 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering and Mining Accented Speech for Inclusive and Fair Speech Recognition
Paper and Code
Aug 05, 2024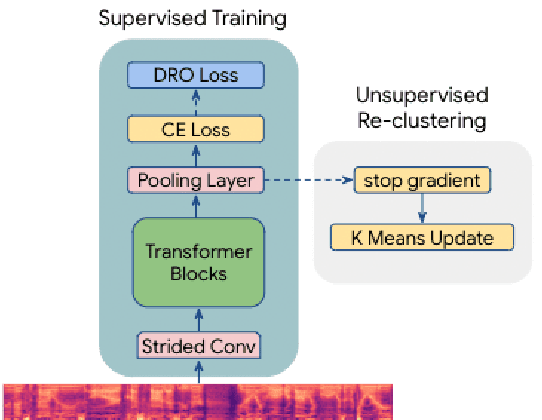
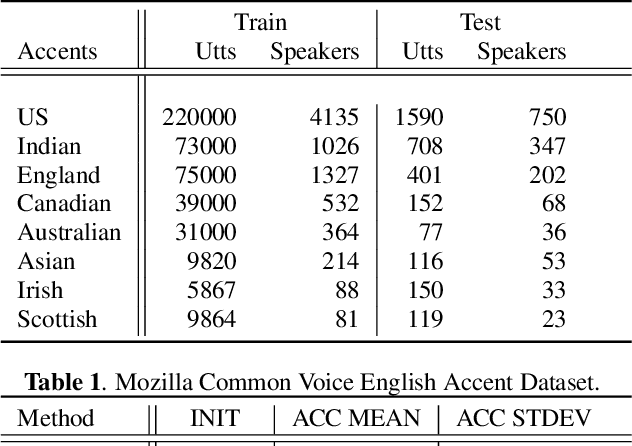
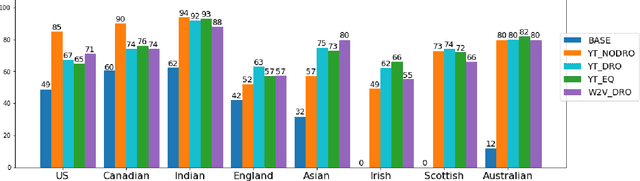

Modern automatic speech recognition (ASR) systems are typically trained on more than tens of thousands hours of speech data, which is one of the main factors for their great success. However, the distribution of such data is typically biased towards common accents or typical speech patterns. As a result, those systems often poorly perform on atypical accented speech. In this paper, we present accent clustering and mining schemes for fair speech recognition systems which can perform equally well on under-represented accented speech. For accent recognition, we applied three schemes to overcome limited size of supervised accent data: supervised or unsupervised pre-training, distributionally robust optimization (DRO) and unsupervised clustering. Three schemes can significantly improve the accent recognition model especially for unbalanced and small accented speech. Fine-tuning ASR on the mined Indian accent speech using the proposed supervised or unsupervised clustering schemes showed 10.0% and 5.3% relative improvements compared to fine-tuning on the randomly sampled speech, respectively.