 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Market Regime Changes and Heavy-Tailed Returns in Portfolio Optimization via Bayesian VAR and Elliptical Black-Litterman
Jun 08, 2026Deep reinforcement learning (DRL) frameworks for portfolio optimization have shown promise for their ability to learn allocation rules dynamically from market data. However, these models fail to account for fat-tailed returns, which characterize actual market behavior with more frequent extreme events. Furthermore, historical data is treated homogeneously, without accounting for temporal importance, leading models to fail during regime changes. We propose a new BAVAR-BLED algorithm that combines methods derived from Bayesian-Averaging Vector Autoregressive (BAVAR) and the Black-Litterman model using Elliptical Distributions (BLED) within a TD3 architecture. BAVAR captures a set of vector autoregressive representations that consider multi-scale temporal features, enabling adaptive allocation decisions based on regime-aware estimates of return expectations and dispersion matrices. These estimates serve as prior inputs to BLED, a model that uses Student's t-distributions, allowing for more realistic fat tail return estimates. The BAVAR-BLED algorithm uses transformer networks for view construction and CNNs for risk-aversion estimates, which modify dynamic allocation decisions based on market conditions. An evaluation of 29 Dow Jones Industrial Average constituents over a decade-long market period shows that BAVAR-BLED significantly outperforms state-of-the-art methods, achieving Sharpe and Sortino ratios of 1.72 and 2.70, respectively, and total returns of 57.26%.
MERIT: Multilingual Expert-Reward Informed Tuning for Chinese-Centric Low-Resource Machine Translation
Apr 06, 2026Neural machine translation (NMT) from Chinese to low-resource Southeast Asian languages remains severely constrained by the extreme scarcity of clean parallel corpora and the pervasive noise in existing mined data. This chronic shortage not only impedes effective model training but also sustains a large performance gap with high-resource directions, leaving millions of speakers of languages such as Lao, Burmese, and Tagalog with persistently low-quality translation systems despite recent advances in large multilingual models. We introduce \textbf{M}ultilingual \textbf{E}xpert-\textbf{R}eward \textbf{I}nformed \textbf{T}uning (\textbf{MERIT}), a unified translation framework that transforms the traditional English-centric ALT benchmark into a Chinese-centric evaluation suite for five Southeast Asian low-resource languages (LRLs). Our framework combines language-specific token prefixing (LTP) with supervised fine-tuning (SFT) and a novel group relative policy optimization (GRPO) guided by the semantic alignment reward (SAR). These results confirm that, in LRL{\textrightarrow}Chinese translation, targeted data curation and reward-guided optimization dramatically outperform mere model scaling.
SAGE: Sustainable Agent-Guided Expert-tuning for Culturally Attuned Translation in Low-Resource Southeast Asia
Mar 20, 2026The vision of an inclusive World Wide Web is impeded by a severe linguistic divide, particularly for communities in low-resource regions of Southeast Asia. While large language models (LLMs) offer a potential solution for translation, their deployment in data-poor contexts faces a dual challenge: the scarcity of high-quality, culturally relevant data and the prohibitive energy costs of training on massive, noisy web corpora. To resolve the tension between digital inclusion and environmental sustainability, we introduce Sustainable Agent-Guided Expert-tuning (SAGE). This framework pioneers an energy-aware paradigm that prioritizes the "right data" over "big data". Instead of carbon-intensive training on unfiltered datasets, SAGE employs a reinforcement learning (RL) agent, optimized via Group Relative Policy Optimization (GRPO), to autonomously curate a compact training set. The agent utilizes a semantic reward signal derived from a small, expert-constructed set of community dialogues to filter out noise and cultural misalignment. We then efficiently fine-tune open-source LLMs on this curated data using Low-Rank Adaptation (LoRA). We applied SAGE to translation tasks between English and seven low-resource languages (LRLs) in Southeast Asia. Our approach establishes new state-of-the-art performance on BLEU-4 and COMET-22 metrics, effectively capturing local linguistic nuances. Crucially, SAGE surpasses baselines trained on full datasets while reducing data usage by 97.1% and training energy consumption by 95.2%. By delivering high-performance models with a minimal environmental footprint, SAGE offers a scalable and responsible pathway to bridge the digital divide in the Global South.
SAMP-HDRL: Segmented Allocation with Momentum-Adjusted Utility for Multi-agent Portfolio Management via Hierarchical Deep Reinforcement Learning
Dec 28, 2025Portfolio optimization in non-stationary markets is challenging due to regime shifts, dynamic correlations, and the limited interpretability of deep reinforcement learning (DRL) policies. We propose a Segmented Allocation with Momentum-Adjusted Utility for Multi-agent Portfolio Management via Hierarchical Deep Reinforcement Learning (SAMP-HDRL). The framework first applies dynamic asset grouping to partition the market into high-quality and ordinary subsets. An upper-level agent extracts global market signals, while lower-level agents perform intra-group allocation under mask constraints. A utility-based capital allocation mechanism integrates risky and risk-free assets, ensuring coherent coordination between global and local decisions. backtests across three market regimes (2019--2021) demonstrate that SAMP-HDRL consistently outperforms nine traditional baselines and nine DRL benchmarks under volatile and oscillating conditions. Compared with the strongest baseline, our method achieves at least 5\% higher Return, 5\% higher Sharpe ratio, 5\% higher Sortino ratio, and 2\% higher Omega ratio, with substantially larger gains observed in turbulent markets. Ablation studies confirm that upper--lower coordination, dynamic clustering, and capital allocation are indispensable to robustness. SHAP-based interpretability further reveals a complementary ``diversified + concentrated'' mechanism across agents, providing transparent insights into decision-making. Overall, SAMP-HDRL embeds structural market constraints directly into the DRL pipeline, offering improved adaptability, robustness, and interpretability in complex financial environments.
Silhouette-to-Contour Registration: Aligning Intraoral Scan Models with Cephalometric Radiographs
Nov 18, 2025Reliable 3D-2D alignment between intraoral scan (IOS) models and lateral cephalometric radiographs is critical for orthodontic diagnosis, yet conventional intensity-driven registration methods struggle under real clinical conditions, where cephalograms exhibit projective magnification, geometric distortion, low-contrast dental crowns, and acquisition-dependent variation. These factors hinder the stability of appearance-based similarity metrics and often lead to convergence failures or anatomically implausible alignments. To address these limitations, we propose DentalSCR, a pose-stable, contour-guided framework for accurate and interpretable silhouette-to-contour registration. Our method first constructs a U-Midline Dental Axis (UMDA) to establish a unified cross-arch anatomical coordinate system, thereby stabilizing initialization and standardizing projection geometry across cases. Using this reference frame, we generate radiograph-like projections via a surface-based DRR formulation with coronal-axis perspective and Gaussian splatting, which preserves clinical source-object-detector magnification and emphasizes external silhouettes. Registration is then formulated as a 2D similarity transform optimized with a symmetric bidirectional Chamfer distance under a hierarchical coarse-to-fine schedule, enabling both large capture range and subpixel-level contour agreement. We evaluate DentalSCR on 34 expert-annotated clinical cases. Experimental results demonstrate substantial reductions in landmark error-particularly at posterior teeth-tighter dispersion on the lower jaw, and low Chamfer and controlled Hausdorff distances at the curve level. These findings indicate that DentalSCR robustly handles real-world cephalograms and delivers high-fidelity, clinically inspectable 3D--2D alignment, outperforming conventional baselines.
Dental3R: Geometry-Aware Pairing for Intraoral 3D Reconstruction from Sparse-View Photographs
Nov 18, 2025Intraoral 3D reconstruction is fundamental to digital orthodontics, yet conventional methods like intraoral scanning are inaccessible for remote tele-orthodontics, which typically relies on sparse smartphone imagery. While 3D Gaussian Splatting (3DGS) shows promise for novel view synthesis, its application to the standard clinical triad of unposed anterior and bilateral buccal photographs is challenging. The large view baselines, inconsistent illumination, and specular surfaces common in intraoral settings can destabilize simultaneous pose and geometry estimation. Furthermore, sparse-view photometric supervision often induces a frequency bias, leading to over-smoothed reconstructions that lose critical diagnostic details. To address these limitations, we propose \textbf{Dental3R}, a pose-free, graph-guided pipeline for robust, high-fidelity reconstruction from sparse intraoral photographs. Our method first constructs a Geometry-Aware Pairing Strategy (GAPS) to intelligently select a compact subgraph of high-value image pairs. The GAPS focuses on correspondence matching, thereby improving the stability of the geometry initialization and reducing memory usage. Building on the recovered poses and point cloud, we train the 3DGS model with a wavelet-regularized objective. By enforcing band-limited fidelity using a discrete wavelet transform, our approach preserves fine enamel boundaries and interproximal edges while suppressing high-frequency artifacts. We validate our approach on a large-scale dataset of 950 clinical cases and an additional video-based test set of 195 cases. Experimental results demonstrate that Dental3R effectively handles sparse, unposed inputs and achieves superior novel view synthesis quality for dental occlusion visualization, outperforming state-of-the-art methods.
Factor-MCLS: Multi-agent learning system with reward factor matrix and multi-critic framework for dynamic portfolio optimization
Apr 16, 2025Typical deep reinforcement learning (DRL) agents for dynamic portfolio optimization learn the factors influencing portfolio return and risk by analyzing the output values of the reward function while adjusting portfolio weights within the training environment. However, it faces a major limitation where it is difficult for investors to intervene in the training based on different levels of risk aversion towards each portfolio asset. This difficulty arises from another limitation: existing DRL agents may not develop a thorough understanding of the factors responsible for the portfolio return and risk by only learning from the output of the reward function. As a result, the strategy for determining the target portfolio weights is entirely dependent on the DRL agents themselves. To address these limitations, we propose a reward factor matrix for elucidating the return and risk of each asset in the portfolio. Additionally, we propose a novel learning system named Factor-MCLS using a multi-critic framework that facilitates learning of the reward factor matrix. In this way, our DRL-based learning system can effectively learn the factors influencing portfolio return and risk. Moreover, based on the critic networks within the multi-critic framework, we develop a risk constraint term in the training objective function of the policy function. This risk constraint term allows investors to intervene in the training of the DRL agent according to their individual levels of risk aversion towards the portfolio assets.
MSWAL: 3D Multi-class Segmentation of Whole Abdominal Lesions Dataset
Mar 17, 2025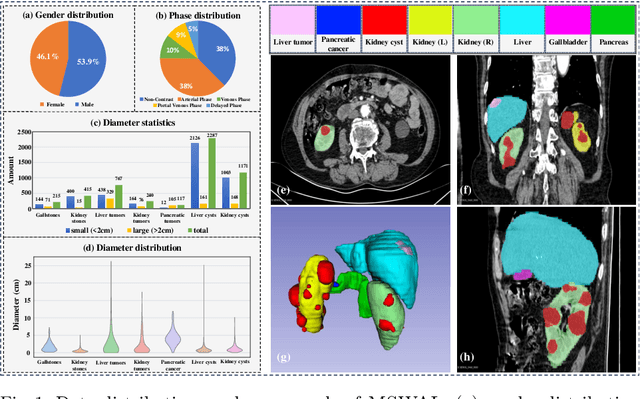
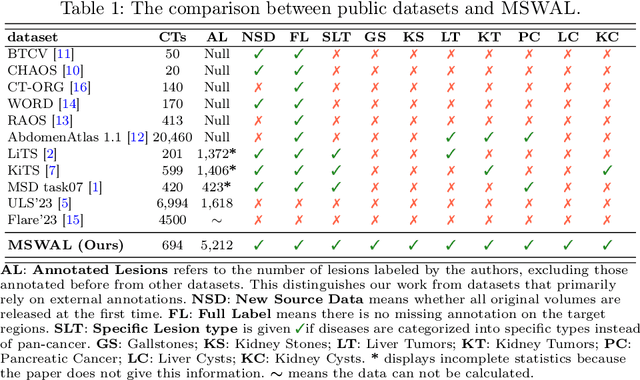
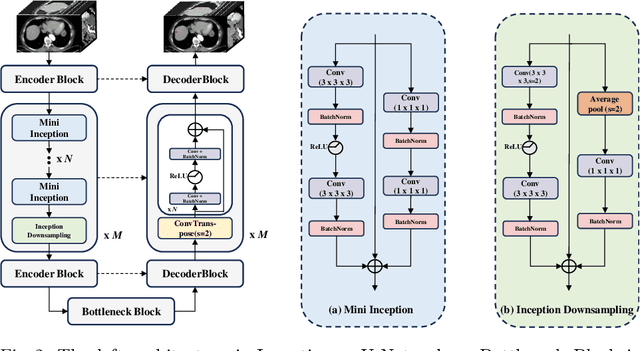
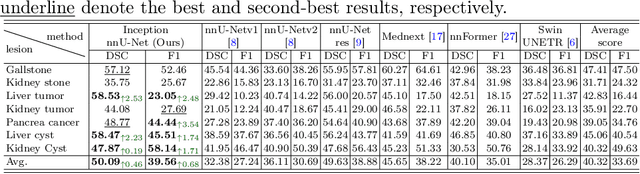
With the significantly increasing incidence and prevalence of abdominal diseases, there is a need to embrace greater use of new innovations and technology for the diagnosis and treatment of patients. Although deep-learning methods have notably been developed to assist radiologists in diagnosing abdominal diseases, existing models have the restricted ability to segment common lesions in the abdomen due to missing annotations for typical abdominal pathologies in their training datasets. To address the limitation, we introduce MSWAL, the first 3D Multi-class Segmentation of the Whole Abdominal Lesions dataset, which broadens the coverage of various common lesion types, such as gallstones, kidney stones, liver tumors, kidney tumors, pancreatic cancer, liver cysts, and kidney cysts. With CT scans collected from 694 patients (191,417 slices) of different genders across various scanning phases, MSWAL demonstrates strong robustness and generalizability. The transfer learning experiment from MSWAL to two public datasets, LiTS and KiTS, effectively demonstrates consistent improvements, with Dice Similarity Coefficient (DSC) increase of 3.00% for liver tumors and 0.89% for kidney tumors, demonstrating that the comprehensive annotations and diverse lesion types in MSWAL facilitate effective learning across different domains and data distributions. Furthermore, we propose Inception nnU-Net, a novel segmentation framework that effectively integrates an Inception module with the nnU-Net architecture to extract information from different receptive fields, achieving significant enhancement in both voxel-level DSC and region-level F1 compared to the cutting-edge public algorithms on MSWAL. Our dataset will be released after being accepted, and the code is publicly released at https://github.com/tiuxuxsh76075/MSWAL-.
MTS: A Deep Reinforcement Learning Portfolio Management Framework with Time-Awareness and Short-Selling
Mar 06, 2025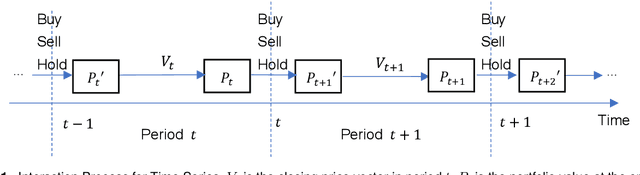
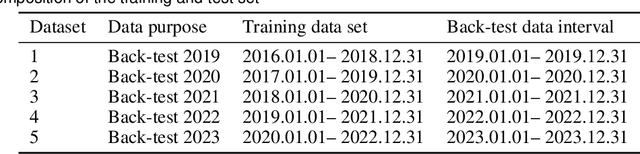
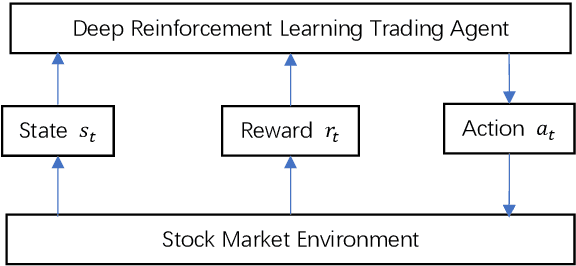
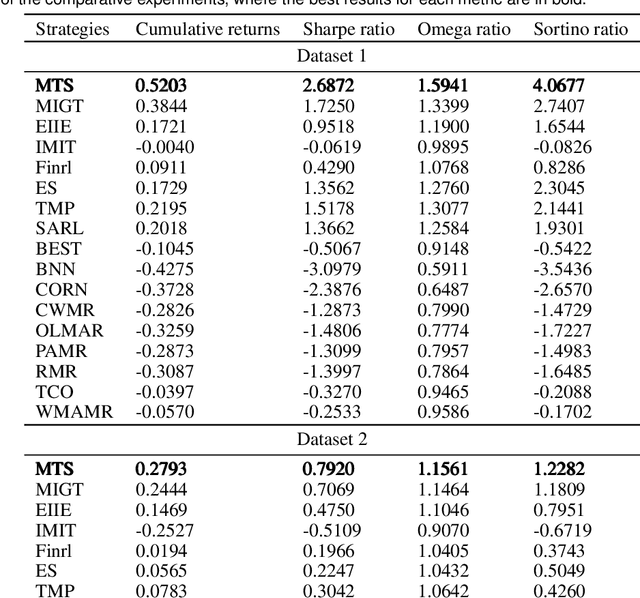
Portfolio management remains a crucial challenge in finance, with traditional methods often falling short in complex and volatile market environments. While deep reinforcement approaches have shown promise, they still face limitations in dynamic risk management, exploitation of temporal markets, and incorporation of complex trading strategies such as short-selling. These limitations can lead to suboptimal portfolio performance, increased vulnerability to market volatility, and missed opportunities in capturing potential returns from diverse market conditions. This paper introduces a Deep Reinforcement Learning Portfolio Management Framework with Time-Awareness and Short-Selling (MTS), offering a robust and adaptive strategy for sustainable investment performance. This framework utilizes a novel encoder-attention mechanism to address the limitations by incorporating temporal market characteristics, a parallel strategy for automated short-selling based on market trends, and risk management through innovative Incremental Conditional Value at Risk, enhancing adaptability and performance. Experimental validation on five diverse datasets from 2019 to 2023 demonstrates MTS's superiority over traditional algorithms and advanced machine learning techniques. MTS consistently achieves higher cumulative returns, Sharpe, Omega, and Sortino ratios, underscoring its effectiveness in balancing risk and return while adapting to market dynamics. MTS demonstrates an average relative increase of 30.67% in cumulative returns and 29.33% in Sharpe ratio compared to the next best-performing strategies across various datasets.
A novel multi-agent dynamic portfolio optimization learning system based on hierarchical deep reinforcement learning
Jan 12, 2025
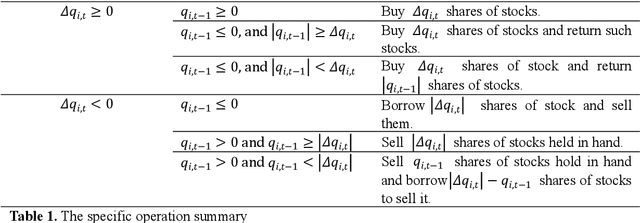
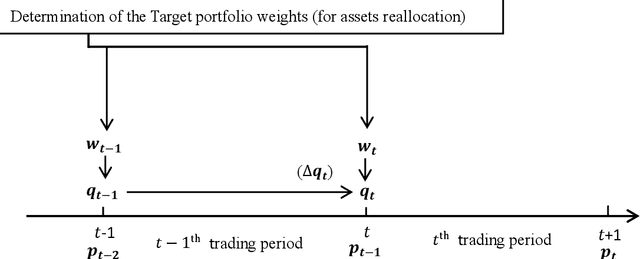

Deep Reinforcement Learning (DRL) has been extensively used to address portfolio optimization problems. The DRL agents acquire knowledge and make decisions through unsupervised interactions with their environment without requiring explicit knowledge of the joint dynamics of portfolio assets. Among these DRL algorithms, the combination of actor-critic algorithms and deep function approximators is the most widely used DRL algorithm. Here, we find that training the DRL agent using the actor-critic algorithm and deep function approximators may lead to scenarios where the improvement in the DRL agent's risk-adjusted profitability is not significant. We propose that such situations primarily arise from the following two problems: sparsity in positive reward and the curse of dimensionality. These limitations prevent DRL agents from comprehensively learning asset price change patterns in the training environment. As a result, the DRL agents cannot explore the dynamic portfolio optimization policy to improve the risk-adjusted profitability in the training process. To address these problems, we propose a novel multi-agent Hierarchical Deep Reinforcement Learning (HDRL) algorithmic framework in this research. Under this framework, the agents work together as a learning system for portfolio optimization. Specifically, by designing an auxiliary agent that works together with the executive agent for optimal policy exploration, the learning system can focus on exploring the policy with higher risk-adjusted return in the action space with positive return and low variance. In this way, we can overcome the issue of the curse of dimensionality and improve the training efficiency in the positive reward sparse environment.