 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinkowski Tracker: A Sparse Spatio-Temporal R-CNN for Joint Object Detection and Tracking
Aug 26, 2022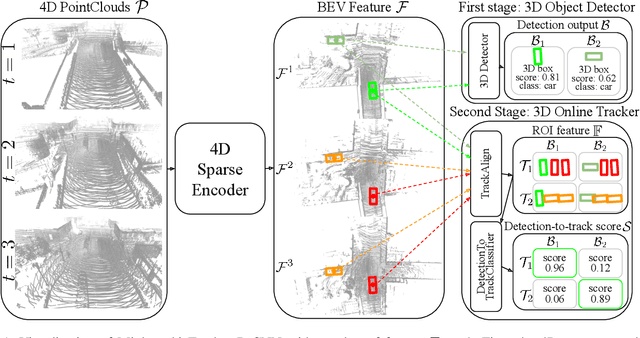
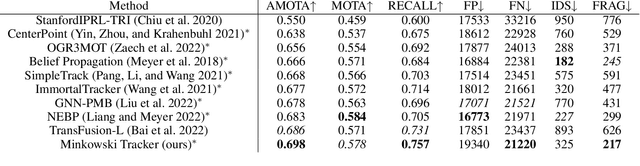
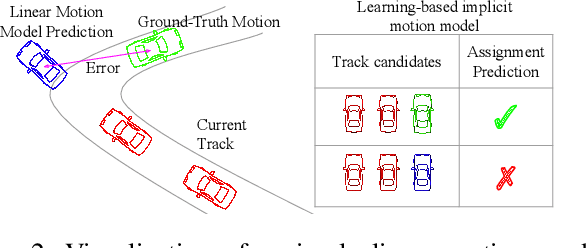
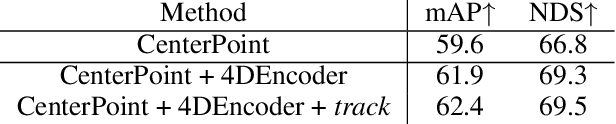
Recent research in multi-task learning reveals the benefit of solving related problems in a single neural network. 3D object detection and multi-object tracking (MOT) are two heavily intertwined problems predicting and associating an object instance location across time. However, most previous works in 3D MOT treat the detector as a preceding separated pipeline, disjointly taking the output of the detector as an input to the tracker. In this work, we present Minkowski Tracker, a sparse spatio-temporal R-CNN that jointly solves object detection and tracking. Inspired by region-based CNN (R-CNN), we propose to solve tracking as a second stage of the object detector R-CNN that predicts assignment probability to tracks. First, Minkowski Tracker takes 4D point clouds as input to generate a spatio-temporal Bird's-eye-view (BEV) feature map through a 4D sparse convolutional encoder network. Then, our proposed TrackAlign aggregates the track region-of-interest (ROI) features from the BEV features. Finally, Minkowski Tracker updates the track and its confidence score based on the detection-to-track match probability predicted from the ROI features. We show in large-scale experiments that the overall performance gain of our method is due to four factors: 1. The temporal reasoning of the 4D encoder improves the detection performance 2. The multi-task learning of object detection and MOT jointly enhances each other 3. The detection-to-track match score learns implicit motion model to enhance track assignment 4. The detection-to-track match score improves the quality of the track confidence score. As a result, Minkowski Tracker achieved the state-of-the-art performance on Nuscenes dataset tracking task without hand-designed motion models.
Generative Sparse Detection Networks for 3D Single-shot Object Detection
Jun 22, 2020
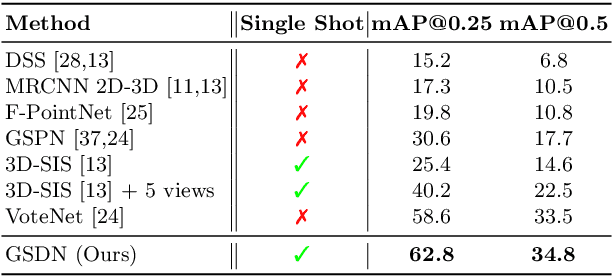
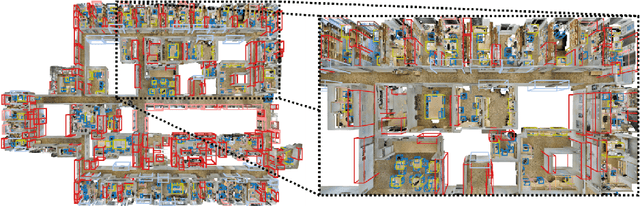

3D object detection has been widely studied due to its potential applicability to many promising areas such as robotics and augmented reality. Yet, the sparse nature of the 3D data poses unique challenges to this task. Most notably, the observable surface of the 3D point clouds is disjoint from the center of the instance to ground the bounding box prediction on. To this end, we propose Generative Sparse Detection Network (GSDN), a fully-convolutional single-shot sparse detection network that efficiently generates the support for object proposals. The key component of our model is a generative sparse tensor decoder, which uses a series of transposed convolutions and pruning layers to expand the support of sparse tensors while discarding unlikely object centers to maintain minimal runtime and memory footprint. GSDN can process unprecedentedly large-scale inputs with a single fully-convolutional feed-forward pass, thus does not require the heuristic post-processing stage that stitches results from sliding windows as other previous methods have. We validate our approach on three 3D indoor datasets including the large-scale 3D indoor reconstruction dataset where our method outperforms the state-of-the-art methods by a relative improvement of 7.14% while being 3.78 times faster than the best prior work.
JRMOT: A Real-Time 3D Multi-Object Tracker and a New Large-Scale Dataset
Mar 18, 2020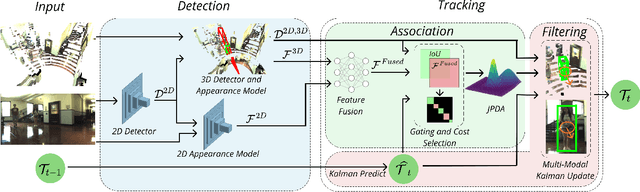
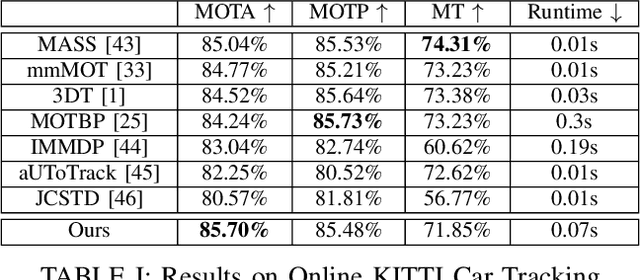
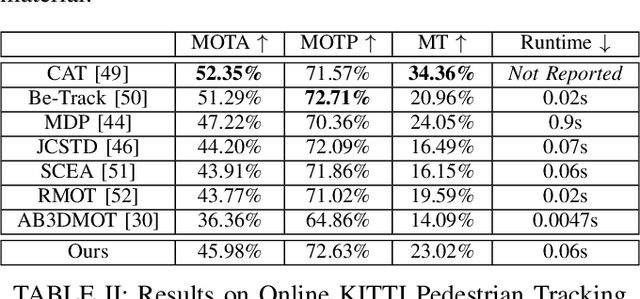
An autonomous navigating agent needs to perceive and track the motion of objects and other agents in its surroundings to achieve robust and safe motion planning and execution. While autonomous navigation requires a multi-object tracking (MOT) system to provide 3D information, most research has been done in 2D MOT from RGB videos. In this work we present JRMOT, a novel 3D MOT system that integrates information from 2D RGB images and 3D point clouds into a real-time performing framework. Our system leverages advancements in neural-network based re-identification as well as 2D and 3D detection and descriptors. We incorporate this into a joint probabilistic data-association framework within a multi-modal recursive Kalman architecture to achieve online, real-time 3D MOT. As part of our work, we release the JRDB dataset, a novel large scale 2D+3D dataset and benchmark annotated with over 2 million boxes and 3500 time consistent 2D+3D trajectories across 54 indoor and outdoor scenes. The dataset contains over 60 minutes of data including 360 degree cylindrical RGB video and 3D pointclouds. The presented 3D MOT system demonstrates state-of-the-art performance against competing methods on the popular 2D tracking KITTI benchmark and serves as a competitive 3D tracking baseline for our dataset and benchmark.
JRDB: A Dataset and Benchmark for Visual Perception for Navigation in Human Environments
Oct 25, 2019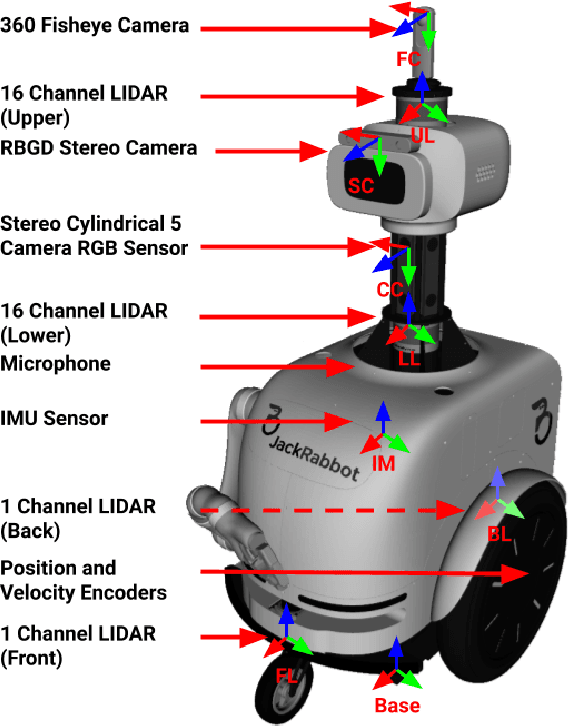
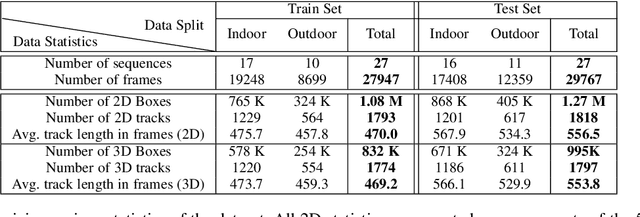
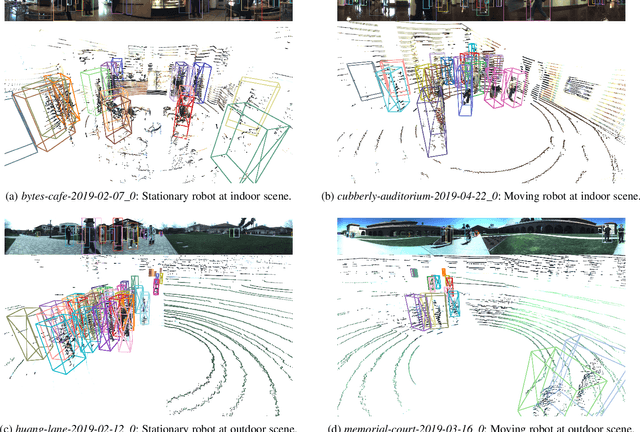
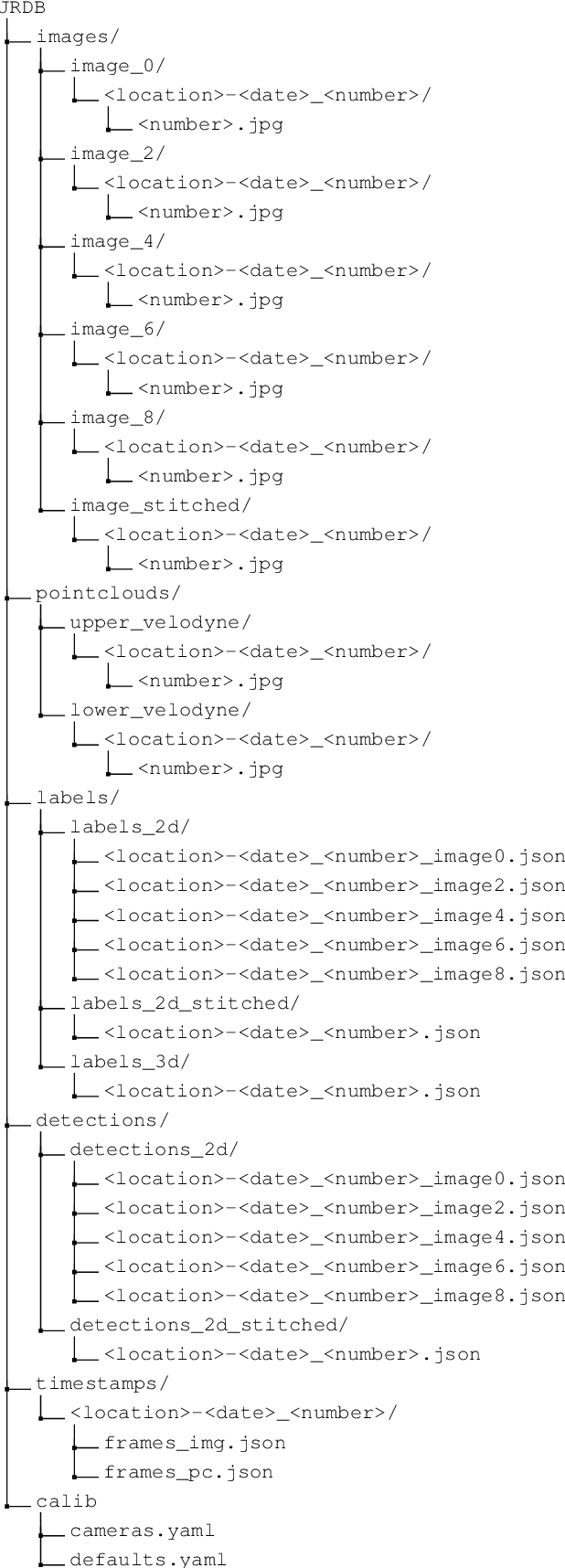
We present JRDB, a novel dataset collected from our social mobile manipulator JackRabbot. The dataset includes 64 minutes of multimodal sensor data including stereo cylindrical 360$^\circ$ RGB video at 15 fps, 3D point clouds from two Velodyne 16 Lidars, line 3D point clouds from two Sick Lidars, audio signal, RGBD video at 30 fps, 360$^\circ$ spherical image from a fisheye camera and encoder values from the robot's wheels. Our dataset includes data from traditionally underrepresented scenes such as indoor environments and pedestrian areas, from both stationary and navigating robot platform. The dataset has been annotated with over 2.3 million bounding boxes spread over 5 individual cameras and 1.8 million associated 3D cuboids around all people in the scenes totalling over 3500 time consistent trajectories. Together with our dataset and the annotations, we launch a benchmark and metrics for 2D and 3D person detection and tracking. With this dataset, that we plan on further annotating in the future, we hope to provide a new source of data and a test-bench for research in the areas of robot autonomous navigation and all perceptual tasks around social robotics in human environments.
3D Scene Graph: A Structure for Unified Semantics, 3D Space, and Camera
Oct 06, 2019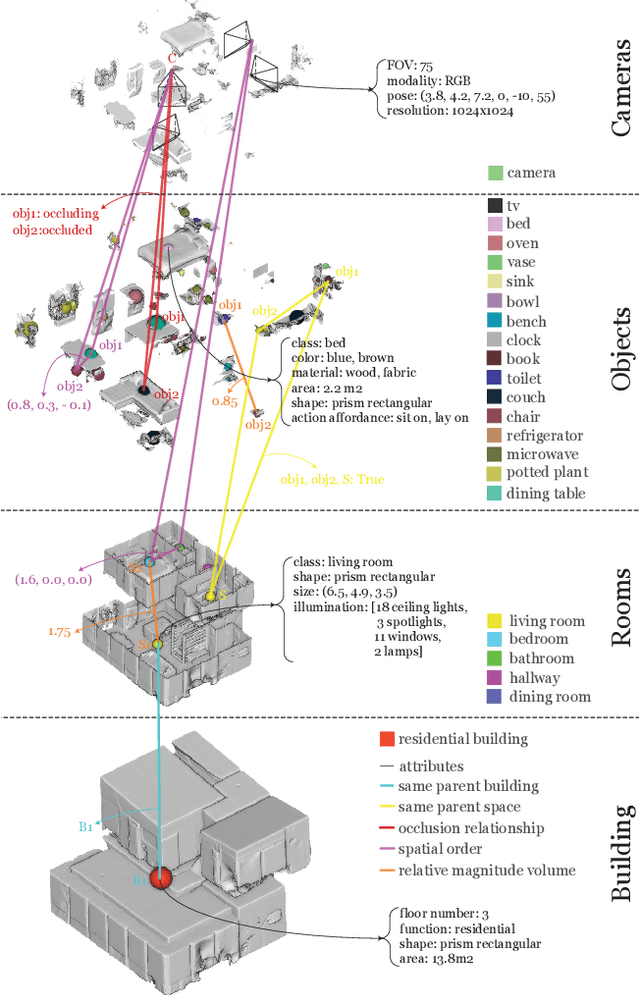

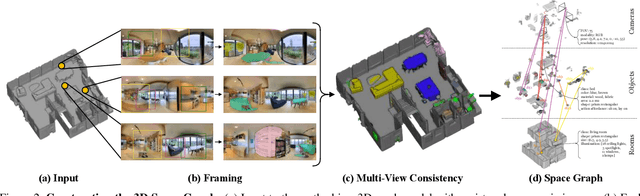
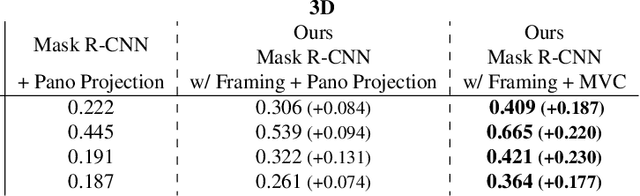
A comprehensive semantic understanding of a scene is important for many applications - but in what space should diverse semantic information (e.g., objects, scene categories, material types, texture, etc.) be grounded and what should be its structure? Aspiring to have one unified structure that hosts diverse types of semantics, we follow the Scene Graph paradigm in 3D, generating a 3D Scene Graph. Given a 3D mesh and registered panoramic images, we construct a graph that spans the entire building and includes semantics on objects (e.g., class, material, and other attributes), rooms (e.g., scene category, volume, etc.) and cameras (e.g., location, etc.), as well as the relationships among these entities. However, this process is prohibitively labor heavy if done manually. To alleviate this we devise a semi-automatic framework that employs existing detection methods and enhances them using two main constraints: I. framing of query images sampled on panoramas to maximize the performance of 2D detectors, and II. multi-view consistency enforcement across 2D detections that originate in different camera locations.
4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks
May 15, 2019

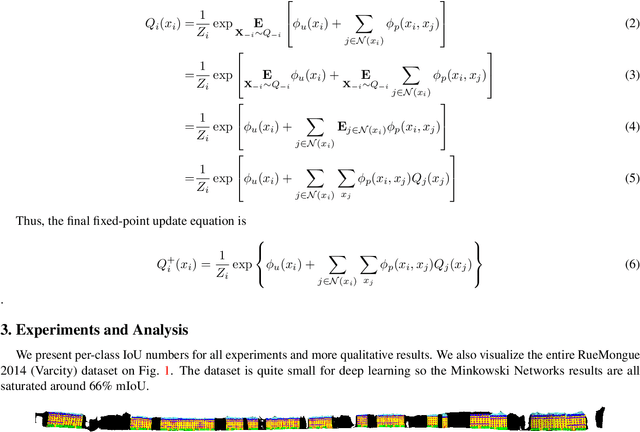
In many robotics and VR/AR applications, 3D-videos are readily-available sources of input (a continuous sequence of depth images, or LIDAR scans). However, those 3D-videos are processed frame-by-frame either through 2D convnets or 3D perception algorithms. In this work, we propose 4-dimensional convolutional neural networks for spatio-temporal perception that can directly process such 3D-videos using high-dimensional convolutions. For this, we adopt sparse tensors and propose the generalized sparse convolution that encompasses all discrete convolutions. To implement the generalized sparse convolution, we create an open-source auto-differentiation library for sparse tensors that provides extensive functions for high-dimensional convolutional neural networks. We create 4D spatio-temporal convolutional neural networks using the library and validate them on various 3D semantic segmentation benchmarks and proposed 4D datasets for 3D-video perception. To overcome challenges in the 4D space, we propose the hybrid kernel, a special case of the generalized sparse convolution, and the trilateral-stationary conditional random field that enforces spatio-temporal consistency in the 7D space-time-chroma space. Experimentally, we show that convolutional neural networks with only generalized 3D sparse convolutions can outperform 2D or 2D-3D hybrid methods by a large margin. Also, we show that on 3D-videos, 4D spatio-temporal convolutional neural networks are robust to noise, outperform 3D convolutional neural networks and are faster than the 3D counterpart in some cases.
Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
Apr 15, 2019



Intersection over Union (IoU) is the most popular evaluation metric used in the object detection benchmarks. However, there is a gap between optimizing the commonly used distance losses for regressing the parameters of a bounding box and maximizing this metric value. The optimal objective for a metric is the metric itself. In the case of axis-aligned 2D bounding boxes, it can be shown that $IoU$ can be directly used as a regression loss. However, $IoU$ has a plateau making it infeasible to optimize in the case of non-overlapping bounding boxes. In this paper, we address the weaknesses of $IoU$ by introducing a generalized version as both a new loss and a new metric. By incorporating this generalized $IoU$ ($GIoU$) as a loss into the state-of-the art object detection frameworks, we show a consistent improvement on their performance using both the standard, $IoU$ based, and new, $GIoU$ based, performance measures on popular object detection benchmarks such as PASCAL VOC and MS COCO.
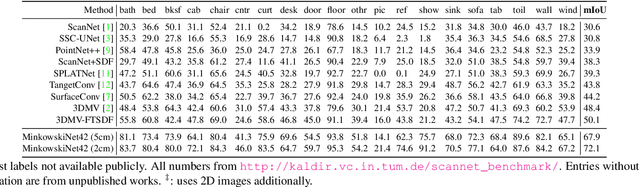
SEGCloud: Semantic Segmentation of 3D Point Clouds
Oct 20, 2017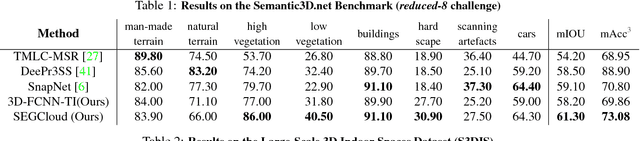
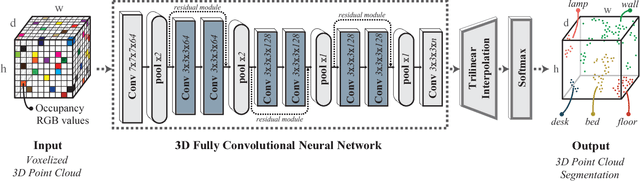
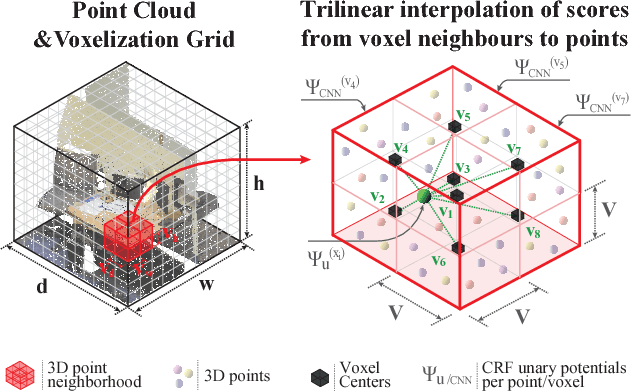

3D semantic scene labeling is fundamental to agents operating in the real world. In particular, labeling raw 3D point sets from sensors provides fine-grained semantics. Recent works leverage the capabilities of Neural Networks (NNs), but are limited to coarse voxel predictions and do not explicitly enforce global consistency. We present SEGCloud, an end-to-end framework to obtain 3D point-level segmentation that combines the advantages of NNs, trilinear interpolation(TI) and fully connected Conditional Random Fields (FC-CRF). Coarse voxel predictions from a 3D Fully Convolutional NN are transferred back to the raw 3D points via trilinear interpolation. Then the FC-CRF enforces global consistency and provides fine-grained semantics on the points. We implement the latter as a differentiable Recurrent NN to allow joint optimization. We evaluate the framework on two indoor and two outdoor 3D datasets (NYU V2, S3DIS, KITTI, Semantic3D.net), and show performance comparable or superior to the state-of-the-art on all datasets.
Weakly supervised 3D Reconstruction with Adversarial Constraint
Oct 04, 2017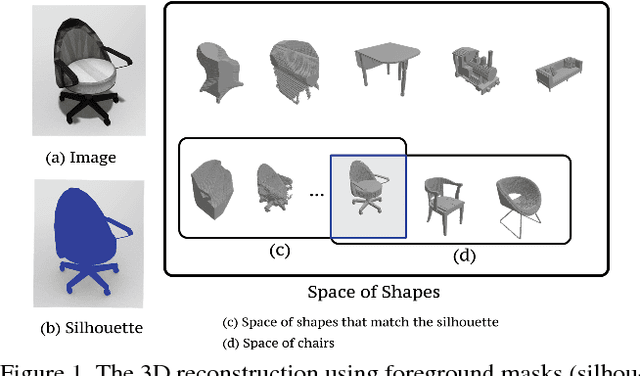
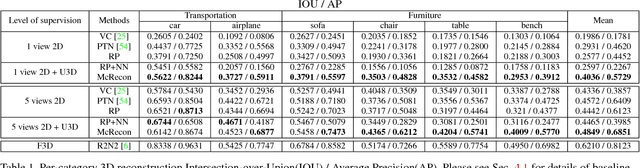
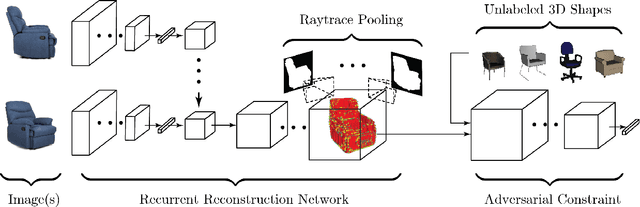

Supervised 3D reconstruction has witnessed a significant progress through the use of deep neural networks. However, this increase in performance requires large scale annotations of 2D/3D data. In this paper, we explore inexpensive 2D supervision as an alternative for expensive 3D CAD annotation. Specifically, we use foreground masks as weak supervision through a raytrace pooling layer that enables perspective projection and backpropagation. Additionally, since the 3D reconstruction from masks is an ill posed problem, we propose to constrain the 3D reconstruction to the manifold of unlabeled realistic 3D shapes that match mask observations. We demonstrate that learning a log-barrier solution to this constrained optimization problem resembles the GAN objective, enabling the use of existing tools for training GANs. We evaluate and analyze the manifold constrained reconstruction on various datasets for single and multi-view reconstruction of both synthetic and real images.
DeformNet: Free-Form Deformation Network for 3D Shape Reconstruction from a Single Image
Aug 11, 2017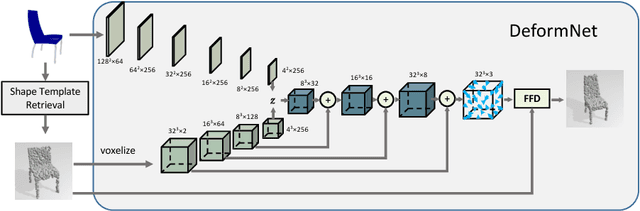


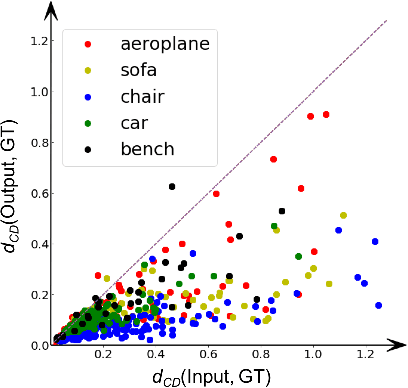
3D reconstruction from a single image is a key problem in multiple applications ranging from robotic manipulation to augmented reality. Prior methods have tackled this problem through generative models which predict 3D reconstructions as voxels or point clouds. However, these methods can be computationally expensive and miss fine details. We introduce a new differentiable layer for 3D data deformation and use it in DeformNet to learn a model for 3D reconstruction-through-deformation. DeformNet takes an image input, searches the nearest shape template from a database, and deforms the template to match the query image. We evaluate our approach on the ShapeNet dataset and show that - (a) the Free-Form Deformation layer is a powerful new building block for Deep Learning models that manipulate 3D data (b) DeformNet uses this FFD layer combined with shape retrieval for smooth and detail-preserving 3D reconstruction of qualitatively plausible point clouds with respect to a single query image (c) compared to other state-of-the-art 3D reconstruction methods, DeformNet quantitatively matches or outperforms their benchmarks by significant margins. For more information, visit: https://deformnet-site.github.io/DeformNet-website/ .