 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Shape: Generating Shapes from Natural Language by Learning Joint Embeddings
Mar 22, 2018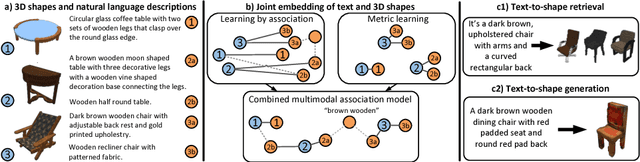



We present a method for generating colored 3D shapes from natural language. To this end, we first learn joint embeddings of freeform text descriptions and colored 3D shapes. Our model combines and extends learning by association and metric learning approaches to learn implicit cross-modal connections, and produces a joint representation that captures the many-to-many relations between language and physical properties of 3D shapes such as color and shape. To evaluate our approach, we collect a large dataset of natural language descriptions for physical 3D objects in the ShapeNet dataset. With this learned joint embedding we demonstrate text-to-shape retrieval that outperforms baseline approaches. Using our embeddings with a novel conditional Wasserstein GAN framework, we generate colored 3D shapes from text. Our method is the first to connect natural language text with realistic 3D objects exhibiting rich variations in color, texture, and shape detail. See video at https://youtu.be/zraPvRdl13Q
SEGCloud: Semantic Segmentation of 3D Point Clouds
Oct 20, 2017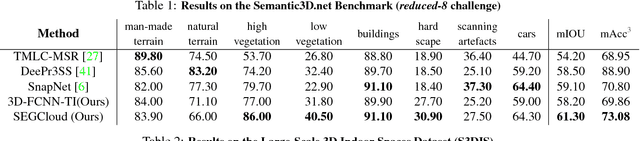
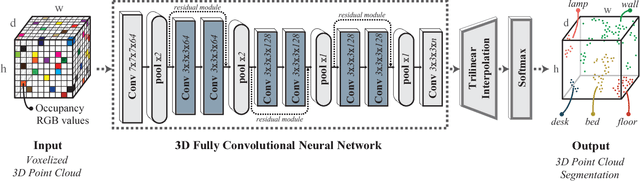
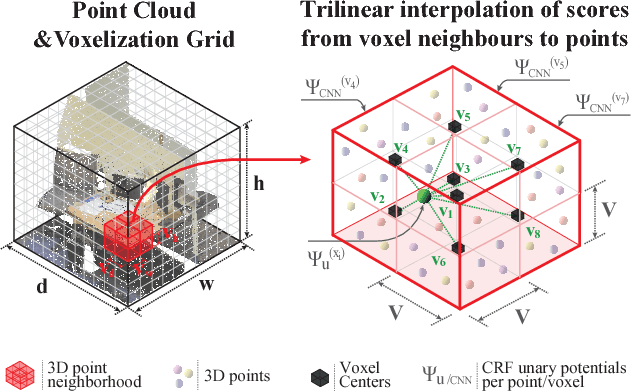

3D semantic scene labeling is fundamental to agents operating in the real world. In particular, labeling raw 3D point sets from sensors provides fine-grained semantics. Recent works leverage the capabilities of Neural Networks (NNs), but are limited to coarse voxel predictions and do not explicitly enforce global consistency. We present SEGCloud, an end-to-end framework to obtain 3D point-level segmentation that combines the advantages of NNs, trilinear interpolation(TI) and fully connected Conditional Random Fields (FC-CRF). Coarse voxel predictions from a 3D Fully Convolutional NN are transferred back to the raw 3D points via trilinear interpolation. Then the FC-CRF enforces global consistency and provides fine-grained semantics on the points. We implement the latter as a differentiable Recurrent NN to allow joint optimization. We evaluate the framework on two indoor and two outdoor 3D datasets (NYU V2, S3DIS, KITTI, Semantic3D.net), and show performance comparable or superior to the state-of-the-art on all datasets.
Weakly supervised 3D Reconstruction with Adversarial Constraint
Oct 04, 2017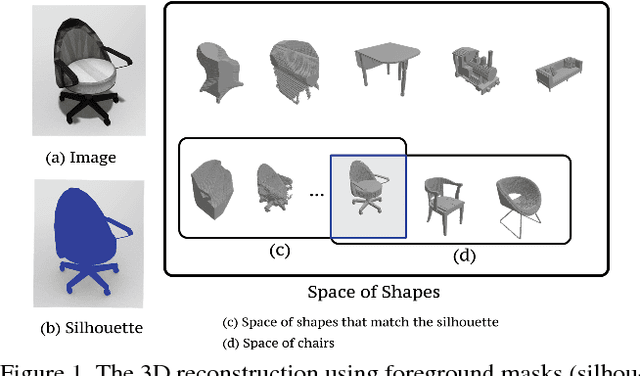
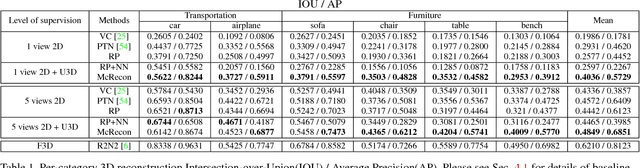
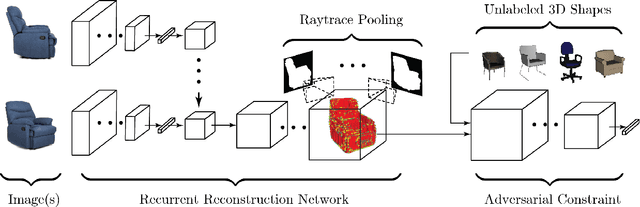

Supervised 3D reconstruction has witnessed a significant progress through the use of deep neural networks. However, this increase in performance requires large scale annotations of 2D/3D data. In this paper, we explore inexpensive 2D supervision as an alternative for expensive 3D CAD annotation. Specifically, we use foreground masks as weak supervision through a raytrace pooling layer that enables perspective projection and backpropagation. Additionally, since the 3D reconstruction from masks is an ill posed problem, we propose to constrain the 3D reconstruction to the manifold of unlabeled realistic 3D shapes that match mask observations. We demonstrate that learning a log-barrier solution to this constrained optimization problem resembles the GAN objective, enabling the use of existing tools for training GANs. We evaluate and analyze the manifold constrained reconstruction on various datasets for single and multi-view reconstruction of both synthetic and real images.
DESIRE: Distant Future Prediction in Dynamic Scenes with Interacting Agents
Apr 14, 2017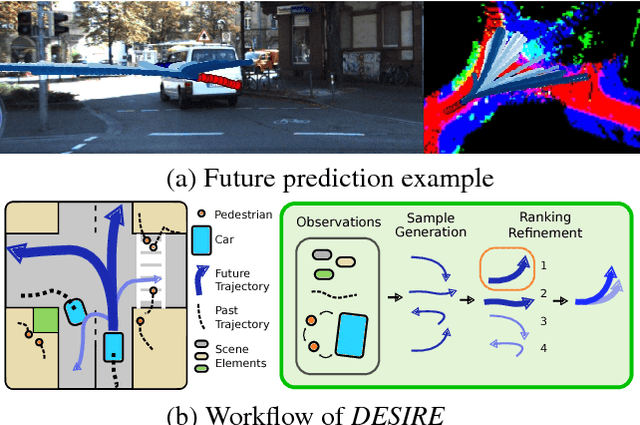
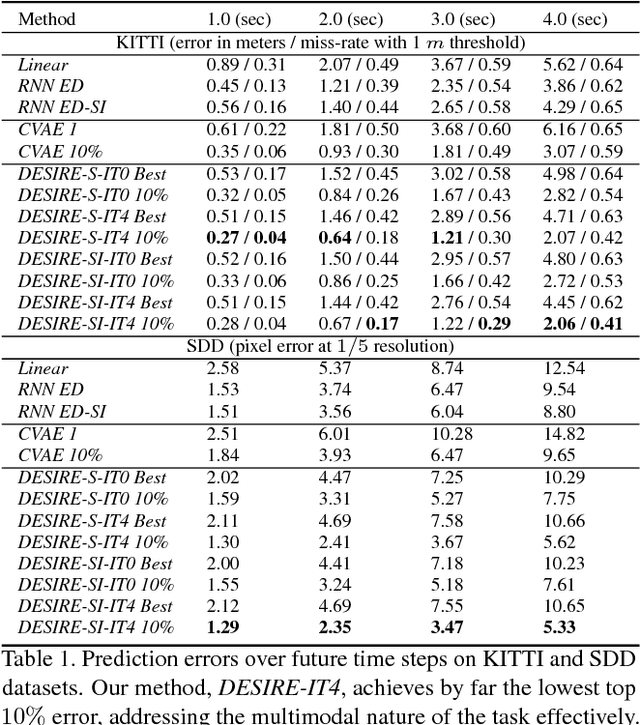

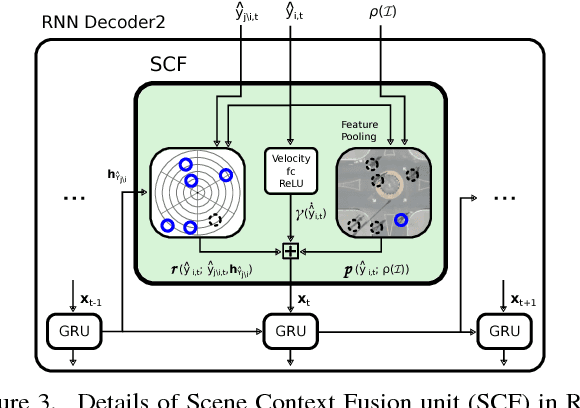
We introduce a Deep Stochastic IOC RNN Encoderdecoder framework, DESIRE, for the task of future predictions of multiple interacting agents in dynamic scenes. DESIRE effectively predicts future locations of objects in multiple scenes by 1) accounting for the multi-modal nature of the future prediction (i.e., given the same context, future may vary), 2) foreseeing the potential future outcomes and make a strategic prediction based on that, and 3) reasoning not only from the past motion history, but also from the scene context as well as the interactions among the agents. DESIRE achieves these in a single end-to-end trainable neural network model, while being computationally efficient. The model first obtains a diverse set of hypothetical future prediction samples employing a conditional variational autoencoder, which are ranked and refined by the following RNN scoring-regression module. Samples are scored by accounting for accumulated future rewards, which enables better long-term strategic decisions similar to IOC frameworks. An RNN scene context fusion module jointly captures past motion histories, the semantic scene context and interactions among multiple agents. A feedback mechanism iterates over the ranking and refinement to further boost the prediction accuracy. We evaluate our model on two publicly available datasets: KITTI and Stanford Drone Dataset. Our experiments show that the proposed model significantly improves the prediction accuracy compared to other baseline methods.
Scene Graph Generation by Iterative Message Passing
Apr 12, 2017
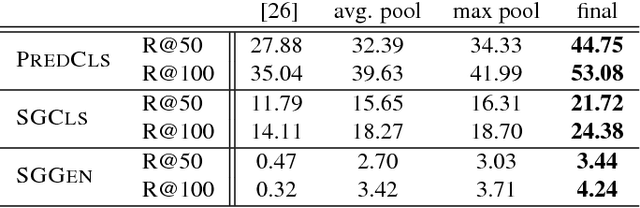
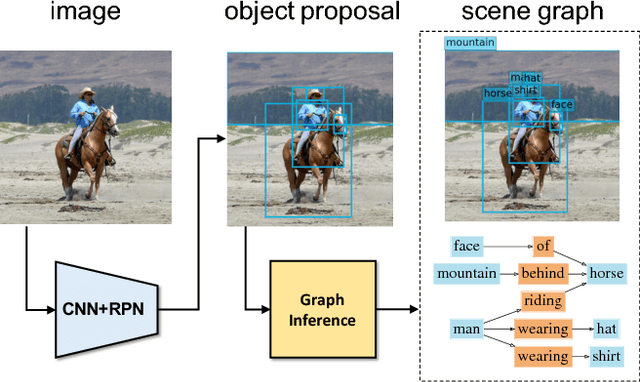
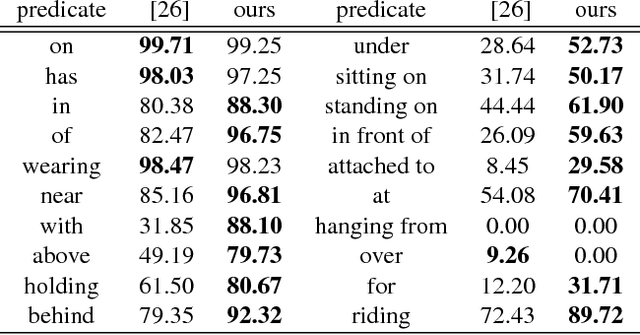
Understanding a visual scene goes beyond recognizing individual objects in isolation. Relationships between objects also constitute rich semantic information about the scene. In this work, we explicitly model the objects and their relationships using scene graphs, a visually-grounded graphical structure of an image. We propose a novel end-to-end model that generates such structured scene representation from an input image. The model solves the scene graph inference problem using standard RNNs and learns to iteratively improves its predictions via message passing. Our joint inference model can take advantage of contextual cues to make better predictions on objects and their relationships. The experiments show that our model significantly outperforms previous methods for generating scene graphs using Visual Genome dataset and inferring support relations with NYU Depth v2 dataset.
Universal Correspondence Network
Oct 31, 2016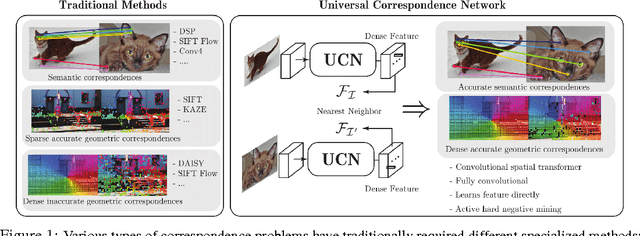

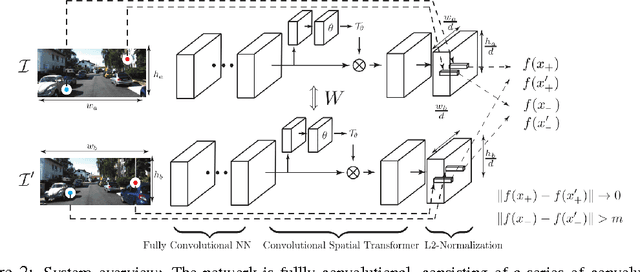
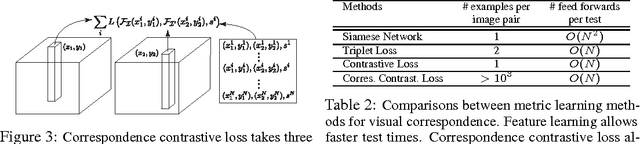
We present a deep learning framework for accurate visual correspondences and demonstrate its effectiveness for both geometric and semantic matching, spanning across rigid motions to intra-class shape or appearance variations. In contrast to previous CNN-based approaches that optimize a surrogate patch similarity objective, we use deep metric learning to directly learn a feature space that preserves either geometric or semantic similarity. Our fully convolutional architecture, along with a novel correspondence contrastive loss allows faster training by effective reuse of computations, accurate gradient computation through the use of thousands of examples per image pair and faster testing with $O(n)$ feed forward passes for $n$ keypoints, instead of $O(n^2)$ for typical patch similarity methods. We propose a convolutional spatial transformer to mimic patch normalization in traditional features like SIFT, which is shown to dramatically boost accuracy for semantic correspondences across intra-class shape variations. Extensive experiments on KITTI, PASCAL, and CUB-2011 datasets demonstrate the significant advantages of our features over prior works that use either hand-constructed or learned features.
3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction
Apr 02, 2016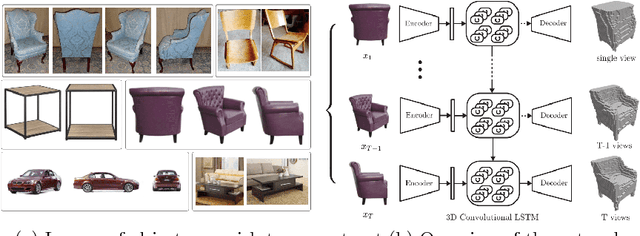
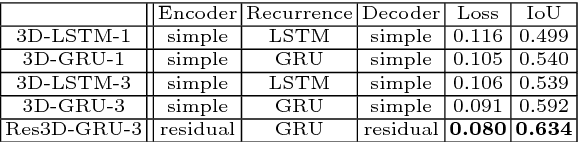
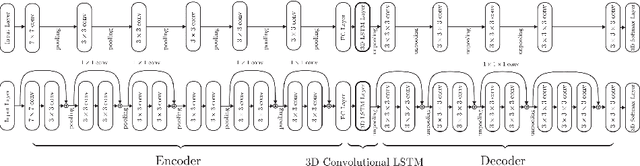

Inspired by the recent success of methods that employ shape priors to achieve robust 3D reconstructions, we propose a novel recurrent neural network architecture that we call the 3D Recurrent Reconstruction Neural Network (3D-R2N2). The network learns a mapping from images of objects to their underlying 3D shapes from a large collection of synthetic data. Our network takes in one or more images of an object instance from arbitrary viewpoints and outputs a reconstruction of the object in the form of a 3D occupancy grid. Unlike most of the previous works, our network does not require any image annotations or object class labels for training or testing. Our extensive experimental analysis shows that our reconstruction framework i) outperforms the state-of-the-art methods for single view reconstruction, and ii) enables the 3D reconstruction of objects in situations when traditional SFM/SLAM methods fail (because of lack of texture and/or wide baseline).