 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarm-Started Reinforcement Learning for Iterative 3D/2D Liver Registration
Apr 11, 2026Registration between preoperative CT and intraoperative laparoscopic video plays a crucial role in augmented reality (AR) guidance for minimally invasive surgery. Learning-based methods have recently achieved registration errors comparable to optimization-based approaches while offering faster inference. However, many supervised methods produce coarse alignments that rely on additional optimization-based refinement, thereby increasing inference time. We present a discrete-action reinforcement learning (RL) framework that formulates CT-to-video registration as a sequential decision-making process. A shared feature encoder, warm-started from a supervised pose estimation network to provide stable geometric features and faster convergence, extracts representations from CT renderings and laparoscopic frames, while an RL policy head learns to choose rigid transformations along six degrees of freedom and to decide when to stop the iteration. Experiments on a public laparoscopic dataset demonstrated that our method achieved an average target registration error (TRE) of 15.70 mm, comparable to supervised approaches with optimization, while achieving faster convergence. The proposed RL-based formulation enables automated, efficient iterative registration without manually tuned step sizes or stopping criteria. This discrete framework provides a practical foundation for future continuous-action and deformable registration models in surgical AR applications.
Maximizing T2-Only Prostate Cancer Localization from Expected Diffusion Weighted Imaging
Apr 01, 2026Multiparametric MRI is increasingly recommended as a first-line noninvasive approach to detect and localize prostate cancer, requiring at minimum diffusion-weighted (DWI) and T2-weighted (T2w) MR sequences. Early machine learning attempts using only T2w images have shown promising diagnostic performance in segmenting radiologist-annotated lesions. Such uni-modal T2-only approaches deliver substantial clinical benefits by reducing costs and expertise required to acquire other sequences. This work investigates an arguably more challenging application using only T2w at inference, but to localize individual cancers based on independent histopathology labels. We formulate DWI images as a latent modality (readily available during training) to classify cancer presence at local Barzell zones, given only T2w images as input. In the resulting expectation-maximization algorithm, a latent modality generator (implemented using a flow matching-based generative model) approximates the latent DWI image posterior distribution in the E-steps, while in M-steps a cancer localizer is simultaneously optimized with the generative model to maximize the expected likelihood of cancer presence. The proposed approach provides a novel theoretical framework for learning from a privileged DWI modality, yielding superior cancer localization performance compared to approaches that lack training DWI images or existing frameworks for privileged learning and incomplete modalities. The proposed T2-only methods perform competitively or better than baseline methods using multiple input sequences (e.g., improving the patient-level F1 score by 14.4\% and zone-level QWK by 5.3\% over the T2w+DWI baseline). We present quantitative evaluations using internal and external datasets from 4,133 prostate cancer patients with histopathology-verified labels.
A Unified Framework for Joint Detection of Lacunes and Enlarged Perivascular Spaces
Mar 05, 2026Cerebral small vessel disease (CSVD) markers, specifically enlarged perivascular spaces (EPVS) and lacunae, present a unique challenge in medical image analysis due to their radiological mimicry. Standard segmentation networks struggle with feature interference and extreme class imbalance when handling these divergent targets simultaneously. To address these issues, we propose a morphology-decoupled framework where Zero-Initialized Gated Cross-Task Attention exploits dense EPVS context to guide sparse lacune detection. Furthermore, biological and topological consistency are enforced via a mixed-supervision strategy integrating Mutual Exclusion and Centerline Dice losses. Finally, we introduce an Anatomically-Informed Inference Calibration mechanism to dynamically suppress false positives based on tissue semantics. Extensive 5-folds cross-validation on the VALDO 2021 dataset (N=40) demonstrates state-of-the-art performance, notably surpassing task winners in lacunae detection precision (71.1%, p=0.01) and F1-score (62.6%, p=0.03). Furthermore, evaluation on the external EPAD cohort (N=1762) confirms the model's robustness for large-scale population studies. Code will be released upon acceptance.
FoundationPose-Initialized 3D-2D Liver Registration for Surgical Augmented Reality
Feb 19, 2026Augmented reality can improve tumor localization in laparoscopic liver surgery. Existing registration pipelines typically depend on organ contours; deformable (non-rigid) alignment is often handled with finite-element (FE) models coupled to dimensionality-reduction or machine-learning components. We integrate laparoscopic depth maps with a foundation pose estimator for camera-liver pose estimation and replace FE-based deformation with non-rigid iterative closest point (NICP) to lower engineering/modeling complexity and expertise requirements. On real patient data, the depth-augmented foundation pose approach achieved 9.91 mm mean registration error in 3 cases. Combined rigid-NICP registration outperformed rigid-only registration, demonstrating NICP as an efficient substitute for finite-element deformable models. This pipeline achieves clinically relevant accuracy while offering a lightweight, engineering-friendly alternative to FE-based deformation.
Can We Trust LLMs? Mitigate Overconfidence Bias in LLMs through Knowledge Transfer
May 27, 2024



The study explores mitigating overconfidence bias in LLMs to improve their reliability. We introduce a knowledge transfer (KT) method utilizing chain of thoughts, where "big" LLMs impart knowledge to "small" LLMs via detailed, sequential reasoning paths. This method uses advanced reasoning of larger models to fine-tune smaller models, enabling them to produce more accurate predictions with calibrated confidence. Experimental evaluation using multiple-choice questions and sentiment analysis across diverse datasets demonstrated the KT method's superiority over the vanilla and question-answer pair (QA) fine-tuning methods. The most significant improvement in three key metrics, where the KT method outperformed the vanilla and QA methods by an average of 55.3% and 43.1%, respectively. These findings underscore the KT method's potential in enhancing model trustworthiness and accuracy, offering precise outputs with well-matched confidence levels across various contexts.
YNetr: Dual-Encoder architecture on Plain Scan Liver Tumors
Mar 30, 2024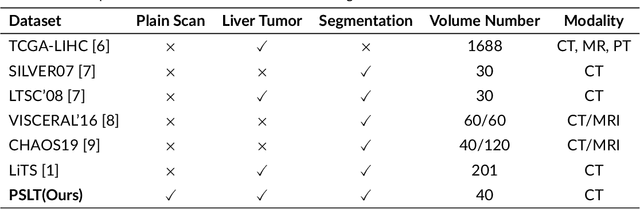

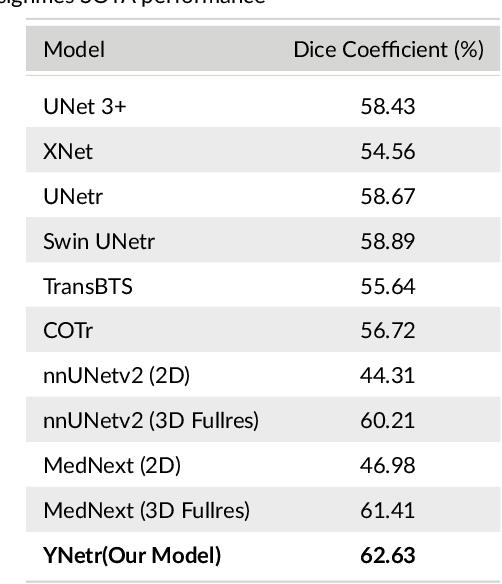
Background: Liver tumors are abnormal growths in the liver that can be either benign or malignant, with liver cancer being a significant health concern worldwide. However, there is no dataset for plain scan segmentation of liver tumors, nor any related algorithms. To fill this gap, we propose Plain Scan Liver Tumors(PSLT) and YNetr. Methods: A collection of 40 liver tumor plain scan segmentation datasets was assembled and annotated. Concurrently, we utilized Dice coefficient as the metric for assessing the segmentation outcomes produced by YNetr, having advantage of capturing different frequency information. Results: The YNetr model achieved a Dice coefficient of 62.63% on the PSLT dataset, surpassing the other publicly available model by an accuracy margin of 1.22%. Comparative evaluations were conducted against a range of models including UNet 3+, XNet, UNetr, Swin UNetr, Trans-BTS, COTr, nnUNetv2 (2D), nnUNetv2 (3D fullres), MedNext (2D) and MedNext(3D fullres). Conclusions: We not only proposed a dataset named PSLT(Plain Scan Liver Tumors), but also explored a structure called YNetr that utilizes wavelet transform to extract different frequency information, which having the SOTA in PSLT by experiments.
RNTrajRec: Road Network Enhanced Trajectory Recovery with Spatial-Temporal Transformer
Nov 28, 2022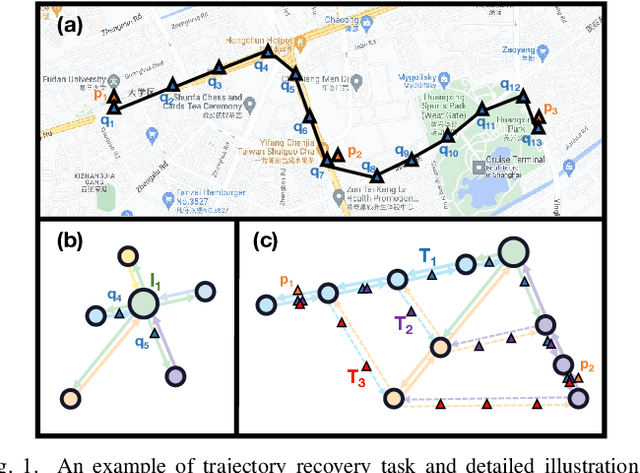
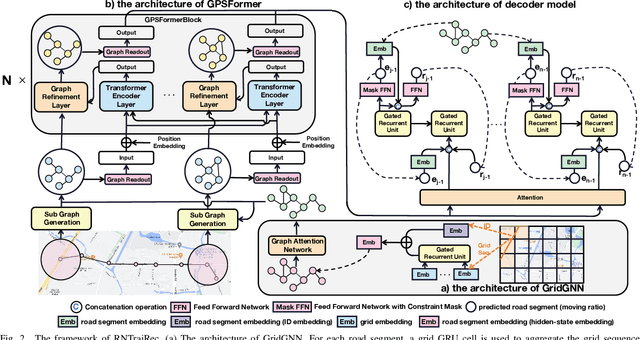
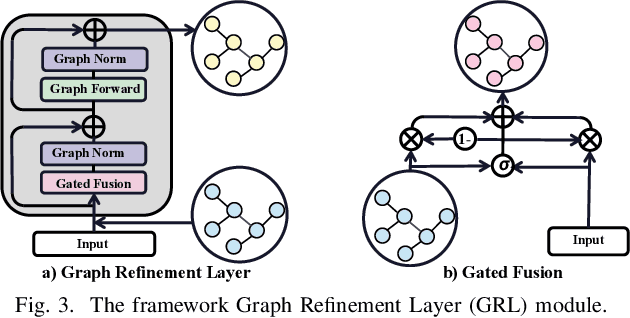
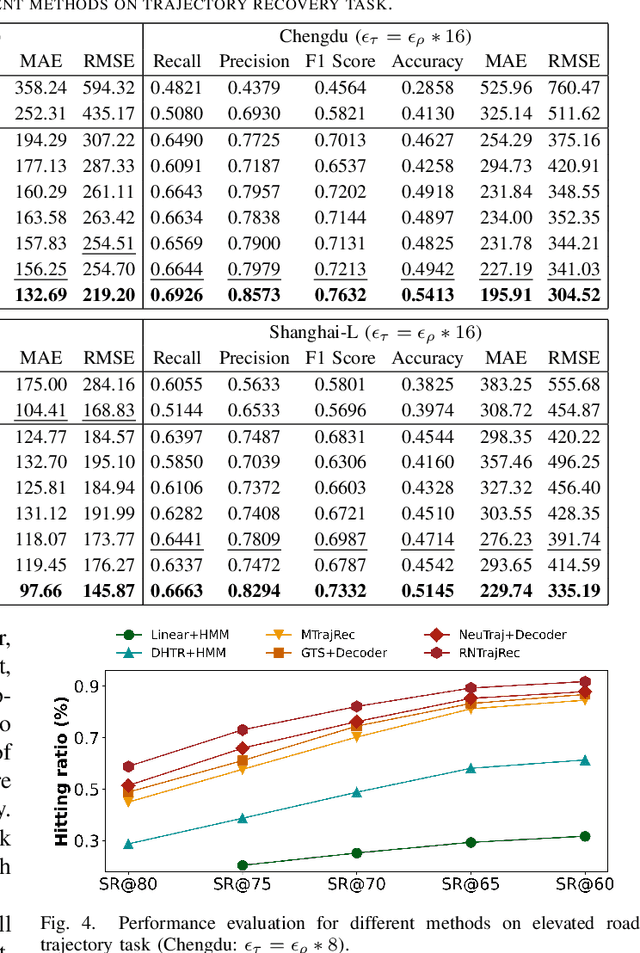
GPS trajectories are the essential foundations for many trajectory-based applications, such as travel time estimation, traffic prediction and trajectory similarity measurement. Most applications require a large amount of high sample rate trajectories to achieve a good performance. However, many real-life trajectories are collected with low sample rate due to energy concern or other constraints.We study the task of trajectory recovery in this paper as a means for increasing the sample rate of low sample trajectories. Currently, most existing works on trajectory recovery follow a sequence-to-sequence diagram, with an encoder to encode a trajectory and a decoder to recover real GPS points in the trajectory. However, these works ignore the topology of road network and only use grid information or raw GPS points as input. Therefore, the encoder model is not able to capture rich spatial information of the GPS points along the trajectory, making the prediction less accurate and lack spatial consistency. In this paper, we propose a road network enhanced transformer-based framework, namely RNTrajRec, for trajectory recovery. RNTrajRec first uses a graph model, namely GridGNN, to learn the embedding features of each road segment. It next develops a spatial-temporal transformer model, namely GPSFormer, to learn rich spatial and temporal features along with a Sub-Graph Generation module to capture the spatial features for each GPS point in the trajectory. It finally forwards the outputs of encoder model into a multi-task decoder model to recover the missing GPS points. Extensive experiments based on three large-scale real-life trajectory datasets confirm the effectiveness of our approach.
DeepDualMapper: A Gated Fusion Network for Automatic Map Extraction using Aerial Images and Trajectories
Feb 17, 2020
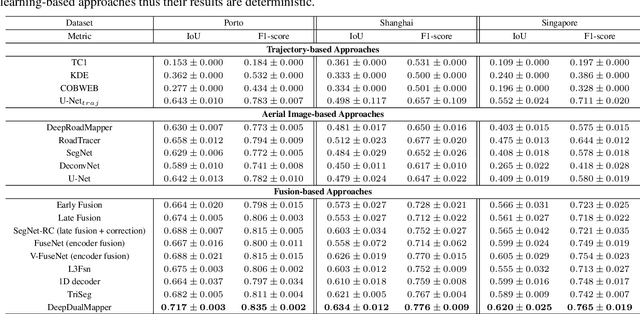
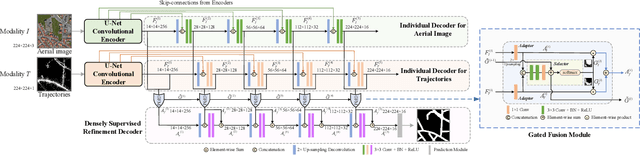
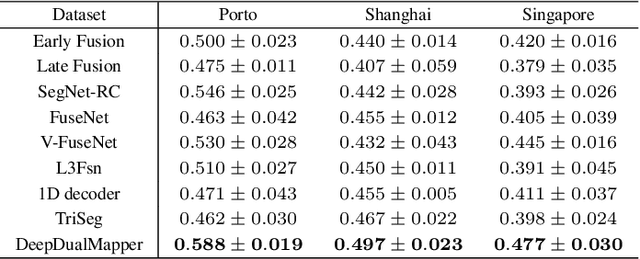
Automatic map extraction is of great importance to urban computing and location-based services. Aerial image and GPS trajectory data refer to two different data sources that could be leveraged to generate the map, although they carry different types of information. Most previous works on data fusion between aerial images and data from auxiliary sensors do not fully utilize the information of both modalities and hence suffer from the issue of information loss. We propose a deep convolutional neural network called DeepDualMapper which fuses the aerial image and trajectory data in a more seamless manner to extract the digital map. We design a gated fusion module to explicitly control the information flows from both modalities in a complementary-aware manner. Moreover, we propose a novel densely supervised refinement decoder to generate the prediction in a coarse-to-fine way. Our comprehensive experiments demonstrate that DeepDualMapper can fuse the information of images and trajectories much more effectively than existing approaches, and is able to generate maps with higher accuracy.
DeepTravel: a Neural Network Based Travel Time Estimation Model with Auxiliary Supervision
Feb 06, 2018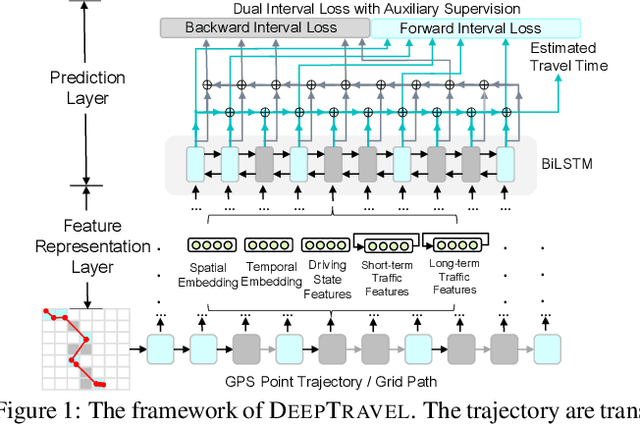
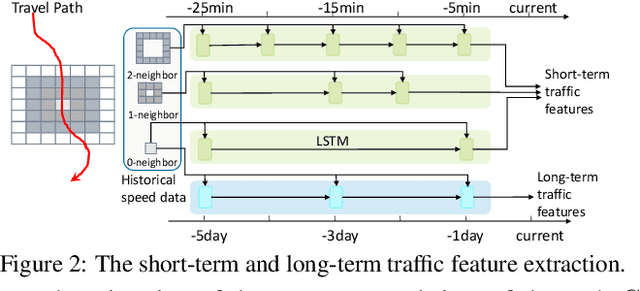
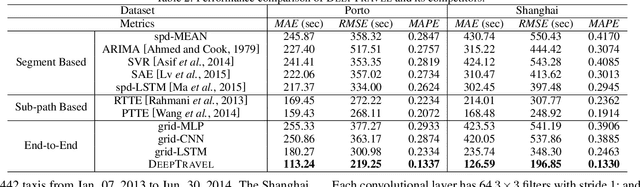
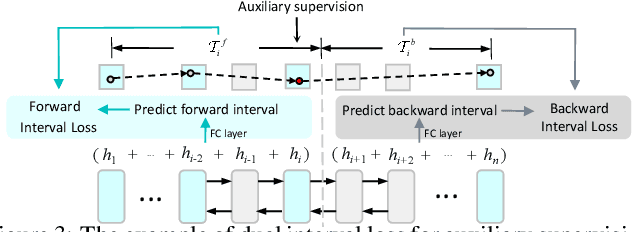
Estimating the travel time of a path is of great importance to smart urban mobility. Existing approaches are either based on estimating the time cost of each road segment which are not able to capture many cross-segment complex factors, or designed heuristically in a non-learning-based way which fail to utilize the existing abundant temporal labels of the data, i.e., the time stamp of each trajectory point. In this paper, we leverage on new development of deep neural networks and propose a novel auxiliary supervision model, namely DeepTravel, that can automatically and effectively extract different features, as well as make full use of the temporal labels of the trajectory data. We have conducted comprehensive experiments on real datasets to demonstrate the out-performance of DeepTravel over existing approaches.