonal and off-diagonal Hessian blocks and find that the block-diagonal structure arises as $C \rightarrow \infty$, where $C$ denotes the number of classes. Our findings reveal that $C$ is a primary driver of the near-block-diagonal structure. These results may shed new light on the Hessian structure of large language models (LLMs), which typically operate with a large $C$ exceeding $10^4$ or $10^5$.