 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEXOP: A Device for Robotic Transfer of Dexterous Human Manipulation
Sep 04, 2025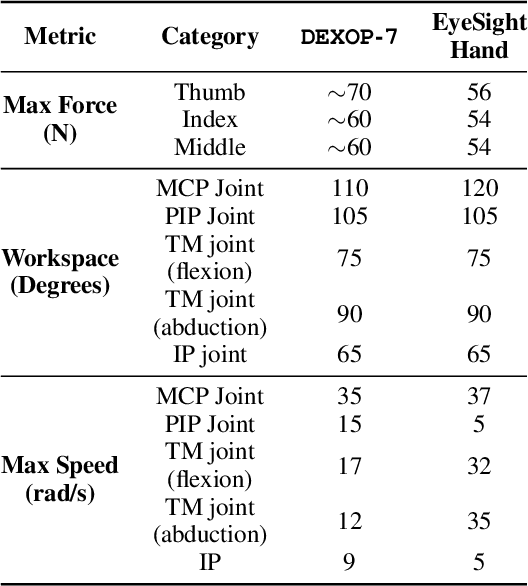
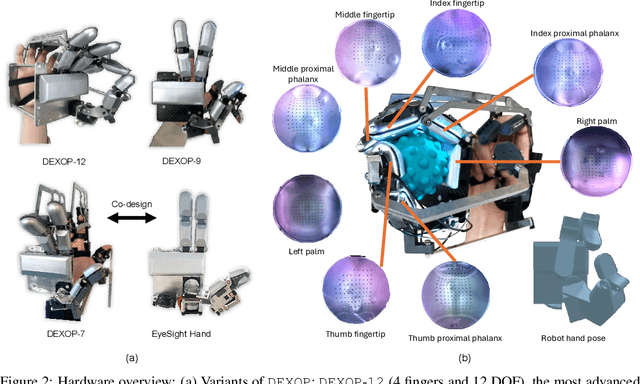

We introduce perioperation, a paradigm for robotic data collection that sensorizes and records human manipulation while maximizing the transferability of the data to real robots. We implement this paradigm in DEXOP, a passive hand exoskeleton designed to maximize human ability to collect rich sensory (vision + tactile) data for diverse dexterous manipulation tasks in natural environments. DEXOP mechanically connects human fingers to robot fingers, providing users with direct contact feedback (via proprioception) and mirrors the human hand pose to the passive robot hand to maximize the transfer of demonstrated skills to the robot. The force feedback and pose mirroring make task demonstrations more natural for humans compared to teleoperation, increasing both speed and accuracy. We evaluate DEXOP across a range of dexterous, contact-rich tasks, demonstrating its ability to collect high-quality demonstration data at scale. Policies learned with DEXOP data significantly improve task performance per unit time of data collection compared to teleoperation, making DEXOP a powerful tool for advancing robot dexterity. Our project page is at https://dex-op.github.io.
S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Modelwith Spatio-Temporal Visual Representation
May 30, 2025

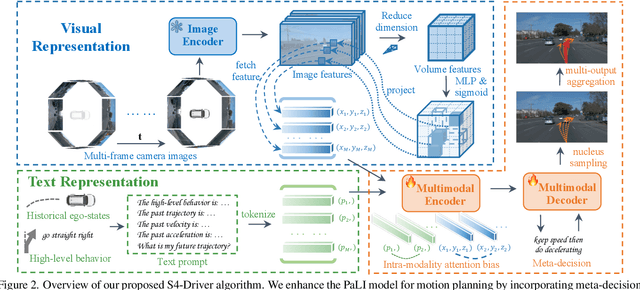

The latest advancements in multi-modal large language models (MLLMs) have spurred a strong renewed interest in end-to-end motion planning approaches for autonomous driving. Many end-to-end approaches rely on human annotations to learn intermediate perception and prediction tasks, while purely self-supervised approaches--which directly learn from sensor inputs to generate planning trajectories without human annotations often underperform the state of the art. We observe a key gap in the input representation space: end-to-end approaches built on MLLMs are often pretrained with reasoning tasks in 2D image space rather than the native 3D space in which autonomous vehicles plan. To this end, we propose S4-Driver, a scalable self-supervised motion planning algorithm with spatio-temporal visual representation, based on the popular PaLI multimodal large language model. S4-Driver uses a novel sparse volume strategy to seamlessly transform the strong visual representation of MLLMs from perspective view to 3D space without the need to finetune the vision encoder. This representation aggregates multi-view and multi-frame visual inputs and enables better prediction of planning trajectories in 3D space. To validate our method, we run experiments on both nuScenes and Waymo Open Motion Dataset (with in-house camera data). Results show that S4-Driver performs favorably against existing supervised multi-task approaches while requiring no human annotations. It also demonstrates great scalability when pretrained on large volumes of unannotated driving logs.
DexCtrl: Towards Sim-to-Real Dexterity with Adaptive Controller Learning
May 02, 2025


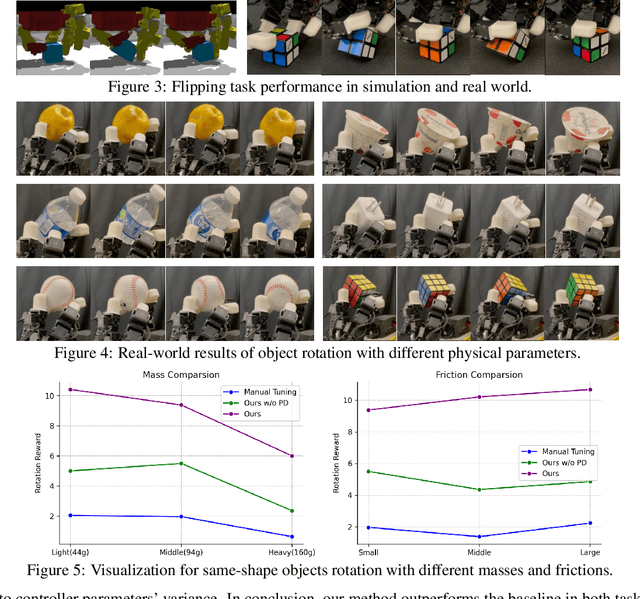
Dexterous manipulation has seen remarkable progress in recent years, with policies capable of executing many complex and contact-rich tasks in simulation. However, transferring these policies from simulation to real world remains a significant challenge. One important issue is the mismatch in low-level controller dynamics, where identical trajectories can lead to vastly different contact forces and behaviors when control parameters vary. Existing approaches often rely on manual tuning or controller randomization, which can be labor-intensive, task-specific, and introduce significant training difficulty. In this work, we propose a framework that jointly learns actions and controller parameters based on the historical information of both trajectory and controller. This adaptive controller adjustment mechanism allows the policy to automatically tune control parameters during execution, thereby mitigating the sim-to-real gap without extensive manual tuning or excessive randomization. Moreover, by explicitly providing controller parameters as part of the observation, our approach facilitates better reasoning over force interactions and improves robustness in real-world scenarios. Experimental results demonstrate that our method achieves improved transfer performance across a variety of dexterous tasks involving variable force conditions.
DeSiRe-GS: 4D Street Gaussians for Static-Dynamic Decomposition and Surface Reconstruction for Urban Driving Scenes
Nov 18, 2024



We present DeSiRe-GS, a self-supervised gaussian splatting representation, enabling effective static-dynamic decomposition and high-fidelity surface reconstruction in complex driving scenarios. Our approach employs a two-stage optimization pipeline of dynamic street Gaussians. In the first stage, we extract 2D motion masks based on the observation that 3D Gaussian Splatting inherently can reconstruct only the static regions in dynamic environments. These extracted 2D motion priors are then mapped into the Gaussian space in a differentiable manner, leveraging an efficient formulation of dynamic Gaussians in the second stage. Combined with the introduced geometric regularizations, our method are able to address the over-fitting issues caused by data sparsity in autonomous driving, reconstructing physically plausible Gaussians that align with object surfaces rather than floating in air. Furthermore, we introduce temporal cross-view consistency to ensure coherence across time and viewpoints, resulting in high-quality surface reconstruction. Comprehensive experiments demonstrate the efficiency and effectiveness of DeSiRe-GS, surpassing prior self-supervised arts and achieving accuracy comparable to methods relying on external 3D bounding box annotations. Code is available at \url{https://github.com/chengweialan/DeSiRe-GS}
X-Drive: Cross-modality consistent multi-sensor data synthesis for driving scenarios
Nov 02, 2024



Recent advancements have exploited diffusion models for the synthesis of either LiDAR point clouds or camera image data in driving scenarios. Despite their success in modeling single-modality data marginal distribution, there is an under-exploration in the mutual reliance between different modalities to describe complex driving scenes. To fill in this gap, we propose a novel framework, X-DRIVE, to model the joint distribution of point clouds and multi-view images via a dual-branch latent diffusion model architecture. Considering the distinct geometrical spaces of the two modalities, X-DRIVE conditions the synthesis of each modality on the corresponding local regions from the other modality, ensuring better alignment and realism. To further handle the spatial ambiguity during denoising, we design the cross-modality condition module based on epipolar lines to adaptively learn the cross-modality local correspondence. Besides, X-DRIVE allows for controllable generation through multi-level input conditions, including text, bounding box, image, and point clouds. Extensive results demonstrate the high-fidelity synthetic results of X-DRIVE for both point clouds and multi-view images, adhering to input conditions while ensuring reliable cross-modality consistency. Our code will be made publicly available at https://github.com/yichen928/X-Drive.
TrajSSL: Trajectory-Enhanced Semi-Supervised 3D Object Detection
Sep 17, 2024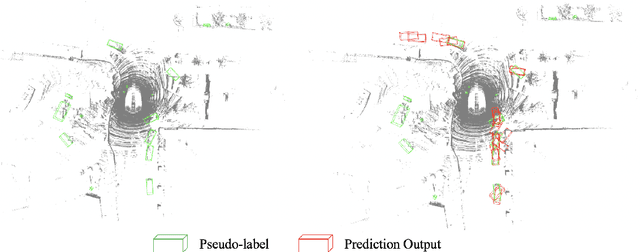
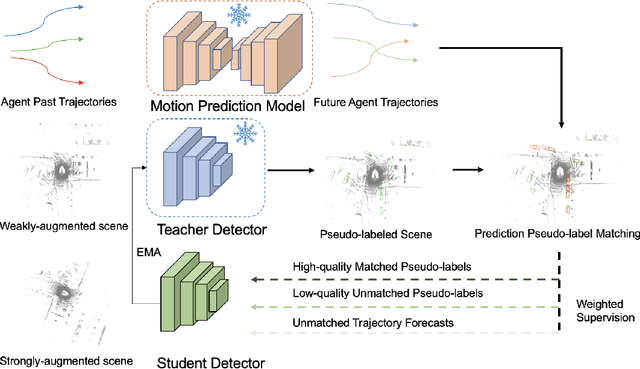
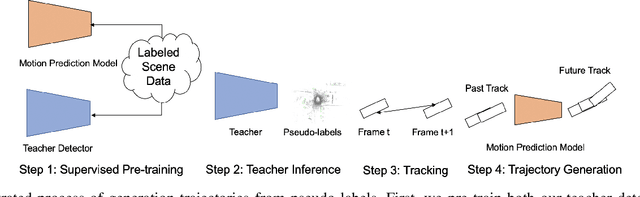
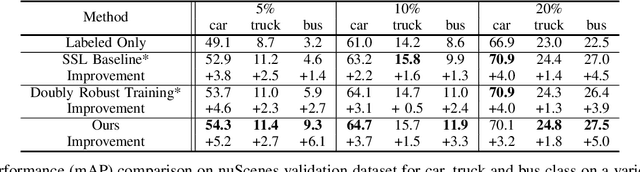
Semi-supervised 3D object detection is a common strategy employed to circumvent the challenge of manually labeling large-scale autonomous driving perception datasets. Pseudo-labeling approaches to semi-supervised learning adopt a teacher-student framework in which machine-generated pseudo-labels on a large unlabeled dataset are used in combination with a small manually-labeled dataset for training. In this work, we address the problem of improving pseudo-label quality through leveraging long-term temporal information captured in driving scenes. More specifically, we leverage pre-trained motion-forecasting models to generate object trajectories on pseudo-labeled data to further enhance the student model training. Our approach improves pseudo-label quality in two distinct manners: first, we suppress false positive pseudo-labels through establishing consistency across multiple frames of motion forecasting outputs. Second, we compensate for false negative detections by directly inserting predicted object tracks into the pseudo-labeled scene. Experiments on the nuScenes dataset demonstrate the effectiveness of our approach, improving the performance of standard semi-supervised approaches in a variety of settings.
Optimizing Diffusion Models for Joint Trajectory Prediction and Controllable Generation
Aug 01, 2024



Diffusion models are promising for joint trajectory prediction and controllable generation in autonomous driving, but they face challenges of inefficient inference steps and high computational demands. To tackle these challenges, we introduce Optimal Gaussian Diffusion (OGD) and Estimated Clean Manifold (ECM) Guidance. OGD optimizes the prior distribution for a small diffusion time $T$ and starts the reverse diffusion process from it. ECM directly injects guidance gradients to the estimated clean manifold, eliminating extensive gradient backpropagation throughout the network. Our methodology streamlines the generative process, enabling practical applications with reduced computational overhead. Experimental validation on the large-scale Argoverse 2 dataset demonstrates our approach's superior performance, offering a viable solution for computationally efficient, high-quality joint trajectory prediction and controllable generation for autonomous driving. Our project webpage is at https://yixiaowang7.github.io/OptTrajDiff_Page/.
Sparse Diffusion Policy: A Sparse, Reusable, and Flexible Policy for Robot Learning
Jul 01, 2024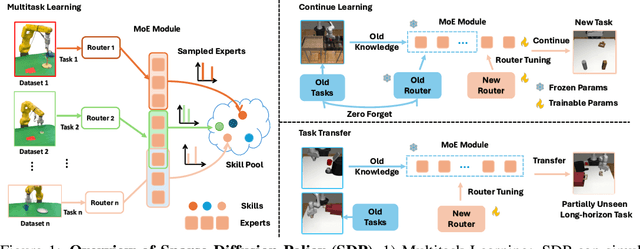

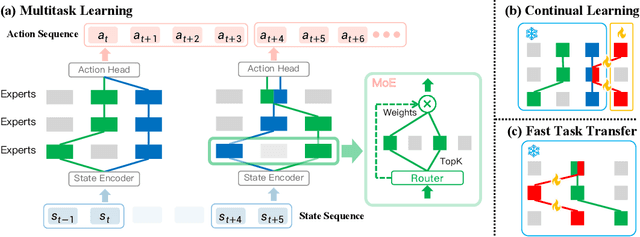

The increasing complexity of tasks in robotics demands efficient strategies for multitask and continual learning. Traditional models typically rely on a universal policy for all tasks, facing challenges such as high computational costs and catastrophic forgetting when learning new tasks. To address these issues, we introduce a sparse, reusable, and flexible policy, Sparse Diffusion Policy (SDP). By adopting Mixture of Experts (MoE) within a transformer-based diffusion policy, SDP selectively activates experts and skills, enabling efficient and task-specific learning without retraining the entire model. SDP not only reduces the burden of active parameters but also facilitates the seamless integration and reuse of experts across various tasks. Extensive experiments on diverse tasks in both simulations and real world show that SDP 1) excels in multitask scenarios with negligible increases in active parameters, 2) prevents forgetting in continual learning of new tasks, and 3) enables efficient task transfer, offering a promising solution for advanced robotic applications. Demos and codes can be found in https://forrest-110.github.io/sparse_diffusion_policy/.
RoadBEV: Road Surface Reconstruction in Bird's Eye View
Apr 09, 2024

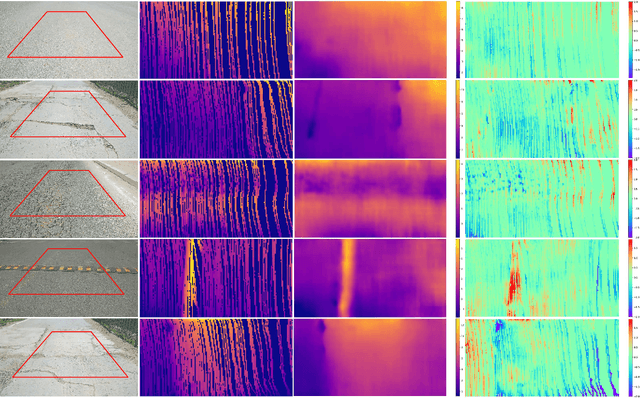

Road surface conditions, especially geometry profiles, enormously affect driving performance of autonomous vehicles. Vision-based online road reconstruction promisingly captures road information in advance. Existing solutions like monocular depth estimation and stereo matching suffer from modest performance. The recent technique of Bird's-Eye-View (BEV) perception provides immense potential to more reliable and accurate reconstruction. This paper uniformly proposes two simple yet effective models for road elevation reconstruction in BEV named RoadBEV-mono and RoadBEV-stereo, which estimate road elevation with monocular and stereo images, respectively. The former directly fits elevation values based on voxel features queried from image view, while the latter efficiently recognizes road elevation patterns based on BEV volume representing discrepancy between left and right voxel features. Insightful analyses reveal their consistence and difference with perspective view. Experiments on real-world dataset verify the models' effectiveness and superiority. Elevation errors of RoadBEV-mono and RoadBEV-stereo achieve 1.83cm and 0.56cm, respectively. The estimation performance improves by 50\% in BEV based on monocular image. Our models are promising for practical applications, providing valuable references for vision-based BEV perception in autonomous driving. The code is released at https://github.com/ztsrxh/RoadBEV.
Boundary Matters: A Bi-Level Active Finetuning Framework
Mar 15, 2024



The pretraining-finetuning paradigm has gained widespread adoption in vision tasks and other fields, yet it faces the significant challenge of high sample annotation costs. To mitigate this, the concept of active finetuning has emerged, aiming to select the most appropriate samples for model finetuning within a limited budget. Traditional active learning methods often struggle in this setting due to their inherent bias in batch selection. Furthermore, the recent active finetuning approach has primarily concentrated on aligning the distribution of selected subsets with the overall data pool, focusing solely on diversity. In this paper, we propose a Bi-Level Active Finetuning framework to select the samples for annotation in one shot, which includes two stages: core sample selection for diversity, and boundary sample selection for uncertainty. The process begins with the identification of pseudo-class centers, followed by an innovative denoising method and an iterative strategy for boundary sample selection in the high-dimensional feature space, all without relying on ground-truth labels. Our comprehensive experiments provide both qualitative and quantitative evidence of our method's efficacy, outperforming all the existing baselines.