 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoAVU: Egocentric Audio-Visual Understanding
Feb 05, 2026Understanding egocentric videos plays a vital role for embodied intelligence. Recent multi-modal large language models (MLLMs) can accept both visual and audio inputs. However, due to the challenge of obtaining text labels with coherent joint-modality information, whether MLLMs can jointly understand both modalities in egocentric videos remains under-explored. To address this problem, we introduce EgoAVU, a scalable data engine to automatically generate egocentric audio-visual narrations, questions, and answers. EgoAVU enriches human narrations with multimodal context and generates audio-visual narrations through cross-modal correlation modeling. Token-based video filtering and modular, graph-based curation ensure both data diversity and quality. Leveraging EgoAVU, we construct EgoAVU-Instruct, a large-scale training dataset of 3M samples, and EgoAVU-Bench, a manually verified evaluation split covering diverse tasks. EgoAVU-Bench clearly reveals the limitations of existing MLLMs: they bias heavily toward visual signals, often neglecting audio cues or failing to correspond audio with the visual source. Finetuning MLLMs on EgoAVU-Instruct effectively addresses this issue, enabling up to 113% performance improvement on EgoAVU-Bench. Such benefits also transfer to other benchmarks such as EgoTempo and EgoIllusion, achieving up to 28% relative performance gain. Code will be released to the community.
Generative Data Mining with Longtail-Guided Diffusion
Feb 04, 2025
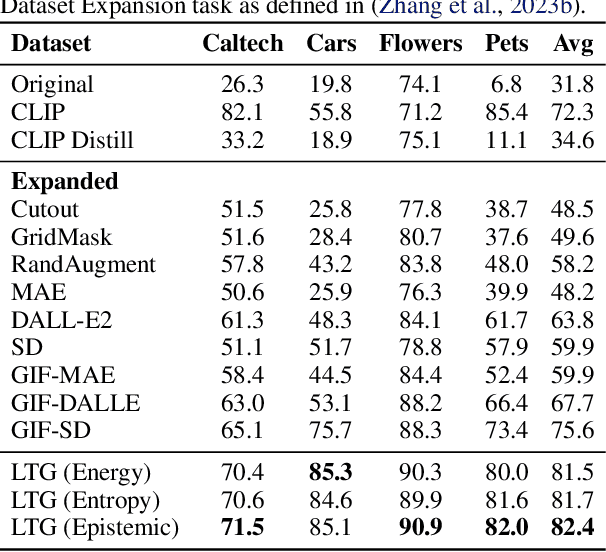
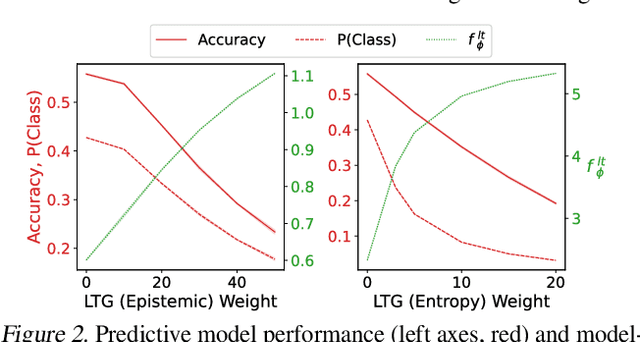
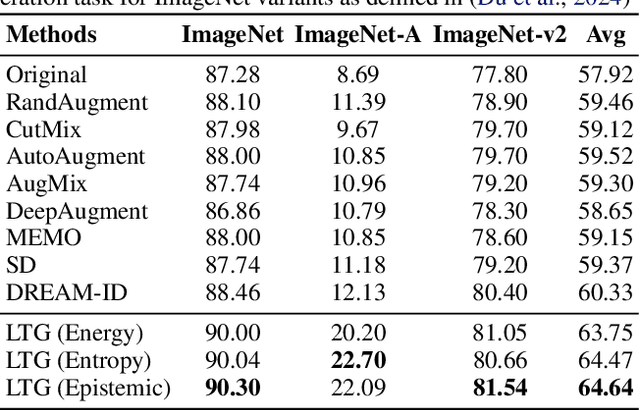
It is difficult to anticipate the myriad challenges that a predictive model will encounter once deployed. Common practice entails a reactive, cyclical approach: model deployment, data mining, and retraining. We instead develop a proactive longtail discovery process by imagining additional data during training. In particular, we develop general model-based longtail signals, including a differentiable, single forward pass formulation of epistemic uncertainty that does not impact model parameters or predictive performance but can flag rare or hard inputs. We leverage these signals as guidance to generate additional training data from a latent diffusion model in a process we call Longtail Guidance (LTG). Crucially, we can perform LTG without retraining the diffusion model or the predictive model, and we do not need to expose the predictive model to intermediate diffusion states. Data generated by LTG exhibit semantically meaningful variation, yield significant generalization improvements on image classification benchmarks, and can be analyzed to proactively discover, explain, and address conceptual gaps in a predictive model.
Flash3D: Super-scaling Point Transformers through Joint Hardware-Geometry Locality
Dec 21, 2024Recent efforts recognize the power of scale in 3D learning (e.g. PTv3) and attention mechanisms (e.g. FlashAttention). However, current point cloud backbones fail to holistically unify geometric locality, attention mechanisms, and GPU architectures in one view. In this paper, we introduce Flash3D Transformer, which aligns geometric locality and GPU tiling through a principled locality mechanism based on Perfect Spatial Hashing (PSH). The common alignment with GPU tiling naturally fuses our PSH locality mechanism with FlashAttention at negligible extra cost. This mechanism affords flexible design choices throughout the backbone that result in superior downstream task results. Flash3D outperforms state-of-the-art PTv3 results on benchmark datasets, delivering a 2.25x speed increase and 2.4x memory efficiency boost. This efficiency enables scaling to wider attention scopes and larger models without additional overhead. Such scaling allows Flash3D to achieve even higher task accuracies than PTv3 under the same compute budget.
VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision
Dec 19, 2024



Human drivers rely on commonsense reasoning to navigate diverse and dynamic real-world scenarios. Existing end-to-end (E2E) autonomous driving (AD) models are typically optimized to mimic driving patterns observed in data, without capturing the underlying reasoning processes. This limitation constrains their ability to handle challenging driving scenarios. To close this gap, we propose VLM-AD, a method that leverages vision-language models (VLMs) as teachers to enhance training by providing additional supervision that incorporates unstructured reasoning information and structured action labels. Such supervision enhances the model's ability to learn richer feature representations that capture the rationale behind driving patterns. Importantly, our method does not require a VLM during inference, making it practical for real-time deployment. When integrated with state-of-the-art methods, VLM-AD achieves significant improvements in planning accuracy and reduced collision rates on the nuScenes dataset.
VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition
Aug 29, 2024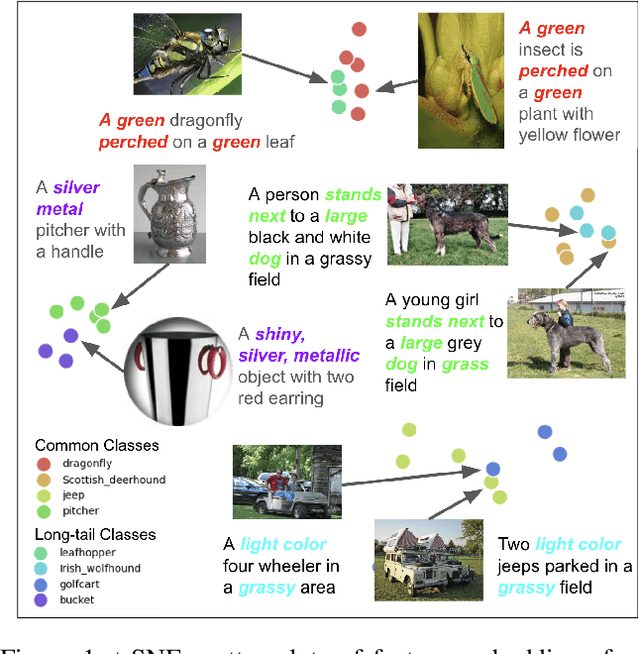
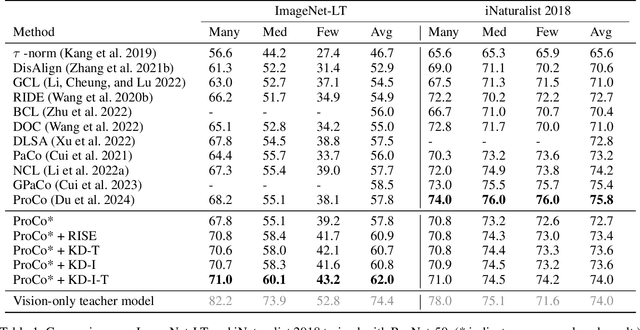
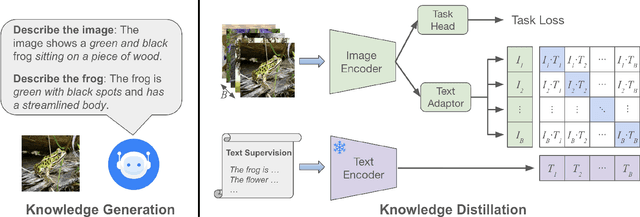
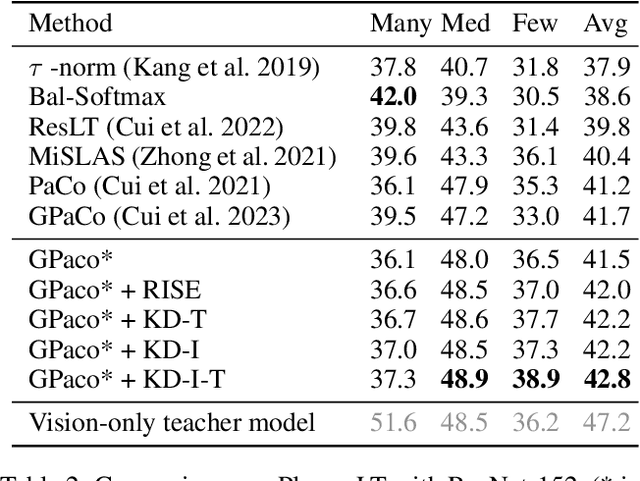
For visual recognition, knowledge distillation typically involves transferring knowledge from a large, well-trained teacher model to a smaller student model. In this paper, we introduce an effective method to distill knowledge from an off-the-shelf vision-language model (VLM), demonstrating that it provides novel supervision in addition to those from a conventional vision-only teacher model. Our key technical contribution is the development of a framework that generates novel text supervision and distills free-form text into a vision encoder. We showcase the effectiveness of our approach, termed VLM-KD, across various benchmark datasets, showing that it surpasses several state-of-the-art long-tail visual classifiers. To our knowledge, this work is the first to utilize knowledge distillation with text supervision generated by an off-the-shelf VLM and apply it to vanilla randomly initialized vision encoders.
Cohere3D: Exploiting Temporal Coherence for Unsupervised Representation Learning of Vision-based Autonomous Driving
Feb 23, 2024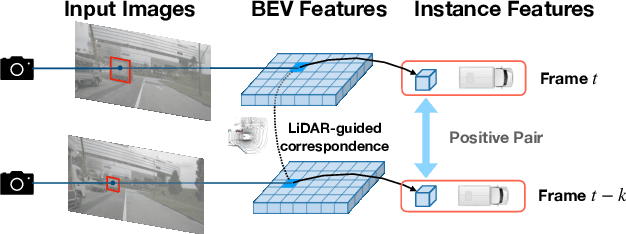
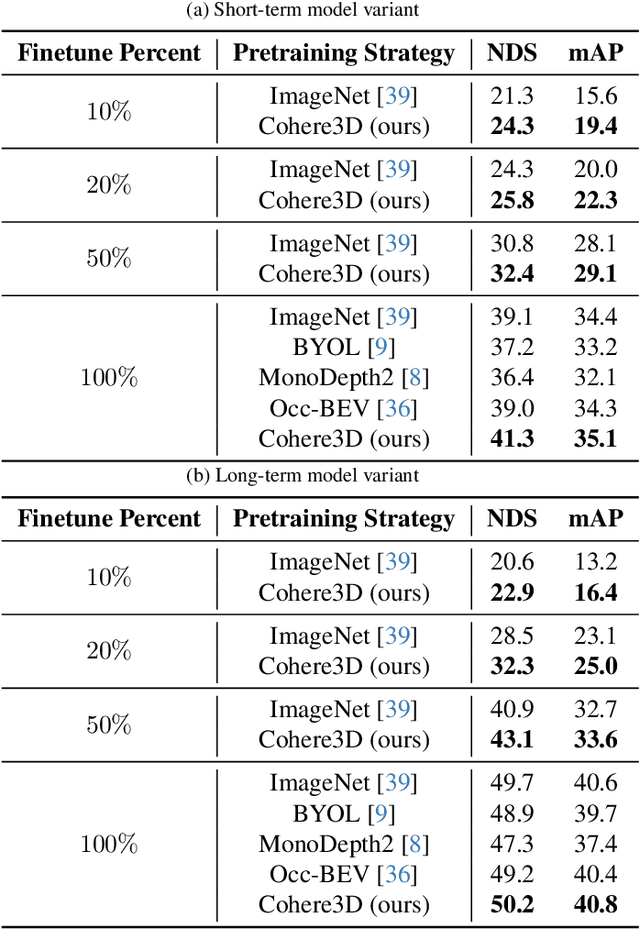
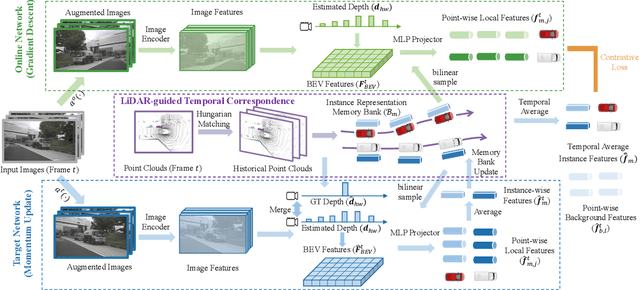

Due to the lack of depth cues in images, multi-frame inputs are important for the success of vision-based perception, prediction, and planning in autonomous driving. Observations from different angles enable the recovery of 3D object states from 2D image inputs if we can identify the same instance in different input frames. However, the dynamic nature of autonomous driving scenes leads to significant changes in the appearance and shape of each instance captured by the camera at different time steps. To this end, we propose a novel contrastive learning algorithm, Cohere3D, to learn coherent instance representations in a long-term input sequence robust to the change in distance and perspective. The learned representation aids in instance-level correspondence across multiple input frames in downstream tasks. In the pretraining stage, the raw point clouds from LiDAR sensors are utilized to construct the long-term temporal correspondence for each instance, which serves as guidance for the extraction of instance-level representation from the vision-based bird's eye-view (BEV) feature map. Cohere3D encourages a consistent representation for the same instance at different frames but distinguishes between representations of different instances. We evaluate our algorithm by finetuning the pretrained model on various downstream perception, prediction, and planning tasks. Results show a notable improvement in both data efficiency and task performance.
Making Large Multimodal Models Understand Arbitrary Visual Prompts
Dec 01, 2023

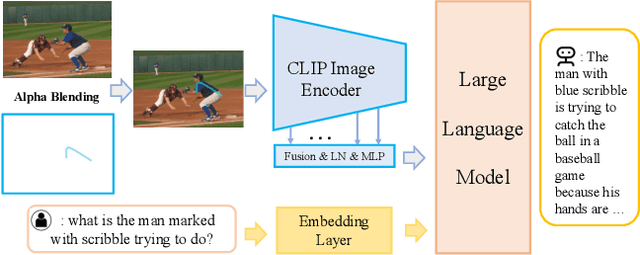

While existing large vision-language multimodal models focus on whole image understanding, there is a prominent gap in achieving region-specific comprehension. Current approaches that use textual coordinates or spatial encodings often fail to provide a user-friendly interface for visual prompting. To address this challenge, we introduce a novel multimodal model capable of decoding arbitrary visual prompts. This allows users to intuitively mark images and interact with the model using natural cues like a "red bounding box" or "pointed arrow". Our simple design directly overlays visual markers onto the RGB image, eliminating the need for complex region encodings, yet achieves state-of-the-art performance on region-understanding tasks like Visual7W, PointQA, and Visual Commonsense Reasoning benchmark. Furthermore, we present ViP-Bench, a comprehensive benchmark to assess the capability of models in understanding visual prompts across multiple dimensions, enabling future research in this domain. Code, data, and model are publicly available.
SHIFT3D: Synthesizing Hard Inputs For Tricking 3D Detectors
Sep 11, 2023



We present SHIFT3D, a differentiable pipeline for generating 3D shapes that are structurally plausible yet challenging to 3D object detectors. In safety-critical applications like autonomous driving, discovering such novel challenging objects can offer insight into unknown vulnerabilities of 3D detectors. By representing objects with a signed distanced function (SDF), we show that gradient error signals allow us to smoothly deform the shape or pose of a 3D object in order to confuse a downstream 3D detector. Importantly, the objects generated by SHIFT3D physically differ from the baseline object yet retain a semantically recognizable shape. Our approach provides interpretable failure modes for modern 3D object detectors, and can aid in preemptive discovery of potential safety risks within 3D perception systems before these risks become critical failures.
Efficient Transformer-based 3D Object Detection with Dynamic Token Halting
Mar 09, 2023Balancing efficiency and accuracy is a long-standing problem for deploying deep learning models. The trade-off is even more important for real-time safety-critical systems like autonomous vehicles. In this paper, we propose an effective approach for accelerating transformer-based 3D object detectors by dynamically halting tokens at different layers depending on their contribution to the detection task. Although halting a token is a non-differentiable operation, our method allows for differentiable end-to-end learning by leveraging an equivalent differentiable forward-pass. Furthermore, our framework allows halted tokens to be reused to inform the model's predictions through a straightforward token recycling mechanism. Our method significantly improves the Pareto frontier of efficiency versus accuracy when compared with the existing approaches. By halting tokens and increasing model capacity, we are able to improve the baseline model's performance without increasing the model's latency on the Waymo Open Dataset.
MultiXNet: Multiclass Multistage Multimodal Motion Prediction
Jun 10, 2020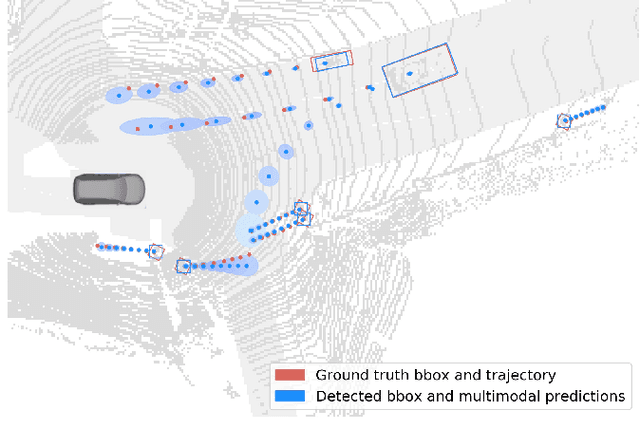
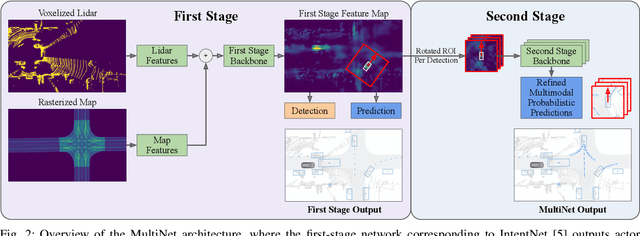
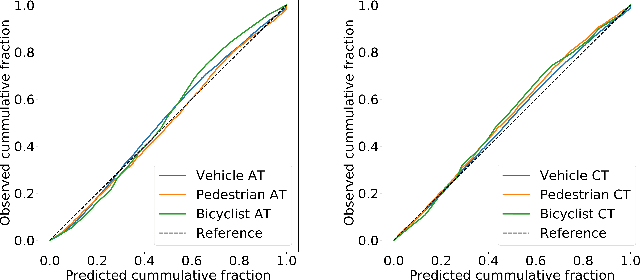
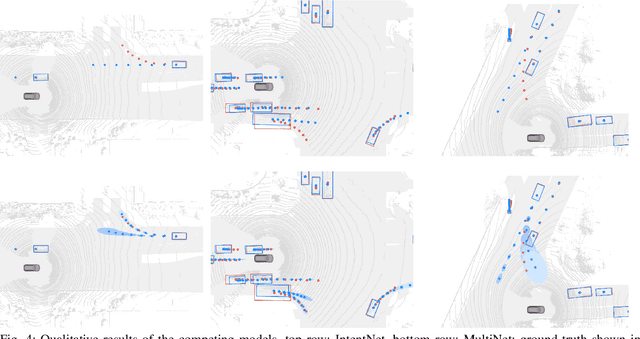
One of the critical pieces of the self-driving puzzle is understanding the surroundings of the self-driving vehicle (SDV) and predicting how these surroundings will change in the near future. To address this task we propose MultiXNet, an end-to-end approach for detection and motion prediction based directly on lidar sensor data. This approach builds on prior work by handling multiple classes of traffic actors, adding a jointly trained second-stage trajectory refinement step, and producing a multimodal probability distribution over future actor motion that includes both multiple discrete traffic behaviors and calibrated continuous uncertainties. The method was evaluated on a large-scale, real-world data set collected by a fleet of SDVs in several cities, with the results indicating that it outperforms existing state-of-the-art approaches.