 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Proximal Policy Optimization: mini-critics boost LLM reasoning
Oct 02, 2025Most recent RL for LLMs (RL4LLM) methods avoid explicit critics, replacing them with average advantage baselines. This shift is largely pragmatic: conventional value functions are computationally expensive to train at LLM scale and often fail under sparse rewards and long reasoning horizons. We revisit this bottleneck from an architectural perspective and introduce Asymmetric Proximal Policy Optimization (AsyPPO), a simple and scalable framework that restores the critics role while remaining efficient in large-model settings. AsyPPO employs a set of lightweight mini-critics, each trained on disjoint prompt shards. This design encourages diversity while preserving calibration, reducing value-estimation bias. Beyond robust estimation, AsyPPO leverages inter-critic uncertainty to refine the policy update: (i) masking advantages in states where critics agree and gradients add little learning signal, and (ii) filtering high-divergence states from entropy regularization, suppressing spurious exploration. After training on open-source data with only 5,000 samples, AsyPPO consistently improves learning stability and performance across multiple benchmarks over strong baselines, such as GRPO, achieving performance gains of more than six percent on Qwen3-4b-Base and about three percent on Qwen3-8b-Base and Qwen3-14b-Base over classic PPO, without additional tricks. These results highlight the importance of architectural innovations for scalable, efficient algorithms.
Clustering and Mining Accented Speech for Inclusive and Fair Speech Recognition
Aug 05, 2024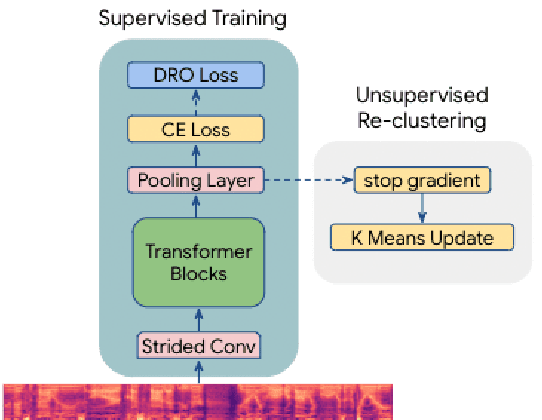
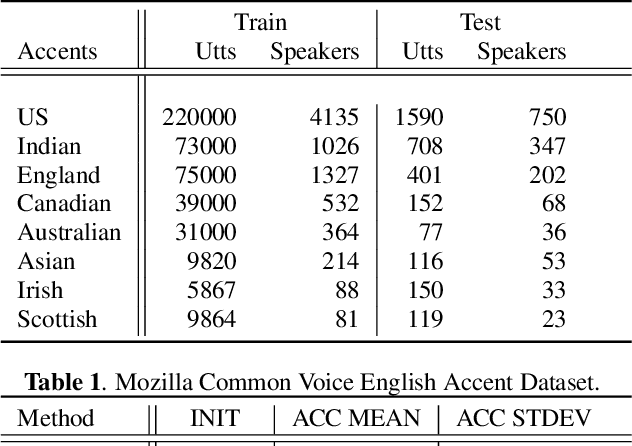
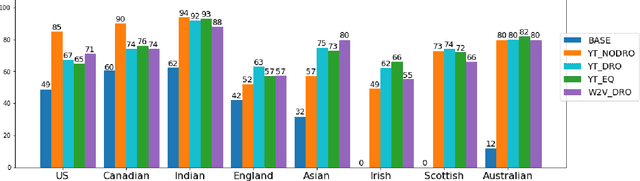

Modern automatic speech recognition (ASR) systems are typically trained on more than tens of thousands hours of speech data, which is one of the main factors for their great success. However, the distribution of such data is typically biased towards common accents or typical speech patterns. As a result, those systems often poorly perform on atypical accented speech. In this paper, we present accent clustering and mining schemes for fair speech recognition systems which can perform equally well on under-represented accented speech. For accent recognition, we applied three schemes to overcome limited size of supervised accent data: supervised or unsupervised pre-training, distributionally robust optimization (DRO) and unsupervised clustering. Three schemes can significantly improve the accent recognition model especially for unbalanced and small accented speech. Fine-tuning ASR on the mined Indian accent speech using the proposed supervised or unsupervised clustering schemes showed 10.0% and 5.3% relative improvements compared to fine-tuning on the randomly sampled speech, respectively.
Fuzzy K-Means Clustering without Cluster Centroids
Apr 07, 2024Fuzzy K-Means clustering is a critical technique in unsupervised data analysis. However, the performance of popular Fuzzy K-Means algorithms is sensitive to the selection of initial cluster centroids and is also affected by noise when updating mean cluster centroids. To address these challenges, this paper proposes a novel Fuzzy K-Means clustering algorithm that entirely eliminates the reliance on cluster centroids, obtaining membership matrices solely through distance matrix computation. This innovation enhances flexibility in distance measurement between sample points, thus improving the algorithm's performance and robustness. The paper also establishes theoretical connections between the proposed model and popular Fuzzy K-Means clustering techniques. Experimental results on several real datasets demonstrate the effectiveness of the algorithm.
YNetr: Dual-Encoder architecture on Plain Scan Liver Tumors
Mar 30, 2024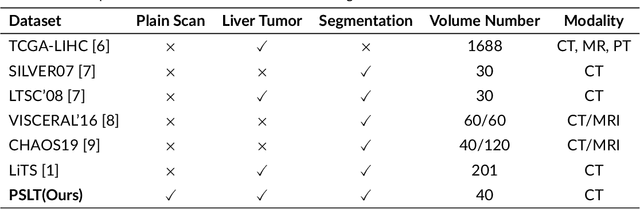

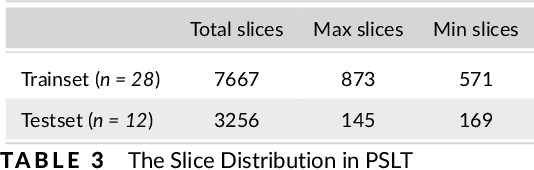
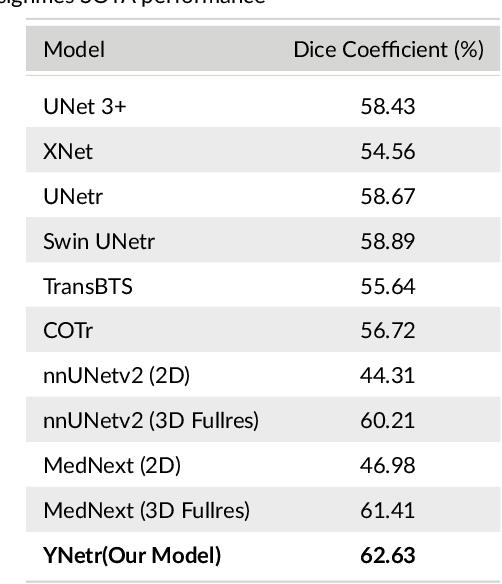
Background: Liver tumors are abnormal growths in the liver that can be either benign or malignant, with liver cancer being a significant health concern worldwide. However, there is no dataset for plain scan segmentation of liver tumors, nor any related algorithms. To fill this gap, we propose Plain Scan Liver Tumors(PSLT) and YNetr. Methods: A collection of 40 liver tumor plain scan segmentation datasets was assembled and annotated. Concurrently, we utilized Dice coefficient as the metric for assessing the segmentation outcomes produced by YNetr, having advantage of capturing different frequency information. Results: The YNetr model achieved a Dice coefficient of 62.63% on the PSLT dataset, surpassing the other publicly available model by an accuracy margin of 1.22%. Comparative evaluations were conducted against a range of models including UNet 3+, XNet, UNetr, Swin UNetr, Trans-BTS, COTr, nnUNetv2 (2D), nnUNetv2 (3D fullres), MedNext (2D) and MedNext(3D fullres). Conclusions: We not only proposed a dataset named PSLT(Plain Scan Liver Tumors), but also explored a structure called YNetr that utilizes wavelet transform to extract different frequency information, which having the SOTA in PSLT by experiments.
Boundary Matters: A Bi-Level Active Finetuning Framework
Mar 15, 2024



The pretraining-finetuning paradigm has gained widespread adoption in vision tasks and other fields, yet it faces the significant challenge of high sample annotation costs. To mitigate this, the concept of active finetuning has emerged, aiming to select the most appropriate samples for model finetuning within a limited budget. Traditional active learning methods often struggle in this setting due to their inherent bias in batch selection. Furthermore, the recent active finetuning approach has primarily concentrated on aligning the distribution of selected subsets with the overall data pool, focusing solely on diversity. In this paper, we propose a Bi-Level Active Finetuning framework to select the samples for annotation in one shot, which includes two stages: core sample selection for diversity, and boundary sample selection for uncertainty. The process begins with the identification of pseudo-class centers, followed by an innovative denoising method and an iterative strategy for boundary sample selection in the high-dimensional feature space, all without relying on ground-truth labels. Our comprehensive experiments provide both qualitative and quantitative evidence of our method's efficacy, outperforming all the existing baselines.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
ActiveAD: Planning-Oriented Active Learning for End-to-End Autonomous Driving
Mar 05, 2024End-to-end differentiable learning for autonomous driving (AD) has recently become a prominent paradigm. One main bottleneck lies in its voracious appetite for high-quality labeled data e.g. 3D bounding boxes and semantic segmentation, which are notoriously expensive to manually annotate. The difficulty is further pronounced due to the prominent fact that the behaviors within samples in AD often suffer from long tailed distribution. In other words, a large part of collected data can be trivial (e.g. simply driving forward in a straight road) and only a few cases are safety-critical. In this paper, we explore a practically important yet under-explored problem about how to achieve sample and label efficiency for end-to-end AD. Specifically, we design a planning-oriented active learning method which progressively annotates part of collected raw data according to the proposed diversity and usefulness criteria for planning routes. Empirically, we show that our planning-oriented approach could outperform general active learning methods by a large margin. Notably, our method achieves comparable performance with state-of-the-art end-to-end AD methods - by using only 30% nuScenes data. We hope our work could inspire future works to explore end-to-end AD from a data-centric perspective in addition to methodology efforts.
Rethinking Classifier Re-Training in Long-Tailed Recognition: A Simple Logits Retargeting Approach
Mar 01, 2024



In the long-tailed recognition field, the Decoupled Training paradigm has demonstrated remarkable capabilities among various methods. This paradigm decouples the training process into separate representation learning and classifier re-training. Previous works have attempted to improve both stages simultaneously, making it difficult to isolate the effect of classifier re-training. Furthermore, recent empirical studies have demonstrated that simple regularization can yield strong feature representations, emphasizing the need to reassess existing classifier re-training methods. In this study, we revisit classifier re-training methods based on a unified feature representation and re-evaluate their performances. We propose a new metric called Logits Magnitude as a superior measure of model performance, replacing the commonly used Weight Norm. However, since it is hard to directly optimize the new metric during training, we introduce a suitable approximate invariant called Regularized Standard Deviation. Based on the two newly proposed metrics, we prove that reducing the absolute value of Logits Magnitude when it is nearly balanced can effectively decrease errors and disturbances during training, leading to better model performance. Motivated by these findings, we develop a simple logits retargeting approach (LORT) without the requirement of prior knowledge of the number of samples per class. LORT divides the original one-hot label into small true label probabilities and large negative label probabilities distributed across each class. Our method achieves state-of-the-art performance on various imbalanced datasets, including CIFAR100-LT, ImageNet-LT, and iNaturalist2018.
Multitask Multilingual Model Adaptation with Featurized Low-Rank Mixtures
Feb 27, 2024Adapting pretrained large language models (LLMs) to various downstream tasks in tens or hundreds of human languages is computationally expensive. Parameter-efficient fine-tuning (PEFT) significantly reduces the adaptation cost, by tuning only a small amount of parameters. However, directly applying PEFT methods such as LoRA (Hu et al., 2022) on diverse dataset mixtures could lead to suboptimal performance due to limited parameter capacity and negative interference among different datasets. In this work, we propose Featurized Low-rank Mixtures (FLix), a novel PEFT method designed for effective multitask multilingual tuning. FLix associates each unique dataset feature, such as the dataset's language or task, with its own low-rank weight update parameters. By composing feature-specific parameters for each dataset, FLix can accommodate diverse dataset mixtures and generalize better to unseen datasets. Our experiments show that FLix leads to significant improvements over a variety of tasks for both supervised learning and zero-shot settings using different training data mixtures.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.