 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel multi-agent dynamic portfolio optimization learning system based on hierarchical deep reinforcement learning
Jan 12, 2025
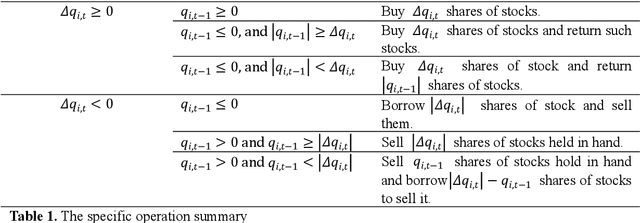

Deep Reinforcement Learning (DRL) has been extensively used to address portfolio optimization problems. The DRL agents acquire knowledge and make decisions through unsupervised interactions with their environment without requiring explicit knowledge of the joint dynamics of portfolio assets. Among these DRL algorithms, the combination of actor-critic algorithms and deep function approximators is the most widely used DRL algorithm. Here, we find that training the DRL agent using the actor-critic algorithm and deep function approximators may lead to scenarios where the improvement in the DRL agent's risk-adjusted profitability is not significant. We propose that such situations primarily arise from the following two problems: sparsity in positive reward and the curse of dimensionality. These limitations prevent DRL agents from comprehensively learning asset price change patterns in the training environment. As a result, the DRL agents cannot explore the dynamic portfolio optimization policy to improve the risk-adjusted profitability in the training process. To address these problems, we propose a novel multi-agent Hierarchical Deep Reinforcement Learning (HDRL) algorithmic framework in this research. Under this framework, the agents work together as a learning system for portfolio optimization. Specifically, by designing an auxiliary agent that works together with the executive agent for optimal policy exploration, the learning system can focus on exploring the policy with higher risk-adjusted return in the action space with positive return and low variance. In this way, we can overcome the issue of the curse of dimensionality and improve the training efficiency in the positive reward sparse environment.
EFormer: Enhanced Transformer towards Semantic-Contour Features of Foreground for Portraits Matting
Aug 24, 2023The portrait matting task aims to extract an alpha matte with complete semantics and finely-detailed contours. In comparison to CNN-based approaches, transformers with self-attention allow a larger receptive field, enabling it to better capture long-range dependencies and low-frequency semantic information of a portrait. However, the recent research shows that self-attention mechanism struggle with modeling high-frequency information and capturing fine contour details, which can lead to bias while predicting the portrait's contours. To address the problem, we propose EFormer to enhance the model's attention towards semantic and contour features. Especially the latter, which is surrounded by a large amount of high-frequency details. We build a semantic and contour detector (SCD) to accurately capture the distribution of semantic and contour features. And we further design contour-edge extraction branch and semantic extraction branch for refining contour features and complete semantic information. Finally, we fuse the two kinds of features and leverage the segmentation head to generate the predicted portrait matte. Remarkably, EFormer is an end-to-end trimap-free method and boasts a simple structure. Experiments conducted on VideoMatte240K-JPEGSD and AIM datasets demonstrate that EFormer outperforms previous portrait matte methods.
Beyond Context: Exploring Semantic Similarity for Tiny Face Detection
Mar 05, 2018
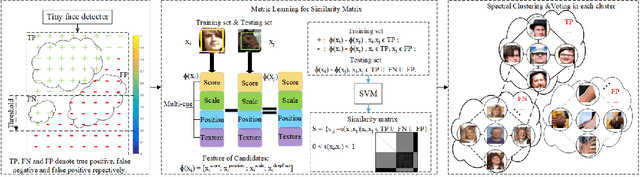
Tiny face detection aims to find faces with high degrees of variability in scale, resolution and occlusion in cluttered scenes. Due to the very little information available on tiny faces, it is not sufficient to detect them merely based on the information presented inside the tiny bounding boxes or their context. In this paper, we propose to exploit the semantic similarity among all predicted targets in each image to boost current face detectors. To this end, we present a novel framework to model semantic similarity as pairwise constraints within the metric learning scheme, and then refine our predictions with the semantic similarity by utilizing the graph cut techniques. Experiments conducted on three widely-used benchmark datasets have demonstrated the improvement over the-state-of-the-arts gained by applying this idea.