 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlash3D: Super-scaling Point Transformers through Joint Hardware-Geometry Locality
Dec 21, 2024Recent efforts recognize the power of scale in 3D learning (e.g. PTv3) and attention mechanisms (e.g. FlashAttention). However, current point cloud backbones fail to holistically unify geometric locality, attention mechanisms, and GPU architectures in one view. In this paper, we introduce Flash3D Transformer, which aligns geometric locality and GPU tiling through a principled locality mechanism based on Perfect Spatial Hashing (PSH). The common alignment with GPU tiling naturally fuses our PSH locality mechanism with FlashAttention at negligible extra cost. This mechanism affords flexible design choices throughout the backbone that result in superior downstream task results. Flash3D outperforms state-of-the-art PTv3 results on benchmark datasets, delivering a 2.25x speed increase and 2.4x memory efficiency boost. This efficiency enables scaling to wider attention scopes and larger models without additional overhead. Such scaling allows Flash3D to achieve even higher task accuracies than PTv3 under the same compute budget.
DriveGPT: Scaling Autoregressive Behavior Models for Driving
Dec 19, 2024



We present DriveGPT, a scalable behavior model for autonomous driving. We model driving as a sequential decision making task, and learn a transformer model to predict future agent states as tokens in an autoregressive fashion. We scale up our model parameters and training data by multiple orders of magnitude, enabling us to explore the scaling properties in terms of dataset size, model parameters, and compute. We evaluate DriveGPT across different scales in a planning task, through both quantitative metrics and qualitative examples including closed-loop driving in complex real-world scenarios. In a separate prediction task, DriveGPT outperforms a state-of-the-art baseline and exhibits improved performance by pretraining on a large-scale dataset, further validating the benefits of data scaling.
Hierarchical Metric Learning and Matching for 2D and 3D Geometric Correspondences
Aug 02, 2018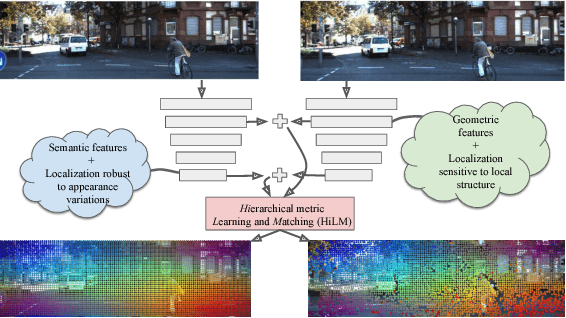
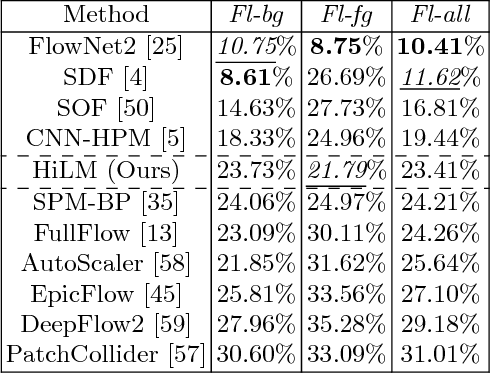
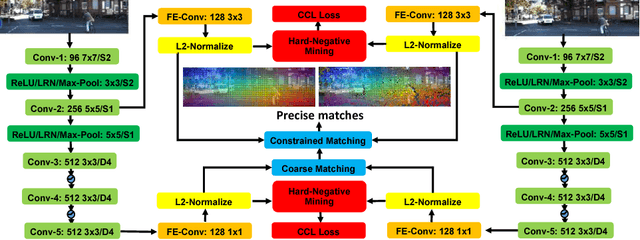
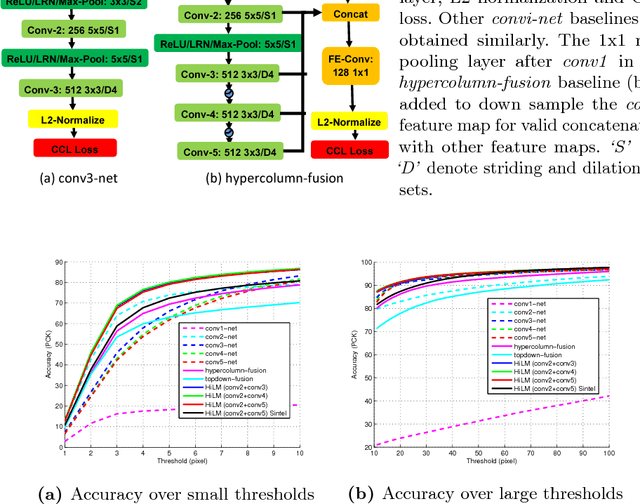
Interest point descriptors have fueled progress on almost every problem in computer vision. Recent advances in deep neural networks have enabled task-specific learned descriptors that outperform hand-crafted descriptors on many problems. We demonstrate that commonly used metric learning approaches do not optimally leverage the feature hierarchies learned in a Convolutional Neural Network (CNN), especially when applied to the task of geometric feature matching. While a metric loss applied to the deepest layer of a CNN, is often expected to yield ideal features irrespective of the task, in fact the growing receptive field as well as striding effects cause shallower features to be better at high precision matching tasks. We leverage this insight together with explicit supervision at multiple levels of the feature hierarchy for better regularization, to learn more effective descriptors in the context of geometric matching tasks. Further, we propose to use activation maps at different layers of a CNN, as an effective and principled replacement for the multi-resolution image pyramids often used for matching tasks. We propose concrete CNN architectures employing these ideas, and evaluate them on multiple datasets for 2D and 3D geometric matching as well as optical flow, demonstrating state-of-the-art results and generalization across datasets.
Learning random-walk label propagation for weakly-supervised semantic segmentation
Feb 01, 2018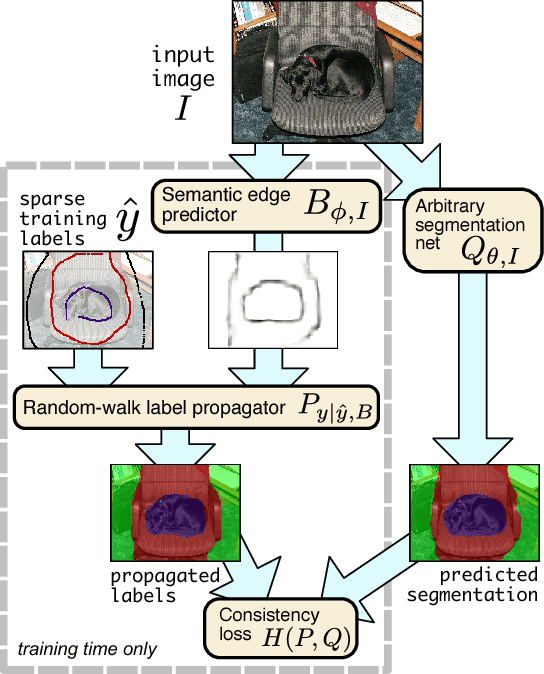

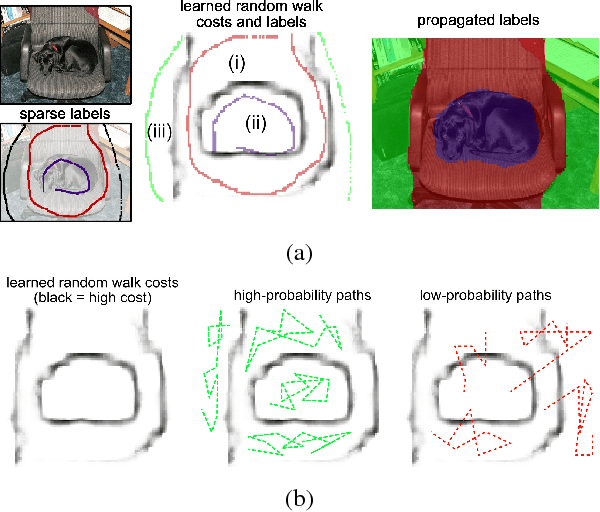

Large-scale training for semantic segmentation is challenging due to the expense of obtaining training data for this task relative to other vision tasks. We propose a novel training approach to address this difficulty. Given cheaply-obtained sparse image labelings, we propagate the sparse labels to produce guessed dense labelings. A standard CNN-based segmentation network is trained to mimic these labelings. The label-propagation process is defined via random-walk hitting probabilities, which leads to a differentiable parameterization with uncertainty estimates that are incorporated into our loss. We show that by learning the label-propagator jointly with the segmentation predictor, we are able to effectively learn semantic edges given no direct edge supervision. Experiments also show that training a segmentation network in this way outperforms the naive approach.
* This is a revised version of a paper presented at CVPR 2017 that corrects some equations. See footnotes
Deep Network Flow for Multi-Object Tracking
Jun 26, 2017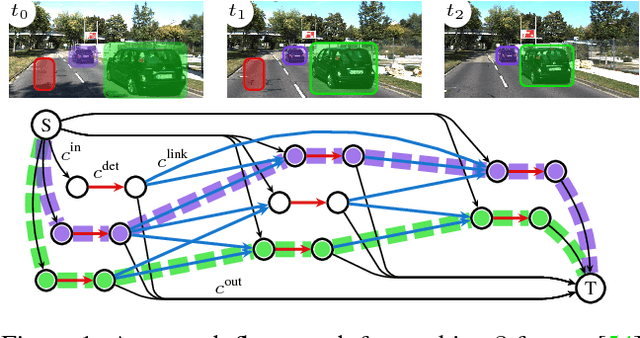
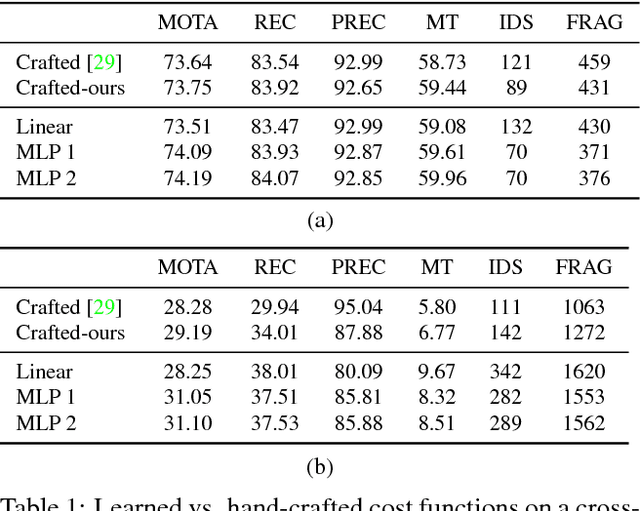
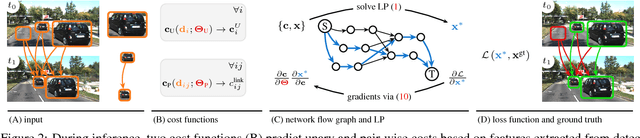
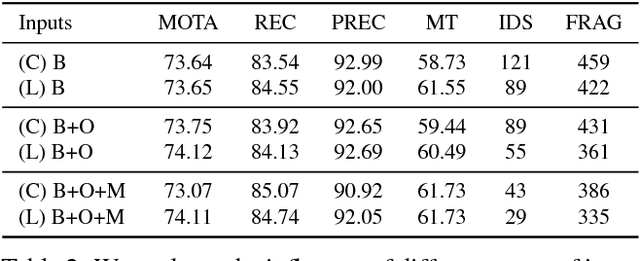
Data association problems are an important component of many computer vision applications, with multi-object tracking being one of the most prominent examples. A typical approach to data association involves finding a graph matching or network flow that minimizes a sum of pairwise association costs, which are often either hand-crafted or learned as linear functions of fixed features. In this work, we demonstrate that it is possible to learn features for network-flow-based data association via backpropagation, by expressing the optimum of a smoothed network flow problem as a differentiable function of the pairwise association costs. We apply this approach to multi-object tracking with a network flow formulation. Our experiments demonstrate that we are able to successfully learn all cost functions for the association problem in an end-to-end fashion, which outperform hand-crafted costs in all settings. The integration and combination of various sources of inputs becomes easy and the cost functions can be learned entirely from data, alleviating tedious hand-designing of costs.
DESIRE: Distant Future Prediction in Dynamic Scenes with Interacting Agents
Apr 14, 2017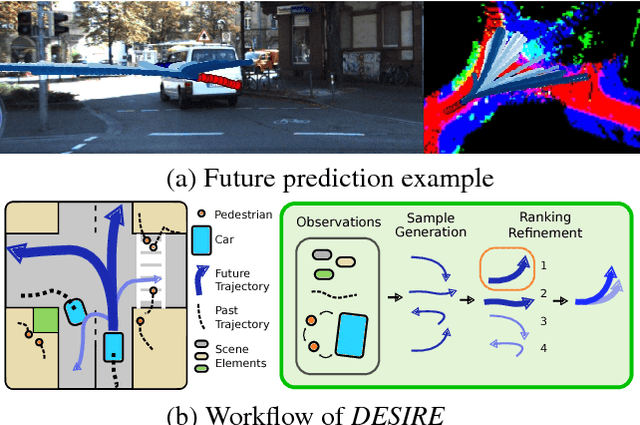
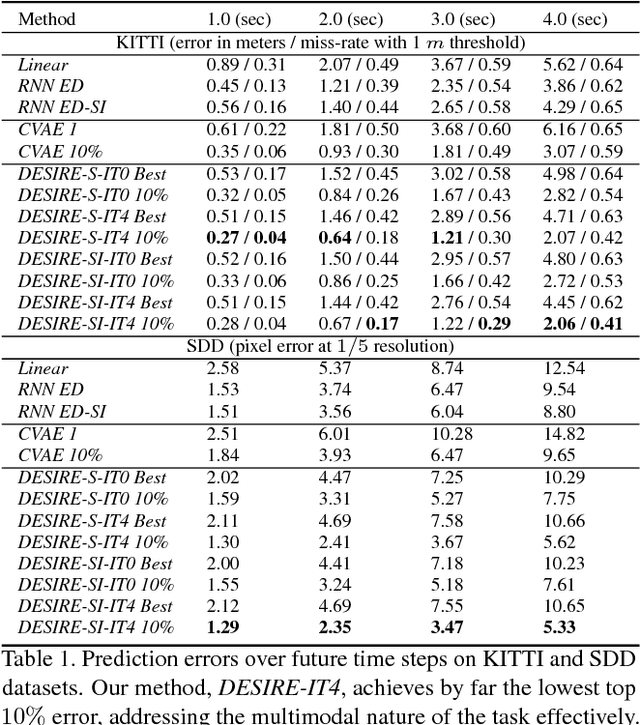

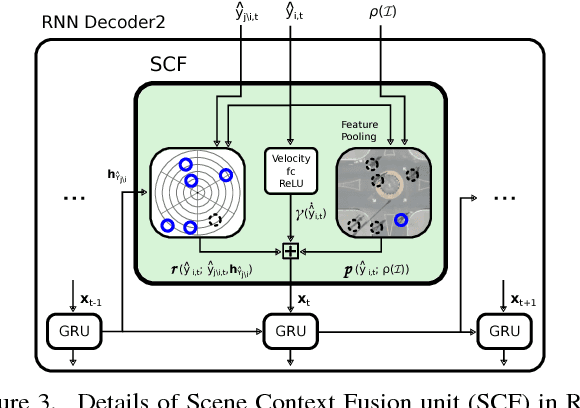
We introduce a Deep Stochastic IOC RNN Encoderdecoder framework, DESIRE, for the task of future predictions of multiple interacting agents in dynamic scenes. DESIRE effectively predicts future locations of objects in multiple scenes by 1) accounting for the multi-modal nature of the future prediction (i.e., given the same context, future may vary), 2) foreseeing the potential future outcomes and make a strategic prediction based on that, and 3) reasoning not only from the past motion history, but also from the scene context as well as the interactions among the agents. DESIRE achieves these in a single end-to-end trainable neural network model, while being computationally efficient. The model first obtains a diverse set of hypothetical future prediction samples employing a conditional variational autoencoder, which are ranked and refined by the following RNN scoring-regression module. Samples are scored by accounting for accumulated future rewards, which enables better long-term strategic decisions similar to IOC frameworks. An RNN scene context fusion module jointly captures past motion histories, the semantic scene context and interactions among multiple agents. A feedback mechanism iterates over the ranking and refinement to further boost the prediction accuracy. We evaluate our model on two publicly available datasets: KITTI and Stanford Drone Dataset. Our experiments show that the proposed model significantly improves the prediction accuracy compared to other baseline methods.
Variational reaction-diffusion systems for semantic segmentation
Apr 01, 2016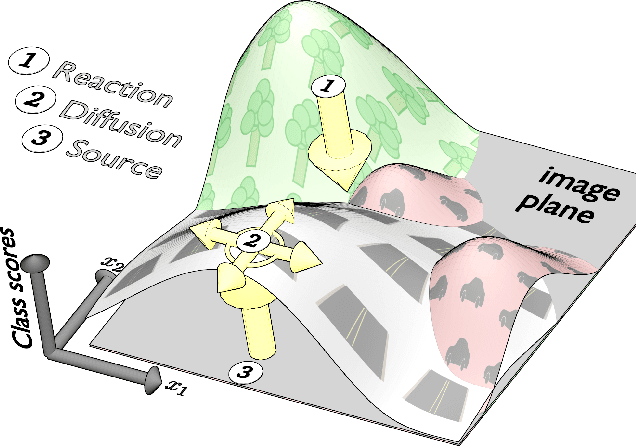
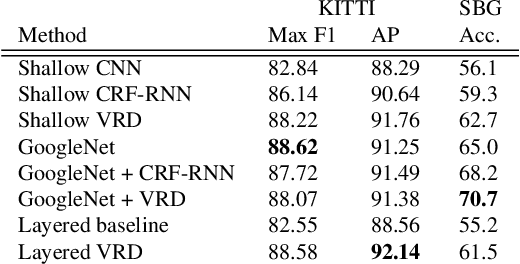
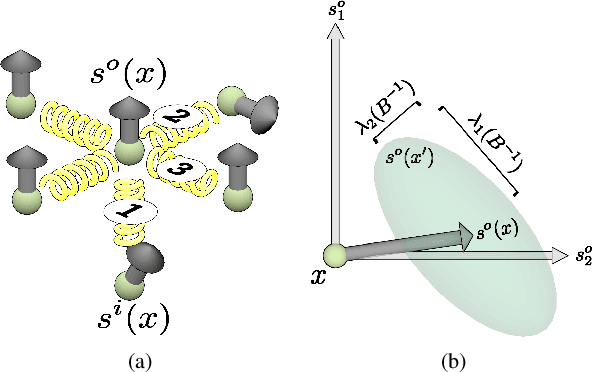
A novel global energy model for multi-class semantic image segmentation is proposed that admits very efficient exact inference and derivative calculations for learning. Inference in this model is equivalent to MAP inference in a particular kind of vector-valued Gaussian Markov random field, and ultimately reduces to solving a linear system of linear PDEs known as a reaction-diffusion system. Solving this system can be achieved in time scaling near-linearly in the number of image pixels by reducing it to sequential FFTs, after a linear change of basis. The efficiency and differentiability of the model make it especially well-suited for integration with convolutional neural networks, even allowing it to be used in interior, feature-generating layers and stacked multiple times. Experimental results are shown demonstrating that the model can be employed profitably in conjunction with different convolutional net architectures, and that doing so compares favorably to joint training of a fully-connected CRF with a convolutional net.