 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCohere3D: Exploiting Temporal Coherence for Unsupervised Representation Learning of Vision-based Autonomous Driving
Paper and Code
Feb 23, 2024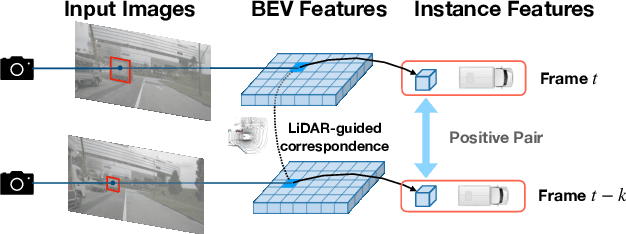
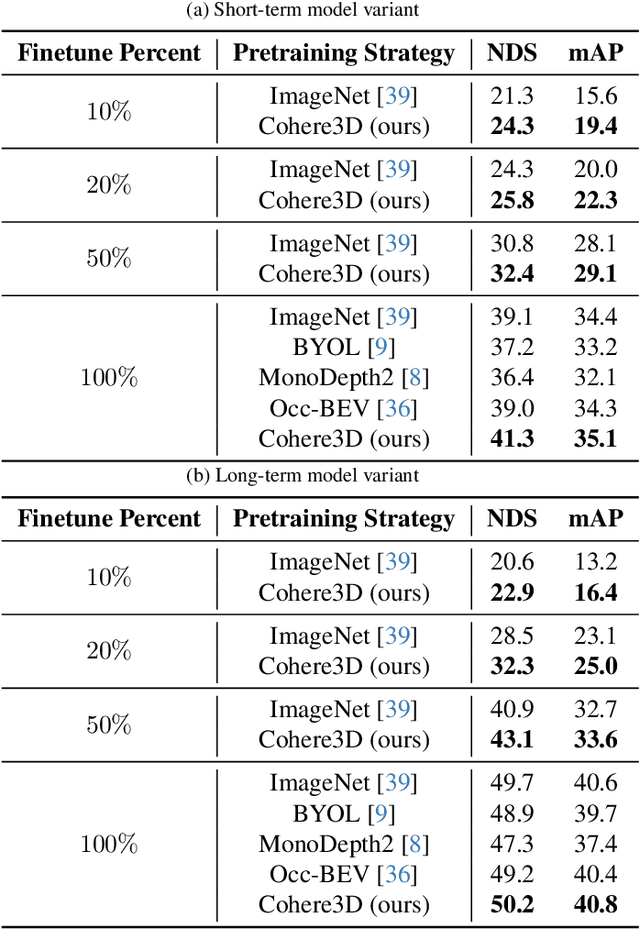
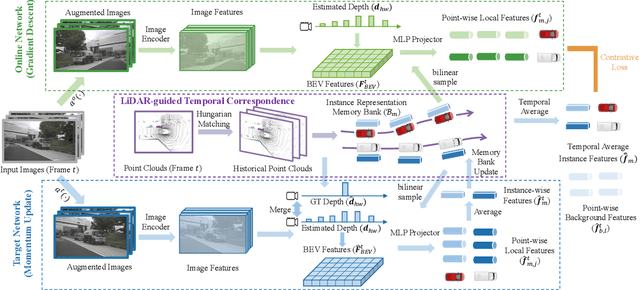

Due to the lack of depth cues in images, multi-frame inputs are important for the success of vision-based perception, prediction, and planning in autonomous driving. Observations from different angles enable the recovery of 3D object states from 2D image inputs if we can identify the same instance in different input frames. However, the dynamic nature of autonomous driving scenes leads to significant changes in the appearance and shape of each instance captured by the camera at different time steps. To this end, we propose a novel contrastive learning algorithm, Cohere3D, to learn coherent instance representations in a long-term input sequence robust to the change in distance and perspective. The learned representation aids in instance-level correspondence across multiple input frames in downstream tasks. In the pretraining stage, the raw point clouds from LiDAR sensors are utilized to construct the long-term temporal correspondence for each instance, which serves as guidance for the extraction of instance-level representation from the vision-based bird's eye-view (BEV) feature map. Cohere3D encourages a consistent representation for the same instance at different frames but distinguishes between representations of different instances. We evaluate our algorithm by finetuning the pretrained model on various downstream perception, prediction, and planning tasks. Results show a notable improvement in both data efficiency and task performance.